Thank you for your interest in intelligent automation and how it can deliver improved patient outcomes and efficiencies in your healthcare organization.
Through robotic process automation (RPA) and artificial intelligence (AI), intelligent automation can help healthcare organizations like yours, free your clinical and admin staff to focus on what is really important – your patients and the delivery of your services.
Through intelligent automation, you can:
Cut overly manual and time-consuming processes that divert attention away from patient care
Improve efficiencies in your digital back-end operations, such as appointment bookings and reminders
Speed up patient-facing apps and interfaces
Boost staff satisfaction
Manage costs
And most important of all, give valuable time back to your health professionals.
We partner with one of the world’s leading intelligent automation experts, SS&C Blue Prism, to provide specialist and expert advice in the health sector.
Five Ways to Put Humans At The Heart of Patient Care eBook sets out
Why your health clients need automation
How automation can improve efficiencies in their Healthcare Operations and back office functions
How RPA and intelligent automation can enhance patient experiences and access to care, leading to better patient outcomes
How automation can boost staff morale and manage the cost of care
And how, through automation, they can keep healthcare human
Working together, we can improve your patients’ outcomes through intelligent automation or boost your existing digital workforce.
At Novelis, we are committed to using new technologies as tools to better respond to our customers’ operational challenges and thus better support them in their transformation. That’s why we have an ambitious R&D laboratory, with substantial investments: 26% of revenues are invested in research.
To keep you up to date with the latest scientific news, we’ve created a LinkedIn page dedicated to our Lab, called Novelis Research, check it out!
As we start the new year, let’s take a look at Novelis’ research contributions for the month of January. Our team has had the rewarding opportunity to present recent advances in the use of artificial intelligence in the healthcare sector. Here is an overview of the articles we had the pleasure of sharing with you:
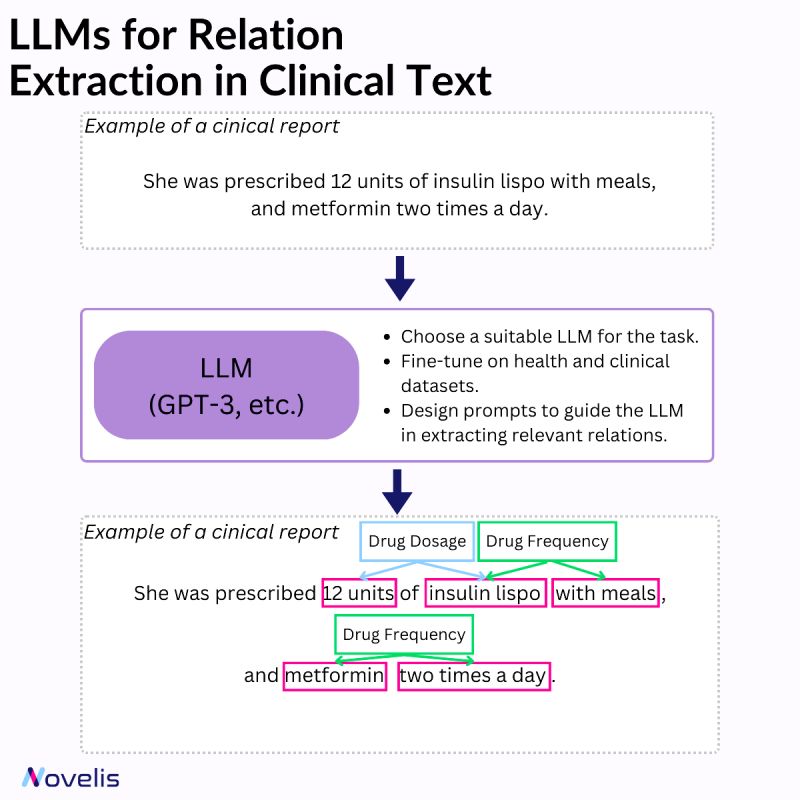
🤖Clinical Insights: Leveraging LLMs for Relation Extraction in Clinical Text🩺
Relation extraction involves identifying connections between named entities in text. In the clinical domain, it helps extract valuable information from documents such as diseases, symptoms, treatments, and medications. Various techniques can be used for named entity recognition and relation extraction (rule-based systems, machine learning approaches, and hybrid systems that combine both).
