
Discover 4 articles about Computer Vision conduct by our Research Lab Team
YOLO: A real-time object detection algorithm for multiple objects in an image in a single pass
YOLO: Simplifying Object Detection
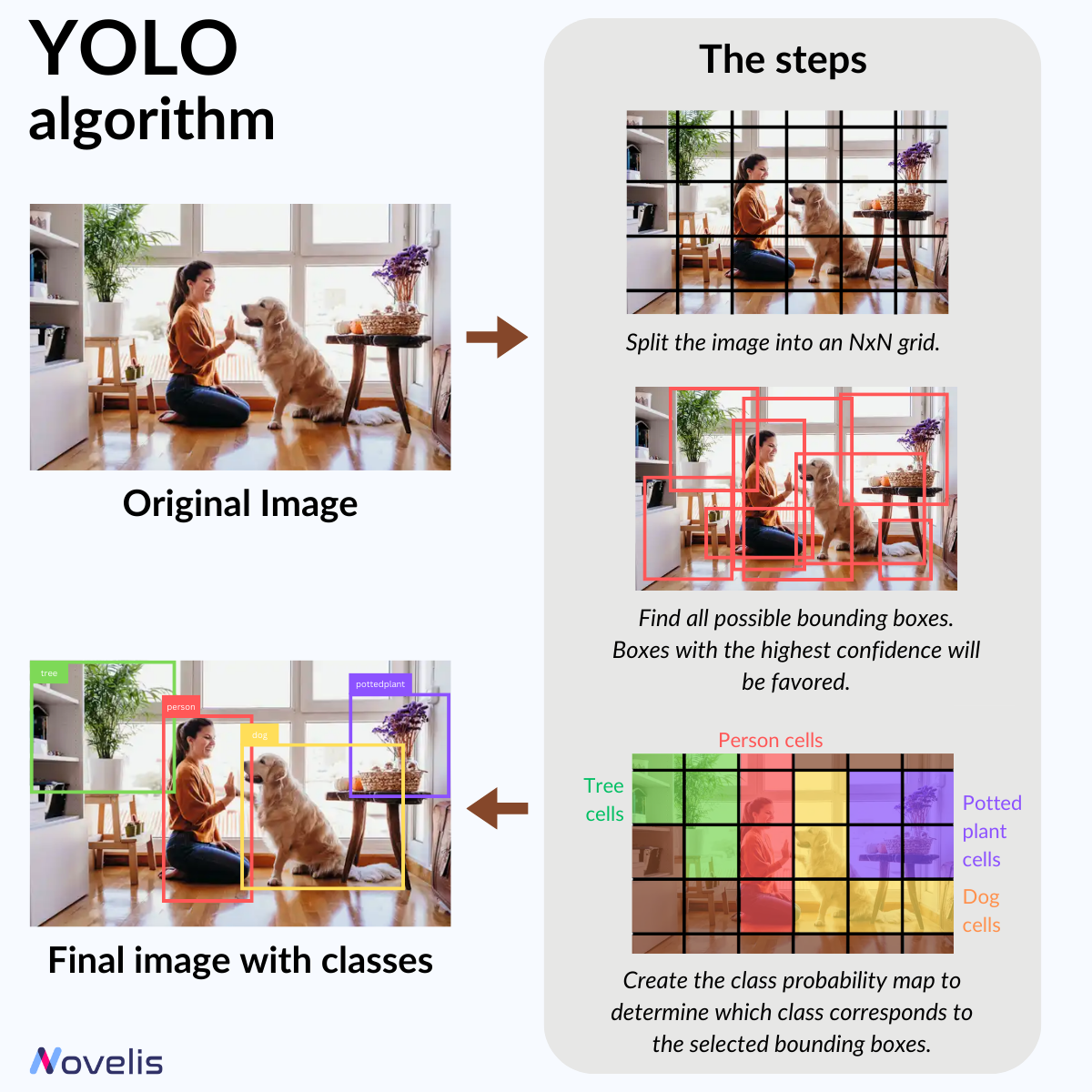
YOLO (You Only Look Once) is a state-of-the-art real-time object detection technique in computer vision. It uses a neural network for fast object detection. YOLO divides an image into bounding boxes to capture objects of different sizes. Then, it predicts each box’s object class (is it a dog? a cat? a plant?). How? By learning a class probability map to determine the object class associated with those boxes.
