
Discover the application of AI for efficiently utilizing data from temporal series forecasts.
CHRONOS – Foundation Model for Time Series Forecasting

Time series forecasting is crucial for decision-making in various areas, such as retail, energy, finance, healthcare, and climate science. Let’s talk about how AI can be leveraged to effectively harness such crucial data.
The emergence of deep learning techniques has challenged traditional statistical models that dominated time series forecasting. These techniques have mainly been made possible by the availability of extensive time series data. However, despite the impressive performance of deep learning models, there is still a need for a general-purpose “foundation” forecasting model in the field.
Recent efforts have explored using large language models (LLMs) with zero-shot learning capabilities for time series forecasting. These approaches prompt pretrained LLMs directly or fine-tune them for time series tasks. However, they all require task-specific adjustments or computationally expensive models.
With Chronos, presented in the new paper “Chronos: Learning the Language of Time Series“, the team at Amazon takes a novel approach by treating time series as a language and tokenizing them into discrete bins. This allows off-the-shelf language models to be trained on the “language of time series” without altering the traditional language model architecture.
Pretrained Chronos models, ranging from 20M to 710M parameters, are based on the T5 family and trained on a diverse dataset collection. Additionally, data augmentation strategies address the scarcity of publicly available high-quality time series datasets. Chronos is now the state-of-the-art in-domain and zero-shot forecasting model, outperforming traditional models and task-specific deep learning approaches.
Why is this essential? As a language model operating over a fixed vocabulary, Chronos integrates with future advancements in LLMs, positioning it as an ideal candidate for further development as a generalist time series model.
Multivariate Time Series – A Transformer-Based Framework for Multivariate Time Series Representation Learning
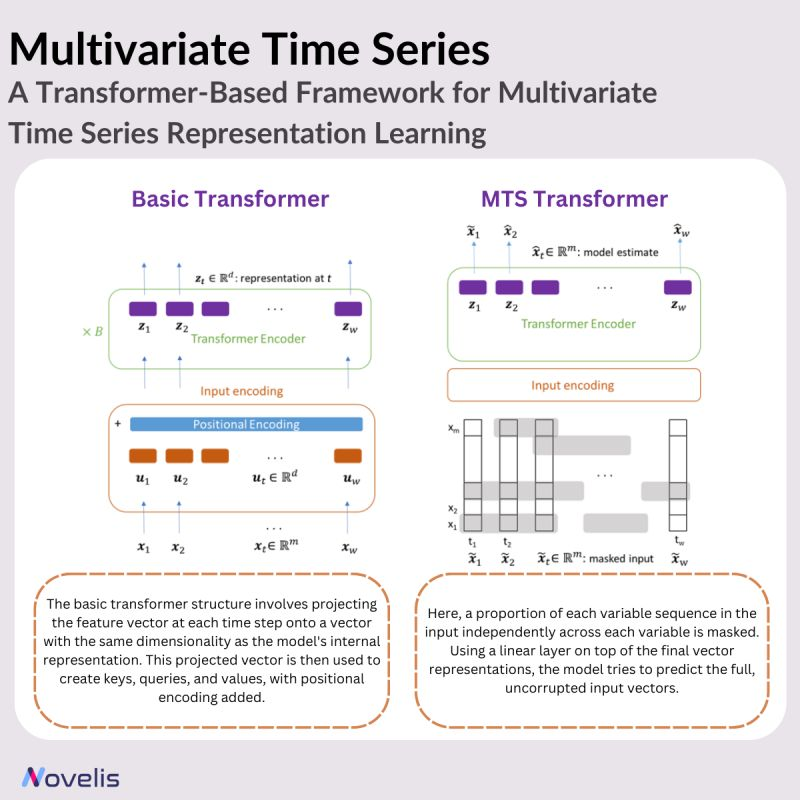
Multivariate time series (MTS) data is common in various fields, including science, medicine, finance, engineering, and industrial applications. It tracks multiple variables simultaneously over time. Despite the abundance of MTS data, labeled data for training models remains scarce. Today’s post presents a transformer-based framework for unsupervised representation learning of multivariate time series by providing an overview of a research paper titled “A Transformer-Based Framework for Multivariate Time Series Representation Learning,” authored by a team from IBM and Brown University. Pre-trained models generated from this framework can be applied to various downstream tasks, such as regression, classification, forecasting, and missing value imputation.
The method works as follows: the main idea of the proposed approach is to use a transformer encoder. The transformer model is adapted from the traditional transformer to process sequences of feature vectors that represent multivariate time series instead of sequences of discrete word indices. Positional encodings are incorporated to ensure the model understands the sequential nature of time series data. In an unsupervised pre-training fashion, the model is trained to predict masked values as part of an autoregressive denoising task where some input is hidden.
Namely, they mask a proportion of each variable sequence in the input independently across each variable. Using a linear layer on top of the final vector representations, the model tries to predict the full, uncorrupted input vectors. This unsupervised pre-training approach leverages the same labeled data samples, and in some cases, it demonstrates performance improvements even when compared to the fully supervised methods. Like any transformer architecture, the pre-trained can be used for regression and classification tasks by adding output layers.
The paper introduces an interesting approach to using transformer-based models for effective representation learning in multivariate time series data. When evaluated on various benchmark datasets, it shows improvements over existing methods and outperforms them in multivariate time series regression and classification. The framework demonstrates superior performance even with limited training samples while maintaining computational efficiency.