Large Language Models (LLMs) have significantly impacted the field of machine learning, especially in natural language processing (NLP). These models, which are trained on large amounts of text data, are capable of understanding and generating natural language text with impressive accuracy. They have learned to identify complex patterns and semantic relationships within language, can handle various types of entities, and can be adapted to different domains and languages. They can also capture contextual information and dependencies more efficiently and are capable of transfer learning. When combined with a set of prompt-based heuristics and upon fine-tuning them on clinical data, they can be particularly useful for named entity recognition and relation extraction tasks.
🎯Why is this essential?🎯By identifying the relationships between different entities, it becomes possible to gain a better understanding of how various aspects of a patient’s health are connected. This, in turn, can help in developing effective interventions. For instance, clinical decision support can be improved by extracting relationships among diseases, symptoms, and treatments from electronic health records. Similarly, identifying potential interactions between different medications can ensure patient safety and optimize treatment plans. Automating the medical literature review process can facilitate quick access to relevant information.
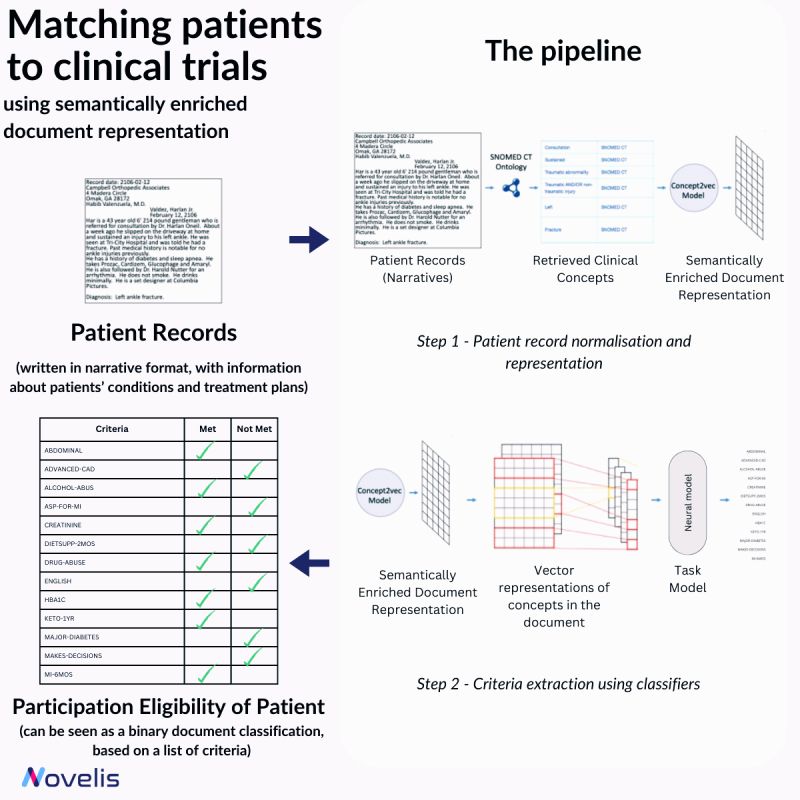
🤖Matching Patients to Clinical Trials Using Semantically Enriched Document Representation🩺
Recruiting eligible patients for clinical trials is crucial for advancing medical interventions. However, the current process is manual and takes a lot of time. Researchers ask themselves, “Which interventions lead to the best outcomes for a particular patient?” To answer this question, they explore scientific literature, match patients with potential trials, and analyze patient phenotypes to extract demographic and biomarker information from clinical notes. An approach presented in the paper “Matching Patients to Clinical Trials Using Semantically Enriched Document Representation” automates patient recruitment by identifying which patients meet the criteria for selection from a corpus of medical records.
This approach is utilized to extract important information from narrative clinical documents, gather evidence for eligibility decisions based on inclusion/exclusion criteria, and overcome challenges such as differences in reporting style with the help of semantic vector representations from domain ontologies. The SNOMED CT ontology is used to normalize the clinical documents, and the DBpedia articles are used to expand the concepts in SNOMED CT oncology. The team effectively overcame reporting style differences and sub-language challenges by enriching narrative clinical documents with domain ontological knowledge. The study involved comparing various models, and a neural-based method outperformed conventional machine learning models. The results showed an impressive overall F1-Score of 84% for 13 different eligibility criteria. This demonstrated that using semantically enriched documents was better than using original documents for cohort selection.
