Malgré les capacités impressionnantes des grands modèles de langage (LLM), ces derniers peuvent parfois générer avec assurance des informations inexactes, un phénomène connu sous le nom d’« hallucination ». Ce problème représente un défi majeur pour l’IA Générative, en particulier lorsqu’il s’agit de données numériques et statistiques. Ces données posent des défis spécifiques :
- Complexité des opérations statistiques : L’entraînement des modèles sur des requêtes liées à des informations statistiques implique souvent des opérations logiques, arithmétiques ou de comparaison, avec des niveaux de complexité variés.
- Formats variés et contexte nécessaire : Les données statistiques publiques existent dans des formats et des schémas divers, nécessitant fréquemment une interprétation basée sur un contexte précis. Cela rend leur utilisation particulièrement difficile pour les systèmes utilisant la génération augmentée par récupération (RAG).
DataGemma : une solution innovante
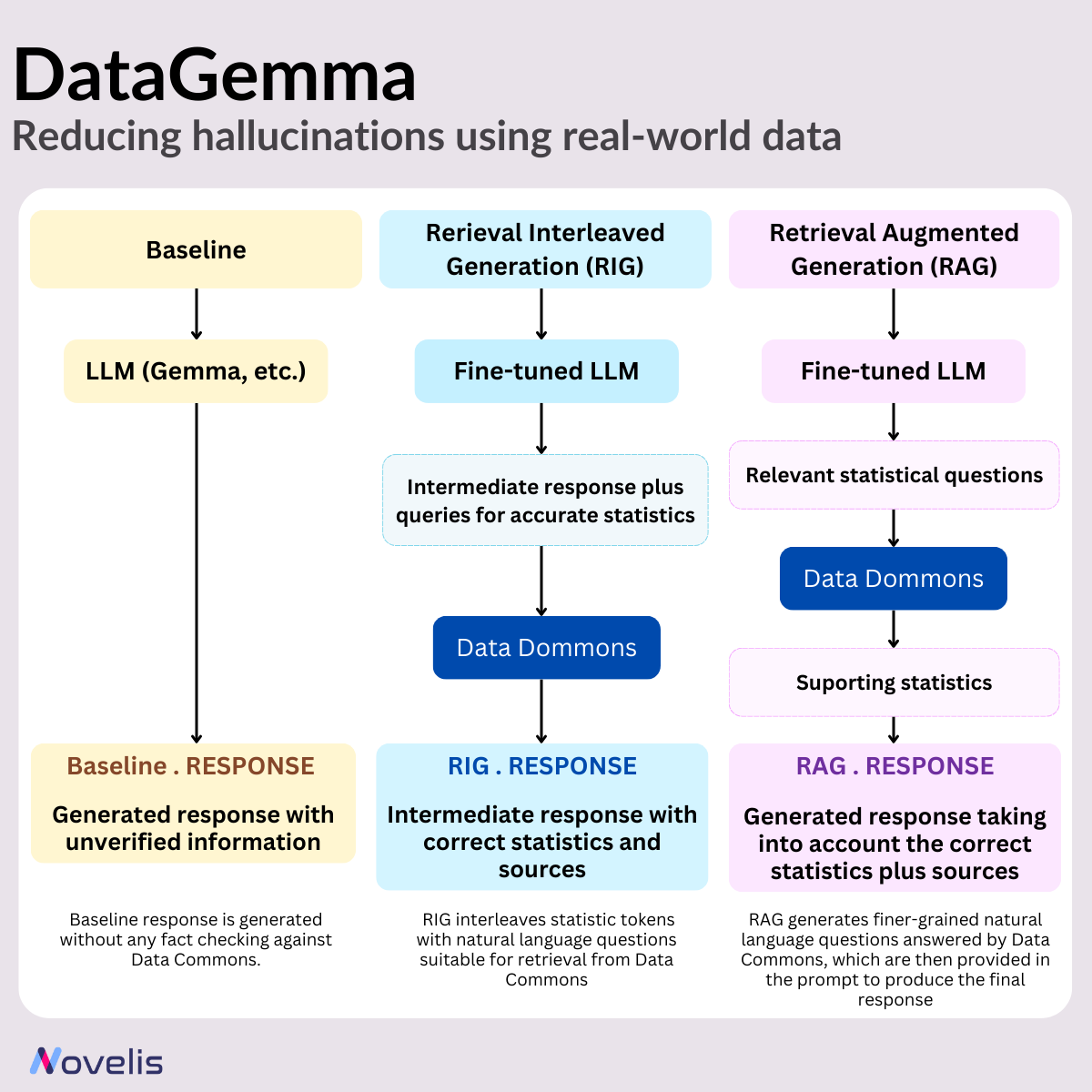
Des chercheurs de Google ont développé DataGemma, un outil qui connecte les LLM à Data Commons — un vaste référentiel unifié de données statistiques publiques — afin de relever ces défis. Deux approches distinctes sont utilisées : RIG (Retrieval-Interleaved Generation) et RAG (Retrieval-Augmented Generation). Ces méthodes s’appuient sur les modèles open source de Google, Gemma et Gemma-2, qui sont ajustés spécifiquement pour ces approches.
Points-clés de DataGemma
1. Data Commons : Ce référentiel figure parmi les plus grands au monde pour les données statistiques publiques, avec plus de 240 milliards de points de données couvrant des centaines de milliers de variables statistiques. Les sources de données incluent des organisations reconnues comme l’OMS, l’ONU, le CDC (Centers for Disease Control and Prevention) et les bureaux de recensement.
2. RIG (Retrieval-Interleaved Generation) : Cette approche améliore les capacités de Gemma-2 en interrogeant activement des sources fiables et en utilisant les données de Data Commons pour vérifier les faits. Lorsqu’on demande à DataGemma de produire une réponse, le modèle identifie d’abord les éléments nécessitant des données statistiques, puis récupère ces informations dans Data Commons. Bien que la méthodologie RIG soit déjà connue, son intégration dans le cadre de DataGemma est une innovation.
3. RAG (Retrieval-Augmented Generation) : Cette méthode permet aux modèles linguistiques d’accéder à des informations externes pertinentes en complément des données d’entraînement, leur fournissant un contexte plus riche et leur permettant de générer des réponses plus détaillées et précises. DataGemma met en œuvre cette méthode en exploitant la fenêtre de contexte étendue du modèle Gemini 1.5 Pro. Avant de générer une réponse, DataGemma récupère des informations pertinentes depuis Data Commons, ce qui réduit les risques d’hallucination et améliore l’exactitude des réponses.
Résultats prometteurs
Bien que ces approches en soient encore à leurs débuts, les résultats initiaux sont encourageants. Les chercheurs rapportent des améliorations significatives dans la gestion des données numériques par les modèles linguistiques. Les utilisateurs devraient donc constater une réduction des hallucinations, ce qui rend ces modèles plus fiables pour la recherche, la prise de décision et les questions générales.