Technological advancements (connected objects, development of 5G) have made the exchange of massive data in our society more fluid. Today, this data represents a real wealth in terms of the quantities of information that could be used to analyze political climates, predict crises, and improve services, products, and processes, for example. This phenomenon of massification and circulation of data thus raises the question of the risk of privacy violations due to the exposure of personal data.
According to the latest report by the American giant McAfee, a survey of cloud service users shows that :
91% of respondents do not encrypt inactive data,
87% do not delete data immediately after closing an account.
While GDPR currently requires companies to do everything possible to secure their personal data without risking heavy fines, anonymization is not a general obligation. But this technique, coupled with AI and automation, is increasingly being seen as the most effective means of compliance.
Anonymization will allow companies to continue processing personal data while respecting the rights and freedoms of individuals, thus significantly reducing their exposure to potential attacks. This also strengthens system security and reduces the risk of data theft, as once anonymized, the data has no value.
Where previously GDPR could be a constraint around data, it now becomes an opportunity to better protect oneself.
Former RGPD lawyer & certified DPO – CEO & Co-founder of Dipeeo, Raphaël Buchard, will give us the keys to stay RGPD compliant.
Our technical and business experts at Novelis – Sanoussi Alassan, Data Scientist and Raphaël Brunel, Data Analyst – will talk about the technical solution we propose: data anonymization coupled with AI for structured data processing and automation for unstructured data processing.
On the agenda of this webinar:
RGPD & Compliance
Presentation of use cases
Knowing the different anonymization methods and equipping yourself with a professional solution
Data exploitation is more than ever a major issue within any type of organization. Several use cases are covered, from exploration to extraction of relevant and usable information, in order to :
Understand the environment of an organization
Better understand its employees
Improve its services, products and processes (use case of production data in a test and/or development environment)
Handling this mass of information is not without consequences. It contains sensitive information whose disclosure may harm legal entities and/or individuals. This is why the European Parliament adopted in May 2016, the General Data Protection Regulation (GDPR) aiming to frame the processing of data in an equal way throughout the European Union. Its objectives: to strengthen the rights of individuals, to make actors processing data more accountable and to promote cooperation between data protection authorities. Pseudonymization/anonymization thus appears to be an indispensable technique for protecting personal data and promoting compliance with regulations.
What is Pseudonymization and Anonymization?
ENISA [1] (the European Union’s cybersecurity agency) defines pseudonymization as a de-identification process. It is the processing of sensitive data in such a way that a natural person can no longer be directly identified without additional information. Whereas anonymization is a process by which personal data are irreversibly altered in such a way that the data subject can no longer be identified, directly or indirectly, either by the controller alone or in collaboration with other third parties [1].
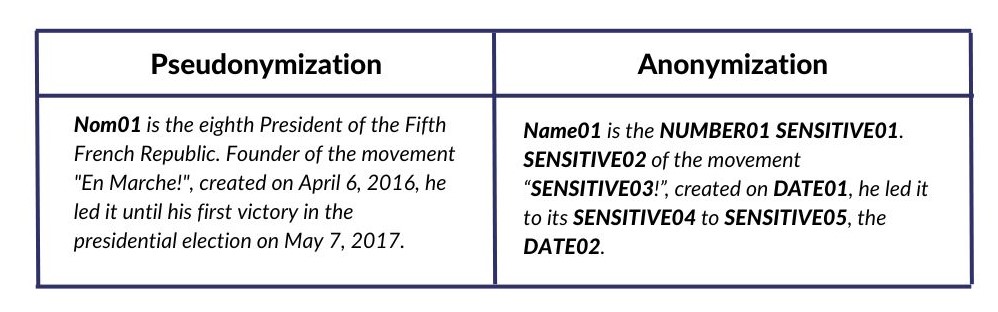
When considering the following text: “Emmanuel MACRON is the eighth President of the Fifth French Republic. Founder of the “En Marche!” movement, created on April 6, 2016, he led it until his first victory in the presidential election on May 7, 2017.”
There are three types of information:
the named entities: Emmanuel MACRON, April 6, 2016, May 7, 2017, En Marche, eighth
the mentions: President of the French Fifth Republic, Founder
Other identifying morphemes: first victory, the presidential election
The following table summarizes the expected result when applying these two techniques
A third category of approach for processing sensitive data is emerging with the advances of neural algorithms on natural language exploitation: advanced pseudonymization. The latter is capable of processing the vast majority of sensitive “identifying” information in a text. However, there are still cases at the margin that can be detected if the context of the subject is known. This is the example of the following text “LinkedIn is a social network. In France, in 2022, LinkedIn has more than 25 million members and 12 million estimated monthly active members, making it the 6th largest social network” where the term 6th largest social network, difficult to detect, can identify LinkedIn when doing some research on the Internet.
What is “sensitive data”?
Sensitive data is information that can identify a natural or legal person. This is the case of the following information when associated with a physical person: full name (surname and first name), location, organization, date of birth, addresses (email, housing), identifying numbers (credit card, social security, telephone) …. or information related to a legal person such as the name of the company, its address, its SIREN and SIRET identifiers, ….
How to pseudonymize data?
The CNIL [2] describes two types of pseudonymization techniques: those that rely on the creation of relatively basic pseudonyms (counter, random number generator) and those that rely on cryptographic techniques (secret key encryption, hash function). All of these methods explain how sensitive data should be handled in the context of pseudonymization. They do not explain how to identify it. The identification process can be simple when the data is tabular. In this case, it is sufficient to delete or encrypt the contents of the relevant columns.
At Novelis, we are working on advanced pseudonymization of sensitive data contained in free text. Identification in this context is complex and is often performed manually by humans, which imposes a cost in time and skilled human resources. Artificial intelligence (AI) and automatic language processing (NLP) techniques are however sufficiently robust to automate this task. We will thus generally distinguish two types of approaches for sensitive data extraction: neural approaches and rule-based approaches. Although they provide excellent results, especially with the emergence of Transformers (deep learning model), neural approaches require large datasets to be relevant, which is not always the case in the industrial world. They also require an annotation task by experts in order to provide the models with a quality dataset for training. As for rule-based models, they suffer from generalization problems. A rule-based model will indeed tend to have a good accuracy on the sample used as a training base but will be more difficult to apply to a new dataset not studied in the initial assumptions
We propose a hybrid approach exploiting the strengths of NLP techniques and neural models. First, we built a corpus containing addresses, to train a neural model able to detect an address in a text. A benchmarking of the models was performed in order to choose the adequate model. The model is then improved using a fine-tuning strategy. Combined with NLP python libraries, the model provides a robust solution for extracting addresses and named entities such as people’s names, places and organizations. Patterns (regular expressions) were designed, by Novelis experts, for the extraction of other identified sensitive data. Finally, heuristics were used to disambiguate and correct the extracted information.
With this approach, we have built a reliable and robust system to process sensitive information contained in any type of document (pdf, word, email, …). The goal is to remove low value-added tasks from the data processors by automated assistance.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
![[Webinar] Facilitate and accelerate GDPR compliance with data anonymization](https://novelis.io/wp-content/uploads/2023/03/Evenements-LinkedIn-2.jpg)