🎯Why is this essential?🎯 This research is a significant step towards improving clinical trial recruitment processes. The automation of patient eligibility determination not only saves time but also opens avenues for more efficient drug development and medical research.
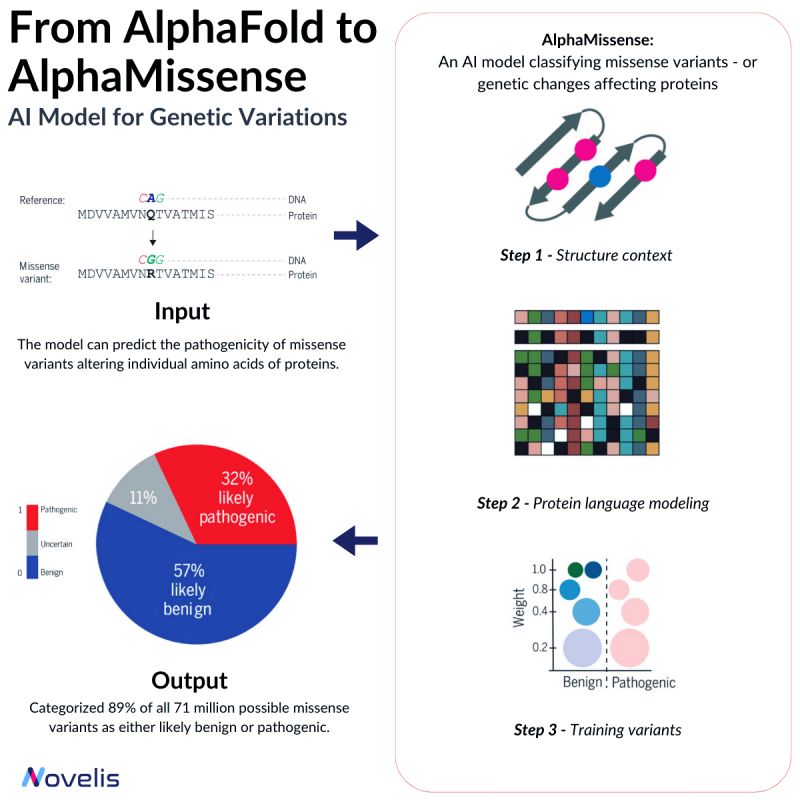
🤖From AlphaFold to AlphaMissense: Models for Genetic Variations🩺
Missense mutations are responsible for contributing to a number of diseases, such as Marfan Syndrome and Huntington’s Disease. These mutations cause a change in the sequence of amino acids in a protein, which can lead to unpredictable effects on the organism. Depending on their nature, missense mutations can either be pathogenic or benign. Pathogenic variants significantly affect protein function, causing impairment in overall organism behavior, whereas benign variants have minimal or no effect on organism behavior.
🎯 Why is this essential? 🎯Despite identifying over 4 million missense variants in the human genome, only around 2% have been conclusively labeled as either pathogenic or benign. The significance of the majority of missense variants is yet to be determined, making it difficult to predict their clinical implications. Hence, ongoing efforts aim to develop highly effective methods for accurately predicting the clinical implications of these variants.
The missense mutation problem shares similarities with the protein folding problem, both seeking to enhance explainability and predict outcomes related to variations in the amino acid structure. In 2018, DeepMind and EMBL-EBI launched AlphaFold, a groundbreaking protein structures prediction model. Alphafold facilitates the prediction of protein structures from previously inaccessible amino acid sequences.
By leveraging the capabilities of Transfer Learning on binary labeled public databases (such as BFD, MGnify, and UniRef90), DeepMind proposes AlphaMissense, an AlphaFold finetune that achieves state-of-the-art predictions on ClinVar (a genetic mutation dataset) without the need for explicit training on such data.
✨ The tool is currently available as a freely provided Variant Effect Predictor software plugin.
Meet GatorTronGPT, an advanced AI model developed by researchers at the University of Florida in collaboration with NVIDIA. This model transforms medical documentation, helping create precise notes. Its ability to understand complex medical language makes it a game-changer.