Think of YOLO this way: it works by capturing essential image features, refining them, and pinpointing potential object locations. It learns patterns to identify objects in input images through training on labeled examples. During the prediction process, it analyzes an image just once, quickly detects objects, and removes duplicates along the way.
The latest iteration of YOLO is the v8, by Ultralytics, but the v5 still holds its ground.
Why is this essential? It’s like teaching a computer to instantly spot things! YOLO excels in speed and accuracy, perfect for tasks like robotics or self-driving cars.
OCR and IDP: A technology that converts printed text into machine-readable text
The Magic of Optical Character Recognition
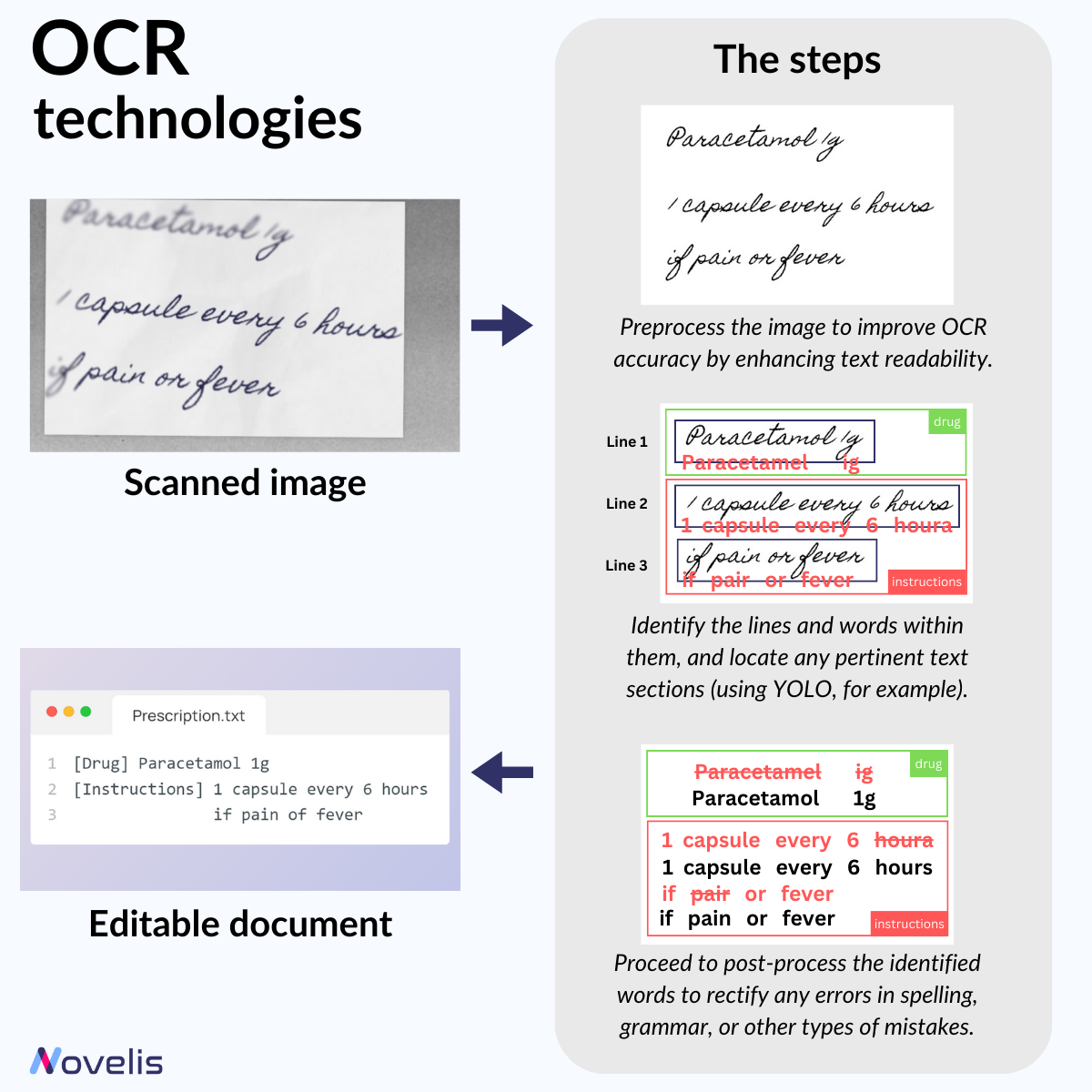
Have you ever wondered how Intelligent Document Processing (IDP) works? It involves, among other things, converting scanned or handwritten text into editable and searchable text. This process is made possible thanks to Optical Character Recognition (OCR) technologies. In our ongoing series on computer vision tasks (check out our previous post on YOLO), we’ll closely examine OCR and how it works.
