On October 8th, 2024, Novelis will participate in the Artificial Intelligence Expo of the Digital Transformation Direction of the Ministry of the Interior.
This event, held at the Bercy Lumière Building in Paris, will immerse you in the world of AI through demonstrations, interactive booths, and immersive workshops. It’s the perfect opportunity to explore the latest technological advancements that are transforming our organizations!
Join Novelis: Turning Generative AI into a Strength for Information Sharing
We invite you to discover how Novelis is revolutionizing the way businesses leverage their expertise and share knowledge through Generative AI. At our booth, we will highlight the challenges and solutions for the reliable and efficient transmission of information within organizations.
Our experts – El Hassane Ettifouri, Director of Innovation; Sanoussi Alassan, Ph.D. in AI and Generative AI Specialist; and Laura Minkova, Data Scientist – will be present to share their insights on how AI can transform your organization.
Don’t miss this opportunity to connect with us and enhance your company’s efficiency!
Are you struggling to determine how to kick-start or optimize your intelligent automation efforts? You’re not alone. Many organizations face challenges in deploying automation and AI technologies effectively, often wasting time and resources. The good news is there’s a way to take the guesswork out of the process: Process Intelligence.
Join us on September 26 for an exclusive webinar with our partner ABBYY, Take the Guesswork Out of Your Intelligent Automation Initiatives Using Process Intelligence. In this session, Catherine Stewart, President of the Americas at Novelis, will share her expertise on how businesses can use process mining and task mining to optimize workflows and deliver real, measurable impact.
Why You Should Attend
Automation has the potential to transform your business operations, but without the right approach, efforts can easily fall flat. Catherine Stewart will draw from her extensive experience leading automation initiatives to reveal how process intelligence can help businesses achieve efficiency gains, reduce bottlenecks, and ensure long-term success.
Key highlights:
How process intelligence can provide critical insights into how your processes are performing and where inefficiencies lie.
The role of task mining in capturing task-level data to complement process mining, providing a complete view of your operations.
Real-world examples of how Novelis has helped clients optimize their automation efforts using process intelligence, leading to improved efficiency, accuracy, and customer satisfaction.
The importance of digital twins for simulating business processes, allowing for continuous improvements without affecting production systems.
Discover the first version of our scientific publication “Graphical user interface agents optimization for visual instruction grounding using multi-modal artificial intelligence systems” published in arxiv and submitted to the Engineering Applications of Artificial Intelligence journal. This article is already available to the public.
Most instance perception and image understanding solutions focus mainly on natural images. However, applications for synthetic images, and more specifically, images of Graphical User Interfaces (GUI) remain limited. This hinders the development of autonomous computer-vision-powered Artificial Intelligence (AI) agents. In this work, we present Search Instruction Coordinates or SIC, a multi-modal solution for object identification in a GUI. More precisely, given a natural language instruction and a screenshot of a GUI, SIC locates the coordinates of the component on the screen where the instruction would be executed. To this end, we develop two methods. The first method is a three-part architecture that relies on a combination of a Large Language Model (LLM) and an object detection model. The second approach uses a multi-modal foundation model.
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
The Chief AI Officer USA Exchange event, scheduled for May 1st and 2nd, 2024, is an exclusive, invitation-only gathering held at the Le Méridien Dania Beach hotel in Fort Lauderdale, Florida. Tailored for executives from C-Suite to VP levels, it aims to simplify the complexities of Artificial Intelligence.
The world of AI is evolving at an unprecedented pace, offering unparalleled opportunities while presenting significant challenges. In this complex landscape, the role of this event becomes crucial for guiding businesses through the intricacies of AI, maximizing its benefits while cautiously navigating to avoid ethical pitfalls and privacy concerns.
Novelis stands out as an expert in Automation and GenAI, possessing expertise in the synergistic integration of these two fields. By merging our deep knowledge of automation with the latest advancements in GenAI, we provide our partners and clients with unparalleled expertise, enabling them to navigate confidently through the complex AI ecosystem.
Novelis will be represented by Catherine Stewart, President and General Manager for the Americas, Walid Dahhane the CIO & Co-Founder and Paul Branson, Director of Solution Engineering.
The event represents a peerless platform for defining emerging roles in AI, discussing relevant case studies, and uncovering proven strategies for successful AI integration in businesses. Join us to discuss AI and Automation together!