The language model was trained using the GPT-3 architecture. It was trained on a large amount of data, including de-identified clinical text from the University of Florida Health and diverse English text from the Pile dataset. GatorTronGPT was then employed to tackle two important biomedical natural language processing tasks: biomedical relation extraction and question answering.
A Turing test was conducted to evaluate the performance of GatorTronGPT. Here, the model generated synthetic clinical text paragraphs, and these were mixed with real-world paragraphs written by University of Florida Health physicians. The task was identifying which paragraphs were human-written and which were synthetic based on text quality, coherence, and relevance. Even experienced doctors could not differentiate between the generated and human-written paragraphs, which is a testament to the high quality of the GatorTronGPT output.
✨ Powered by OpenAI’s GPT-3 framework, GatorTronGPT was trained on the supercomputer HiPerGator, with support from NVIDIA.
🎯 Why is this essential? 🎯 By replicating the writing skills of human clinicians, GatorTronGPT allows healthcare professionals to save time, reduce burnout, and focus more on patient care.
Stay tuned for exciting new prospects in the month ahead!
At Novelis, we are committed to using new technologies as tools to better respond to our customers’ operational challenges and thus better support them in their transformation. That’s why we have an ambitious R&D laboratory, with substantial investments: 26% of revenues are invested in research.
To keep you up to date with the latest scientific news, we’ve created a LinkedIn page dedicated to our Lab, called Novelis Research, check it out!
Let’s recap all the Novelis Research articles from December. This month, our team had the pleasure of sharing with you the latest news on the various existing uses of AI in healthcare. Here are the articles we shared with you:
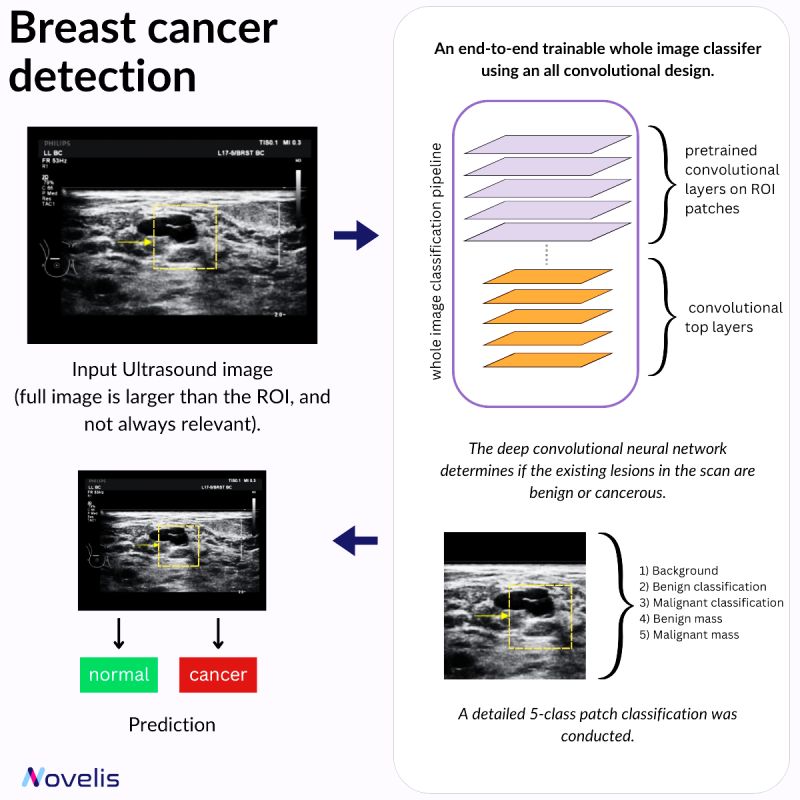
🔎Deep Learning to Improve Breast Cancer Detection on Screening Mammography🩺
Our focus this month is on how AI can be used in healthcare. This post will present a paper titled “Deep Learning to Improve Breast Cancer Detection on Screening Mammography” that covers an innovative deep-learning approach that aims to enhance breast cancer detection in screening mammography. A full-field digital mammography (FFDM) image typically has a resolution of 4000 x 3000 pixels, while a potentially cancerous region of interest (ROI) can be as small as 100 × 100 pixels. The method leverages these clinical ROI annotations to refine mammogram classification, which holds promise for significantly improving screening accuracy.
