Andrej Karpathy : « Le logiciel change (encore une fois) »
Dans sa conférence intitulée « Software Is Changing (Again) », Andrej Karpathy explique comment les modèles de langage (LLMs) transforment profondément la manière dont nous concevons, utilisons et pensons les logiciels. Il décrit l’évolution des paradigmes de programmation, les opportunités offertes par les applications à autonomie partielle, et les implications pour les développeurs, les entreprises et les technologues.

Dans cet article, nous allons décomposer les idées clés de la présentation de Karpathy : comment le logiciel est entré dans sa troisième grande phase d’évolution, pourquoi les modèles de langage doivent être compris comme des systèmes d’exploitation complexes, quelles nouvelles opportunités ils ouvrent pour le développement d’applications, et ce que cela implique de concevoir des systèmes pour des agents intelligents dans ce nouveau paysage.
TL’évolution du logiciel : du code traditionnel aux prompts
Karpathy identifie trois grandes phases dans l’histoire du logiciel :
- Software 1.0 : Code traditionnel écrit par des humains (ex. : C++, Python, Java), avec une logique explicitement programmée.
- Software 2.0 : Réseaux de neurones, où la logique émerge des données d’entraînement plutôt que de règles écrites à la main.
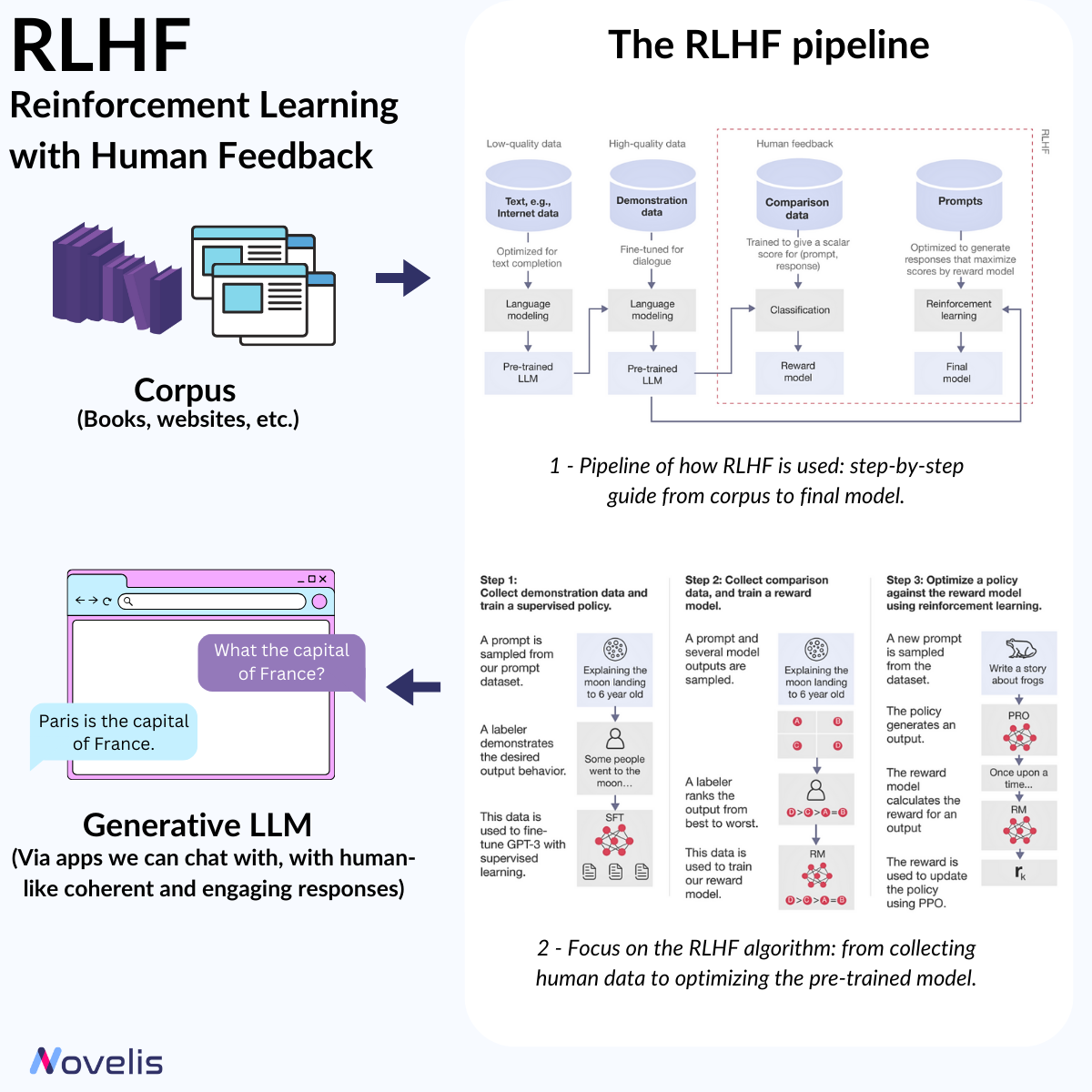
- Software 3.0 : Systèmes pilotés par LLMs où des instructions en langage naturel (anglais, français, arabe, etc.) jouent le rôle de code. Programmer signifie désormais influencer le comportement d’un modèle via des prompts bien formulés.