When converting an image into text, OCR goes through several steps. First is the pre-processing phase, where the image is cleaned and enhanced to make the text more readable. Next, we move on to the actual character recognition process. Earlier OCR methods identified individual characters or words and compared them to known patterns to extract information. However, most modern OCR methods use neural networks trained to automatically recognize complete lines of text instead of individual characters. The last phase is post-processing, primarily to do error correction. Object Detection methods, like YOLO, can also be used to recognize relevant fields and text regions in documents.
Tesseract is the leading commercial-grade OCR software due to its high customizability and support for numerous languages. Other algorithms, such as the “OCR-free” DONUT, are gaining popularity.
Why is this essential? OCR technologies enable businesses to accelerate their workflows and individuals to access information effortlessly. It drives innovation and revolutionizes healthcare, finance, education, and legal services.
DINOv2: A vision Transformer model that produces universal features suitable for image-level visual tasks
DINOv2: The Next Revolution in Computer Vision?
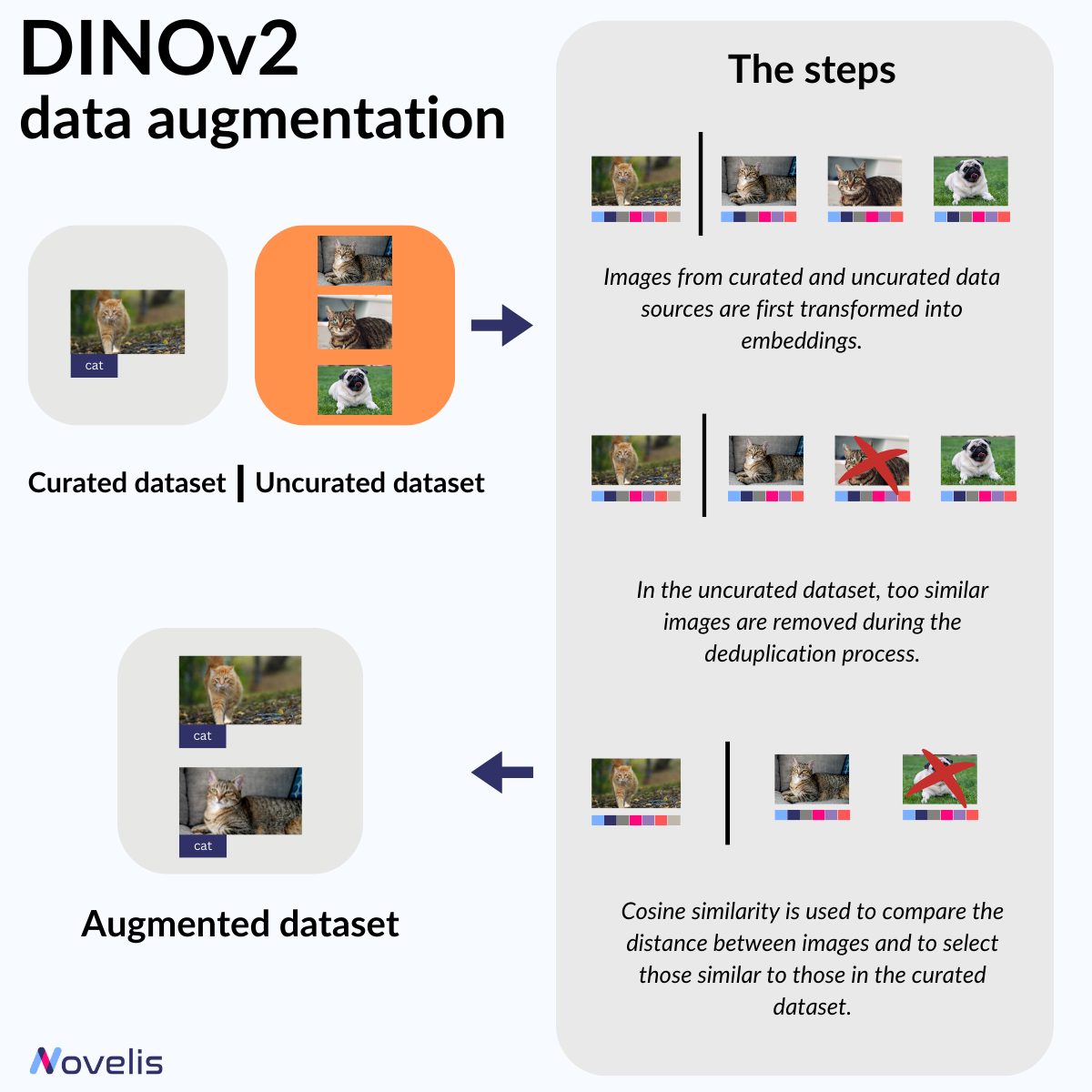
The field of computer vision is constantly evolving. In our previous posts, we have discussed various methods used in computer vision. However, these approaches often require a large amount of labeled images to achieve good results. Meta Research’s DINOv2 (short for “self-DIstillation with NO labels”) is an innovative computer vision model that utilizes self-supervised learning to remove the need for image labeling.
Simply put, DINOv2 operates without manually labeling each image, a typically time-consuming process. While the model architecture itself is interesting (it follows the masked modeling method that’s very popular in NLP), the data curation process makes DINOv2 such an exciting piece of technology. It first uses embeddings to compare images from a small curated dataset with images from a larger uncurated dataset, then removing similar images from the uncurated dataset to avoid redundancy. Then, it uses cosine similarity to identify and select images similar to those in the curated dataset to label and augment the curated one.
The latest version of DINOv2 was introduced by Meta Research in April 2023. It can be used in various visual applications, both for image and video, including depth estimation, semantic segmentation, and instance retrieval.
Why is this essential? With DINOv2, you can save time by avoiding the tedious and time-consuming task of manually labeling images. This powerful model makes creating precise and adaptable computer vision pipelines easy. It is particularly useful for specialized industries such as medical or industrial, where obtaining labeled data can be costly and challenging.