The technology utilizes an “end-to-end” training approach. It is trained on local image patches with detailed annotations and then adapts to whole images, requiring only image-level labels. This approach reduces dependence on detailed annotations, making it more versatile and scalable across various mammography databases.
🎯Why is this essential? 🎯 This paper is significant due to its potential to improve the accuracy of breast cancer detection in mammograms. It offers a more generalizable and scalable solution compared to traditional methods, reducing the risk of false positives and negatives. This approach could play a crucial role in early breast cancer detection and, therefore, help save lives by identifying cancer at more treatable stages.
🤖 Revolutionizing Cancer Diagnosis: The Vital Role of AI in Early Detection🩺
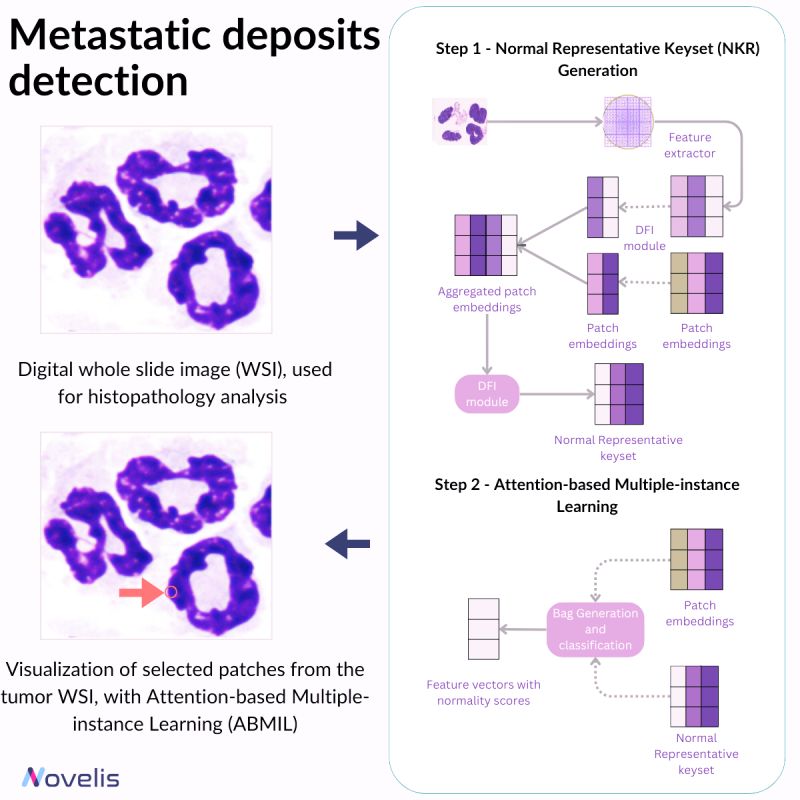
Recent advancements in AI have significantly contributed to cancer research, particularly in analyzing histopathological imaging data. This reduces the need for extensive human intervention. In breast cancer, early detection of lymph node metastasis holds paramount importance, especially in the case of smaller tumors. Early diagnosis plays a crucial role in determining the treatment outcome. Pathologists often face difficulties in identifying tiny or subtle metastatic deposits, which leads to greater reliance on cytokeratin stains for improved detection. However, this method has inherent limitations and can be improved upon. This is where deep learning comes in as a vital alternative to address the intricacies of detecting small tumors early.
A notable approach within deep learning is the normal representative keyset attention-based multiple-instance learning (NRK-ABMIL). This technique consists of fine-tuning the attention mechanism to prioritize the detection of lesions. To achieve it, NRK-ABMIL establishes an optimal keyset of normal patch embeddings, referred to as the normal representative keyset.
🎯Why is this essential?🎯 It is important to continue the research in whole slide images (WSIs) methods, with a particular emphasis on enhancing the detection of small lesions more precisely and accurately. This pursuit is crucial because advancing our understanding and refinement of WSIs can significantly impact early diagnosis and treatment efficacy.
Stay tuned for more exciting insights in the coming month!
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
![[Ebook healthcare & automation] Five Ways to Put Humans At The Heart of Patient Care](https://novelis.io/wp-content/uploads/2024/04/Landing-Page-Banner_640x350.png)