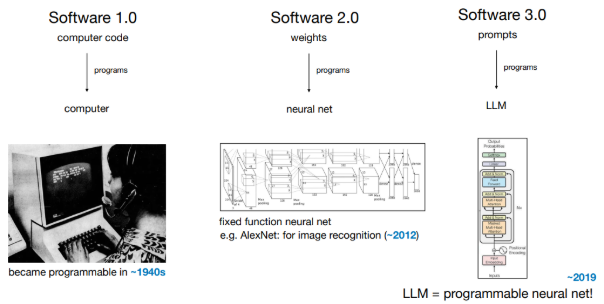
Les développeurs doivent maîtriser ces trois paradigmes, chacun ayant ses atouts et ses limites.
Exemple : pour une tâche de classification de sentiments, chaque paradigme propose une approche différente, avec ses propres compromis.

Les LLMs : le nouveau système d’exploitation
Karpathy propose de voir les LLMs comme des systèmes d’exploitation pour l’intelligence :
- On assiste à une dualité entre modèles propriétaires (GPT, Gemini) et modèles open source (LLaMA), comme lors des premières « guerres » entre systèmes (Windows/macOS vs. Linux).
- Le modèle agit comme un processeur, tandis que la fenêtre de contexte joue le rôle de mémoire temporaire, avec des ressources limitées.
- Comme dans les années 1960, la puissance de calcul est centralisée dans le cloud. Les utilisateurs sont des clients « légers ». L’idée d’un LLM personnel reste à concrétiser.
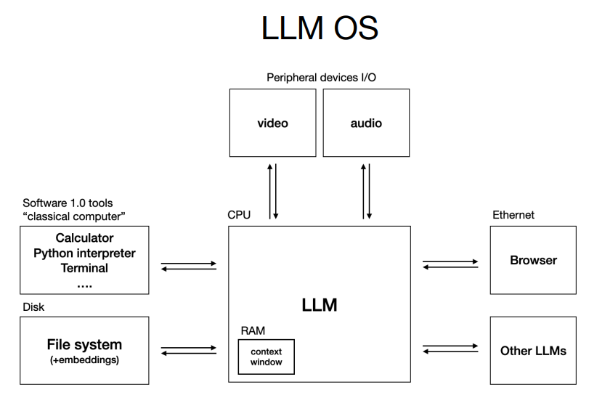
Aujourd’hui, interagir avec un LLM ressemble à utiliser un terminal avant l’invention de l’interface graphique : puissant mais brut. L’ »interface révolutionnaire » des LLMs reste à inventer.

Psychologie des LLMs : surhumains mais imparfaits
Selon Karpathy, les LLMs sont des simulations stochastiques d’humains, capables d’exploits mais avec des faiblesses spécifiques :
- Super-pouvoirs : Connaissance encyclopédique et mémoire immense issue des données d’entraînement.
- Déficits cognitifs : Hallucinations, incapacité à apprendre durablement, erreurs incohérentes (intelligence en dents de scie).