Efficient ViT: A high-speed vision model for efficient high-resolution dense prediction vision tasks
Accelerated Attention for High-Resolution Semantic Segmentation
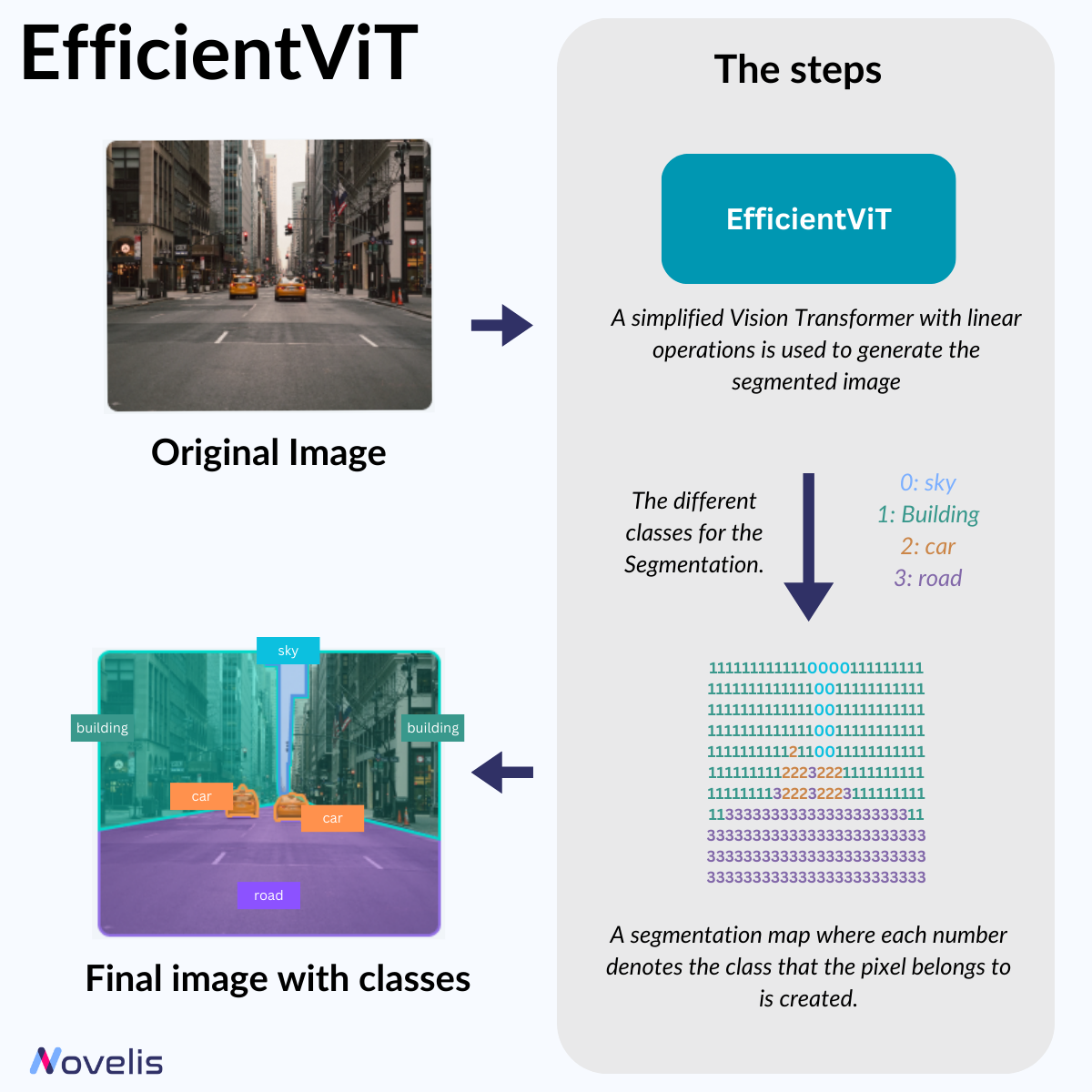
When it comes to real-time computer vision, like with self-driving cars, recognizing objects quickly and accurately is crucial. This is achieved through semantic segmentation, which analyzes high-resolution images of the surroundings. However, this method requires a lot of processing power. To make it work on devices with limited hardware, a group of scientists from MIT have developed a computer vision model that drastically reduces computational complexity.
EfficientViT is a new vision transformer that simplifies building an attention map. To do this, the researchers made two changes. First, they replaced the nonlinear similarity function with a linear one. Second, they changed the order of operations to reduce the number of calculations needed while maintaining functionality. Two elements accomplish this: the first captures local feature interactions, and the second helps detect small and large objects. The simplified Vision Transformer with linear operations generates the segmented image. The output is a segmentation map where each number denotes the class the pixel belongs to, effectively tagging the input image with the correct labels.
This work is primarily done for academic purposes. However the MIT-IBM Watson AI Lab and other organizations have made their work publicly available in 2022 on their GitHub, and updates are continuously being added.
Why is this important? Reducing computational complexity is necessary for real-time image segmentation on small devices like smartphones or onboard systems with limited computing power.
