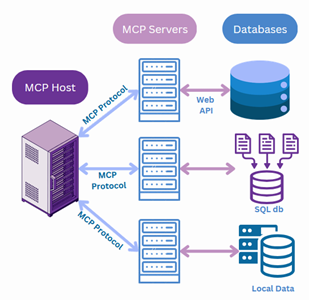
As large language models (LLMs) like GPT, Claude, and Gemini become foundational to AI applications, the question is no longer if we use them, but how we best architect their use. Traditional prompt engineering, crafting clever instructions to coax desired outputs, has taken us far. Yet, as real-world applications grow more complex, this approach reveals fundamental limitations. Enter Context Engineering: a rapidly evolving discipline focused on designing dynamic, structured information environments that empower LLMs to perform consistently, reliably, and at scale.
In this post, we unpack what context engineering is, why it matters, how it differs from prompt engineering, common pitfalls, and the techniques and tools driving this critical advance.
What is Context Engineering?
At its core, context engineering is the art and science of giving an LLM the right information, in the right format, at the right time to accomplish a task.

(See our previous article: “Software 3.0: How Large Language Models Are Reshaping Programming and Applications” on https://novelis.io/research-lab/software-3-0-how-large-language-models-are-reshaping-programming-and-applications/)

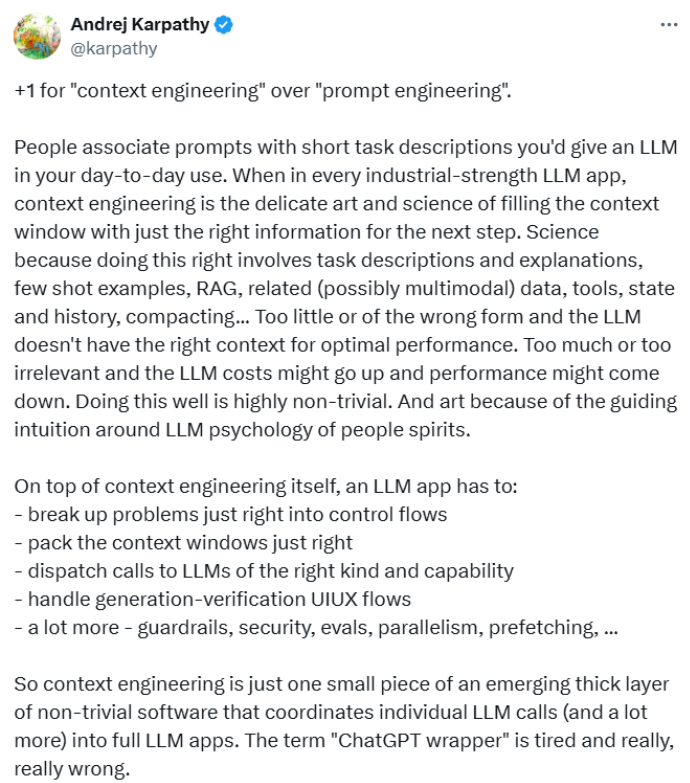
Where prompt engineering is about crafting static or one-off instructions, context engineering embraces the complexity of dynamic systems that manage how information flows into the model’s context window, the LLM’s working memory where it ‘sees’ and reasons about data.

