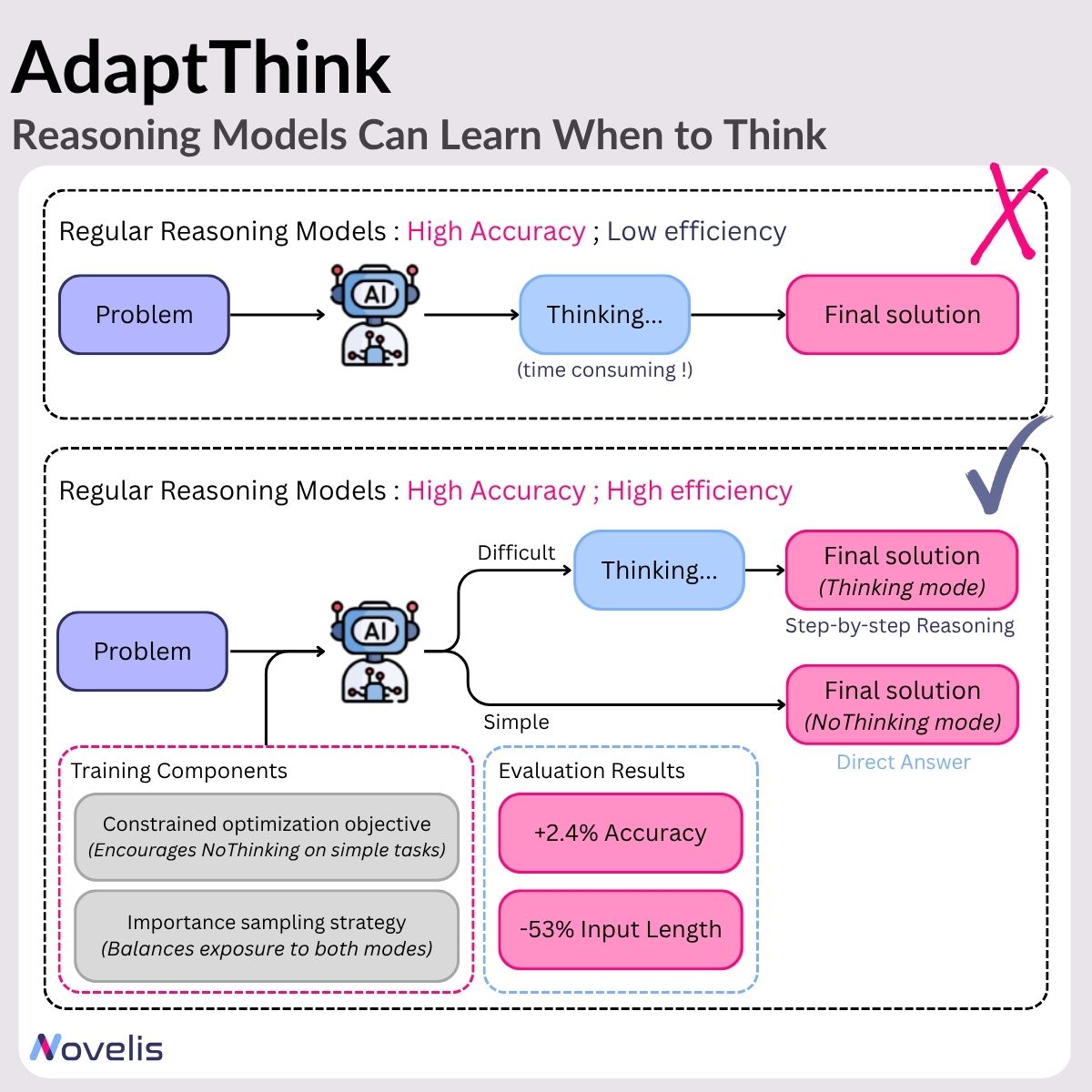
Large reasoning models (LRMs) have shown remarkable performance by generating detailed intermediate steps before reaching an answer (a process often described as “thinking”). While this improves results on complex tasks, it also incurs significant computational overhead, particularly for simpler problems where such extensive reasoning is unnecessary. Put simply, tend to overthink even easy problems, wasting time and tokens on unnecessary reasoning.
AdaptThink is a reinforcement learning–based framework that teaches LRMs to dynamically select between two reasoning modes based on the difficulty of the problem:
Thinking Mode: Engages in step-by-step reasoning ;
NoThinking Mode: Bypasses intermediate steps and outputs the answer directly.
The framework is built on two key components:
- Constrained optimization objective, which encourages the model to favor the NoThinking mode for easier tasks, while preserving overall accuracy ;
- Importance sampling strategy, which ensures balanced exposure to both reasoning modes during training, and promotes effective learning and exploration.
The authors evaluated AdaptThink on three mathematical reasoning datasets using the DeepSeek-R1-Distill-Qwen-1.5B model. The main results are two-fold :
- Efficiency gains, with reduced average output length by 53%, cutting down on unnecessary reasoning
- Performance gains, with improved accuracy by 2.4%, showing that increased efficiency did not compromise correctness.
These results suggest that AdaptThink can effectively manage the trade-off between depth of reasoning and computational efficiency.
However, there are some limitations to keep in mind. So far, the framework has only been evaluated on mathematical problems, so it’s unclear how well it would generalize to other types of tasks, and because AdaptThink relies on reinforcement learning, the training process is technically more complex and resource-intensive than standard approaches.
Further readings :
- AdaptThink: Reasoning Models Can Learn When to Think : https://arxiv.org/abs/2505.13417
- Thinkless: LLM Learns When to Think : https://arxiv.org/abs/2505.13379