Novelis ranks 1st worldwide in the international CodeXGLUE challenge, organized by Microsoft, on Java code generation from natural language.
Last March, Novelis was already in the spotlight thanks to its participation in two international challenges: the Spider Challenge organized by Yale University and the WikiSQL Challenge organized by Cornell University. In both challenges, Novelis took second and seventh place, alongside the biggest leaders in AI and RPA.
The Novelis R&D Lab team won 1st place in the international CodeXGLUE challenge on Java code generation from natural language:
The CodeXGLUE challenge – General Language Understanding Evaluation benchmark for CODE – organized by Microsoft, brings together large companies such as IBM or Microsoft and international universities such as Case Western Reserve University, UCLA/Columbia University, or INESC-ID/Carnegie Mellon University.
With CodeXGLUE, Microsoft seeks to “support the development of models that can be applied to various code intelligence problems, with the goal of increasing the productivity of software developers”. Microsoft wants to encourage researchers to take part in current challenges to further advance code intelligence.
According to Evans Data Corporation, there will be 23.9 million professional developers in 2019 worldwide, and the number is expected to reach 28.7 million by 2024. “With the growing population of developers, code intelligence, which aims to leverage AI to help software developers improve the productivity of the development process, is growing increasingly important in both communities of software engineering and artificial intelligence.” Github.com
The Challenge includes 14 datasets for 10 diverse programming language tasks covering:
- Code-Code (redundancy/clone detection, code error detection, gap code (or text) completion, code autocompletion, code correction and code-to-code translation),
- Text-Code (natural language code search, Text-Code generation),
- Code-Text (code summary),
- Text-Text (documentation translation).
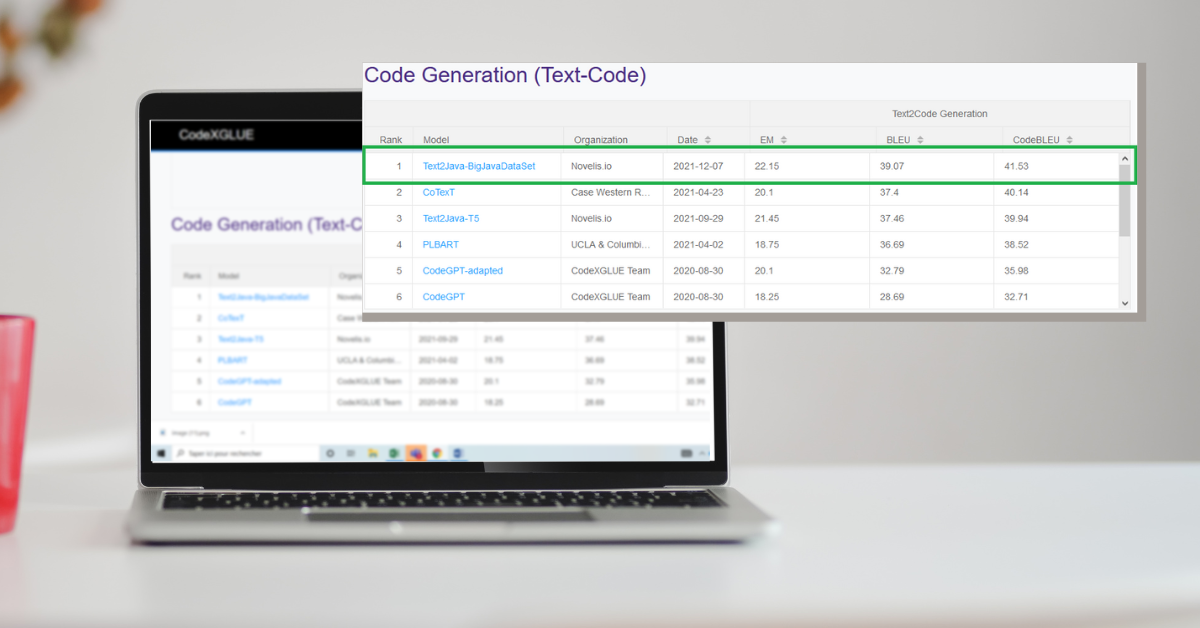
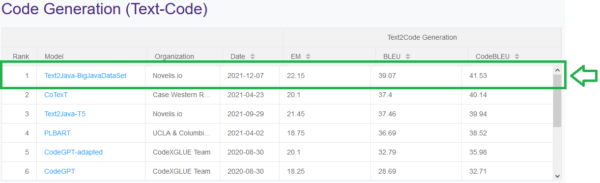
Novelis has participated in the Text-Code task, which consists in automatically generating Java source code from natural language.
Currently, the Text-Code task leaderboard has 9 participants. Once we had built a model that met our expectations, we submitted our test results for official evaluation by the Microsoft community based on 3 criteria:
- The Exact Matching (EM),
- The BLUE Score,
- CodeBLEU.
The Microsoft community then updated the ranking on the leaderboard that you can find below.
“We have been working for more than two years on the problem of generating code in programming language from a need described in natural language. Our work adopts several approaches, designed and implemented by the Novelis R&D Lab team and has led to several results in the task of generating business code in Python and Java. Until now, we did not have a benchmark or a challenge that would allow us to evaluate our results in an objective way. Microsoft’s CodeXGLUE challenge allows us to gain this credibility because we could officially evaluate our results. Moreover, the 1st place obtained in the code generation task proves that we are on the right track. Note that the results published in this challenge are not very high because on the one hand the code generation task is very complex and on the other hand the proposed models are not yet mature enough.”
Novelis has placed innovation and R&D at the heart of its development strategy
Since its creation, Novelis has chosen to invest massively (30% of its turnover) in research and development.
For El Hassane Ettifouri, CIO and Director of the Novelis R&D Lab, this is no small matter:
“Today very few companies are willing to invest ¼ of their turnover in research. It is this risk-taking that differentiates Novelis from other companies. We want to have a foot in the future and participate in the construction of this future by investing in research on technologies. Innovation is an integral part of Novelis’ DNA.
Moreover, our research work is concrete and has a real impact on our customers – who reap all the benefits of our technologies for the automation of their processes – but also for our employees who evolve in an innovative working environment.”