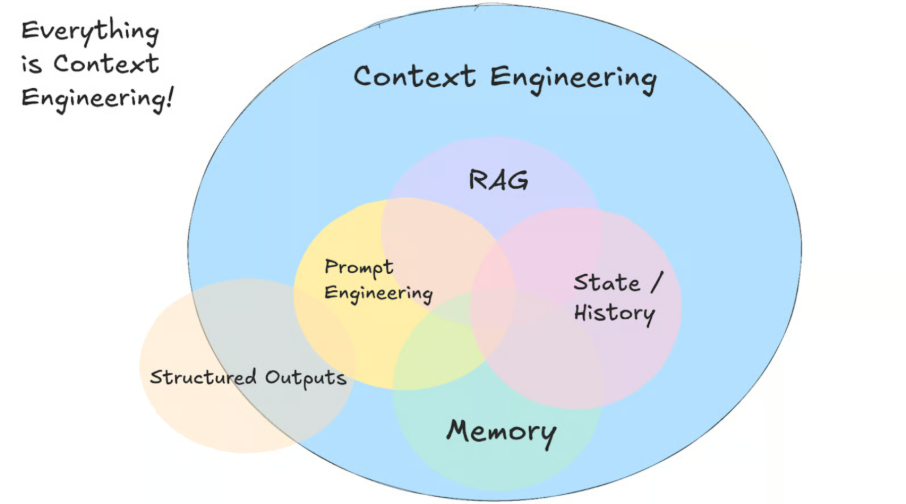
(Source: https://github.com/humanlayer/12-factor-agents/)
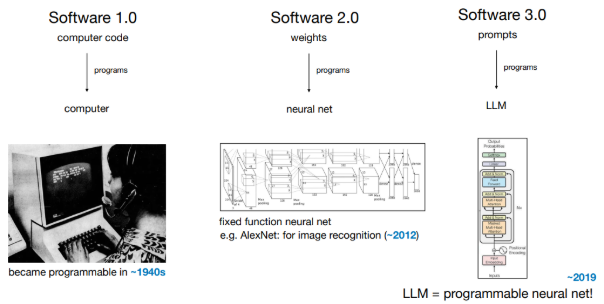
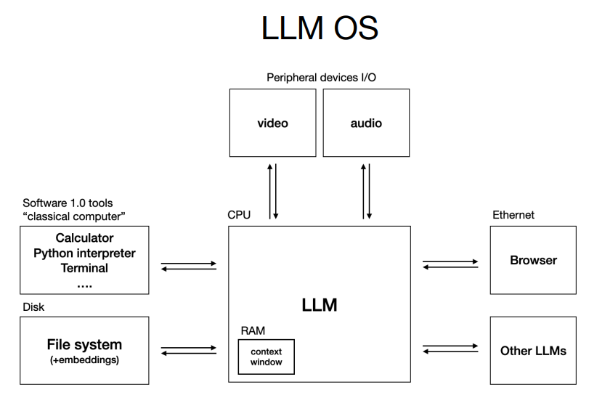
As an analogy, Andrej Karpathy in his talk (shared above) describes the LLM as a CPU and the context window as its RAM, limited, precious working memory that must be carefully packed to maximize performance. Context engineering is precisely about optimizing this RAM usage to enable sophisticated, multi-step AI applications.
More formally, context includes everything an AI needs to reason well: notes, reference materials, historical interactions, external tool outputs, and explicit instructions on output format. Humans naturally curate and access such information; for AI, we must explicitly engineer this information environment.
Context Engineering vs. Prompt Engineering: Key differences