- Vulnérabilités : Susceptibles d’être manipulés via des prompts malveillants, fuites de données.
La clé pour les exploiter efficacement : intégrer l’humain dans la boucle, pour tirer parti de leurs forces tout en limitant leurs failles.
L’opportunité : construire des applications à autonomie partielle
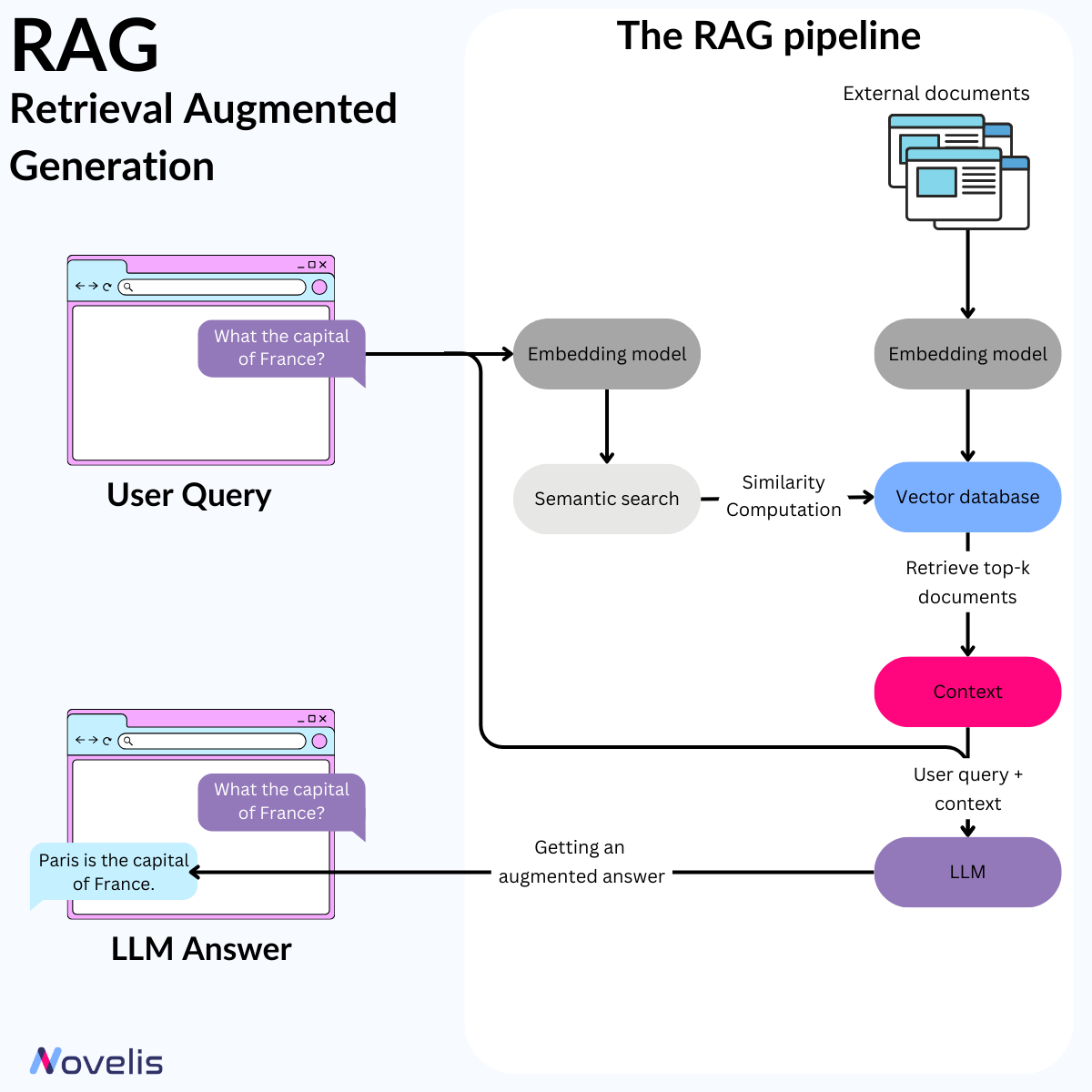
L’interaction directe avec les LLMs cédera la place à des applications dédiées qui pilotent leur comportement.