While closely related, these disciplines differ fundamentally:
- Prompt Engineering is about what to say, crafting instructions or questions to get the model to respond appropriately. It works well for direct, interactive chatbot scenarios.
- Context Engineering is about how to manage all the information and instructions the AI will need across complex tasks and varying conditions. It involves orchestrating multiple components in a system, ensuring the AI understands and applies the right knowledge in the right moment.
Put simply:
Prompt engineering is like explaining to someone what to do.
Context engineering is like ensuring they have the right tools, background, and environment to actually do it reliably.
This shift is critical because AI agents cannot simply “chat until they get it right.” They require comprehensive, self-contained context, encompassing all possible scenarios and necessary resources, encoded and managed dynamically.
Why Context Engineering matters
Context engineering is essential for production-grade AI applications for several reasons:
- Reliability at Scale: Without careful context management, models forget or hallucinate crucial details mid-interaction. Compliance requirements or customer-specific data can be lost, risking inconsistent or even harmful outputs.
- Handling Complexity: Real-world AI apps involve layers of knowledge, tools, and user history. Prompts balloon into tangled instructions that lose coherence and potency. Context engineering provides the instruction manual and architecture for the AI agent to leverage everything effectively.
- Overcoming Prompt Limitations: Single-prompt approaches struggle when juggling multiple responsibilities or maintaining session memory. Context engineering enables modular, scalable memory, long-term knowledge, and tool integration.
In short, for companies building AI-powered products, especially AI agents that must perform multi-step reasoning and interact with external systems, context engineering is make or break.
Core components of AI Agents
Context engineering coordinates six fundamental components to build capable AI agents:
- Model: The foundational LLM (e.g., GPT-4, Claude, Gemini).
- Tools: External APIs or systems the agent can query (e.g., calendar, search).
- Knowledge and Memory: Persistent storage of relevant data, session history, and learned patterns.
- Audio and Speech: Interfaces enabling natural interaction.
- Guardrails: Safety and ethical controls.
- Orchestration: The systems managing deployment, monitoring, and ongoing improvement.
The context engineer’s role is to define how these parts work together through precisely crafted context, detailed prompts and structured data that govern the agent’s behavior.
Common failure modes in Context Engineering
Understanding failure modes helps engineers build more robust systems:
- Context Poisoning: Erroneous or hallucinated info contaminates the context and propagates. For example, an AI playing Pokémon hallucinating game states, then using that misinformation in future decisions.
- Context Distraction: Overloading with excessive history causes the model to ‘overfocus’ on past details and underperform on new reasoning.
- Context Confusion: Irrelevant or contradictory information pollutes the context, reducing reasoning effectiveness. Models may call irrelevant tools or misinterpret instructions.
- Context Clash: Conflicting information in the context leads to unstable outputs. Studies report up to 39% performance drops when incremental, conflicting data accumulate versus providing all info cleanly.
Proper engineering anticipates and mitigates these pitfalls through careful context curation and system design.
Techniques for effective Context Engineering
To ensure the LLM’s working memory contains exactly the right information when it needs it, context engineering leverages four foundational techniques:
- Writing Context: Creating persistent, external memory stores (“scratch pads”) for intermediate notes, long-term knowledge, and learned user preferences.
- Selecting Context: Intelligently retrieving only relevant information for the current step, using embedding-based semantic search or Retrieval Augmented Generation (RAG) methods to reduce noise and improve accuracy.
- Compressing Context: Summarizing or hierarchically compressing history to retain essential info without exceeding token limits, like capturing meeting minutes rather than every word.
- Isolating Context: Separating different tasks or information streams via multi-agent architectures or sandboxed threads to prevent interference and maintain clarity.
Together, these allow AI applications to scale beyond brittle, monolithic prompts toward modular, maintainable systems.
Tools and frameworks powering Context Engineering
Successful context engineering requires an integrated stack rather than standalone tools:
- Declarative AI Programming (e.g., DSPI): Define what you want, not how to ask, enabling high-level prompt compilation.
- Control Structures (e.g., LangGraph): Graph-based workflows with conditional logic and state persistence for complex context orchestration.
- Vector Databases (e.g., Pinecone, Weaviate, Chroma): Semantic search over massive documents, memories, and examples for precise context selection.
- Structured Generation Tools: Enforce consistent, parseable outputs (e.g., JSON, XML) to prevent corruption.
- Advanced Memory Systems (e.g., MEZero): Intelligent layers that manage information relationships, expiration of outdated facts, and irrelevant info filtering.
- Orchestration Platforms: Glue everything together, models, databases, APIs, while maintaining context coherence and monitoring.
These frameworks help move from ad hoc prompt hacks to systematic, scalable AI development.

(Source: “Context Engineering vs Prompt Engineering” by Mehul Gupta)
Conclusion
Context engineering marks a fundamental evolution in AI system design. It shifts the focus from crafting instructions to building dynamic information ecosystems that ensure large language models receive the precise data they need, when they need it and in the proper form, to perform reliably and robustly.
For anyone building sophisticated AI applications or agents, mastering context engineering is no longer optional, it’s essential. By addressing the failure modes of prompt-only systems and leveraging emerging tools and architectures, context engineering unlocks the true potential of LLMs to become versatile, dependable partners in complex real-world tasks.
Further Reading & Resources
- The New Skill in AI is Not Prompting, It’s Context Engineering
- 12-Factor Agents – Principles for building reliable LLM applications
- Context Engineering for Agents
- A Survey of Context Engineering for Large Language Models