Exemples :
- Cursor (assistant de codage IA)
- Perplexity (moteur de recherche basé sur LLM)
Ces outils orchestrent plusieurs modèles, gèrent le contexte, et offrent des interfaces pensées pour l’usage. Les meilleures applications laissent l’utilisateur ajuster le niveau d’autonomie de l’IA — de simples suggestions jusqu’à des changements majeurs dans un dépôt de code.
Les interfaces doivent accélérer le cycle génération IA ↔ validation humaine, avec des outils visuels pour auditer les réponses.
Karpathy déconseille de viser l’autonomie totale : il faut privilégier des étapes progressives, contrôlables et vérifiables.
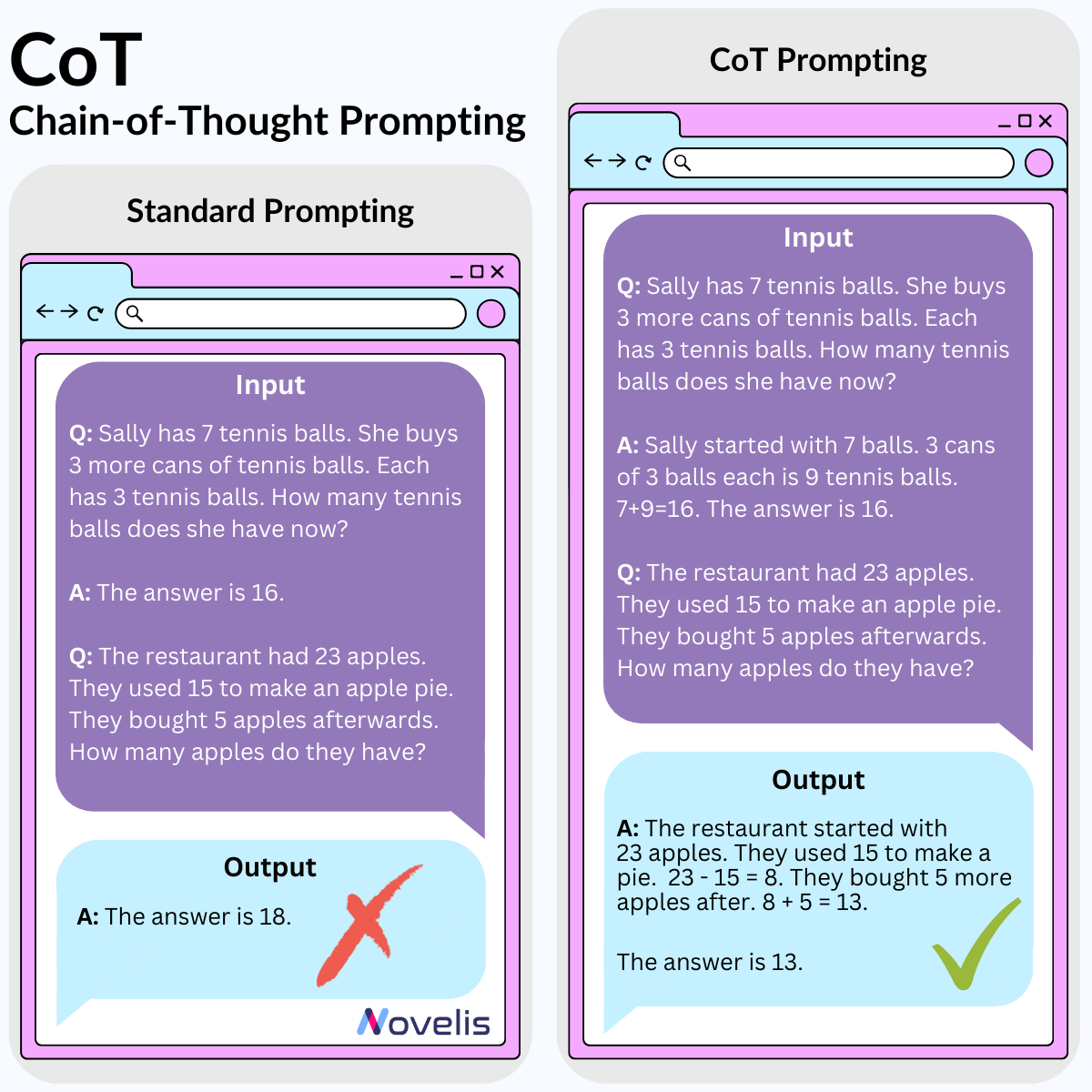
Programmation en langage naturel & “Vibe Coding”
Dans le monde Software 3.0, tout le monde peut devenir programmeur :
- Langage naturel = code : maîtriser l’anglais (ou une autre langue) suffit à piloter un LLM.
- Vibe coding : nom donné par Karpathy au fait de créer des applis utiles, sans expertise poussée, en « jouant » avec les prompts. Une porte d’entrée vers la programmation sérieuse.
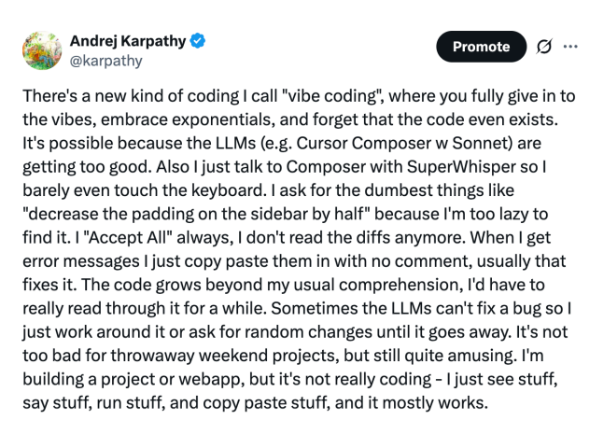
Mais il note un décalage : si générer du code devient facile, le déploiement réel (authentification, paiements, mise en production) reste manuel et fastidieux. Un terrain à fort potentiel d’automatisation.
Construire pour les agents : le prochain chantier
Pour exploiter pleinement les agents IA, il faut adapter nos infrastructures numériques :
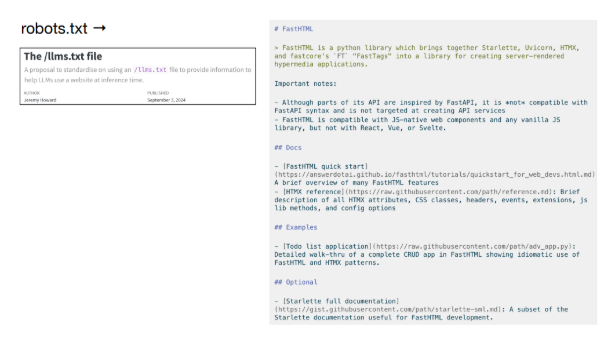
- Normes web pour LLMs : comme
robots.txt, Karpathy imagine unllms.txtou des fichiers markdown dédiés aux LLMs. - Données structurées pour agents : aller au-delà des documents pour humains (« cliquez ici ») vers des instructions lisibles par machine (ex. : commandes
curl, API). - Outils d’ingestion de code : comme get-ingest ou DeepWiki, ils rendent les bases de code lisibles par les LLMs, rendant les agents plus intelligents.
L’avenir combinera des agents plus performants et un web plus accessible pour eux.
La décennie des agents : ce qui nous attend
Karpathy conclut avec une vision réaliste : 2025 ne sera pas l’année des agents, mais les années 2020 seront leur décennie.
Il prône un design “Iron Man” : des IA qui amplifient l’humain, avec une autonomie ajustable. Le succès viendra de la coopération étroite entre humains et IA, étape par étape, plutôt que d’une autonomie totale prématurée.
Conclusion
Le logiciel évolue rapidement et profondément. Avec les LLMs comme nouvelle plateforme programmable, les barrières à la création de logiciels tombent. Mais la vérification, le déploiement et la gestion de l’autonomie deviennent plus complexes.
La conférence de Karpathy invite à construire des outils, des infrastructures et des applications centrés sur l’équilibre entre puissance de l’IA et supervision humaine — cœur d’une transformation logicielle déjà en cours.