Discover the application of AI for efficiently utilizing data from temporal series forecasts.
CHRONOS – Foundation Model for Time Series Forecasting
Time series forecasting is crucial for decision-making in various areas, such as retail, energy, finance, healthcare, and climate science. Let’s talk about how AI can be leveraged to effectively harness such crucial data. The emergence of deep learning techniques has challenged traditional statistical models that dominated time series forecasting. These techniques have mainly been made possible by the availability of extensive time series data. However, despite the impressive performance of deep learning models, there is still a need for a general-purpose “foundation” forecasting model in the field.
Recent efforts have explored using large language models (LLMs) with zero-shot learning capabilities for time series forecasting. These approaches prompt pretrained LLMs directly or fine-tune them for time series tasks. However, they all require task-specific adjustments or computationally expensive models.
With Chronos, presented in the new paper “Chronos: Learning the Language of Time Series“, the team at Amazon takes a novel approach by treating time series as a language and tokenizing them into discrete bins. This allows off-the-shelf language models to be trained on the “language of time series” without altering the traditional language model architecture.
Pretrained Chronos models, ranging from 20M to 710M parameters, are based on the T5 family and trained on a diverse dataset collection. Additionally, data augmentation strategies address the scarcity of publicly available high-quality time series datasets. Chronos is now the state-of-the-art in-domain and zero-shot forecasting model, outperforming traditional models and task-specific deep learning approaches.
Why is this essential? As a language model operating over a fixed vocabulary, Chronos integrates with future advancements in LLMs, positioning it as an ideal candidate for further development as a generalist time series model.
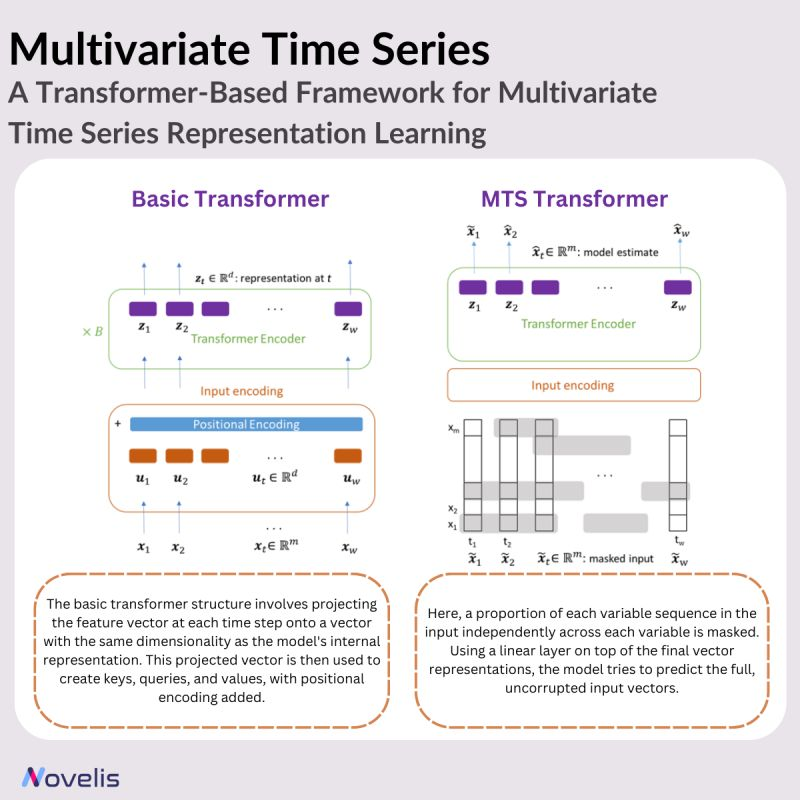
Multivariate Time Series – A Transformer-Based Framework for Multivariate Time Series Representation Learning
Multivariate time series (MTS) data is common in various fields, including science, medicine, finance, engineering, and industrial applications. It tracks multiple variables simultaneously over time. Despite the abundance of MTS data, labeled data for training models remains scarce. Today’s post presents a transformer-based framework for unsupervised representation learning of multivariate time series by providing an overview of a research paper titled “A Transformer-Based Framework for Multivariate Time Series Representation Learning,” authored by a team from IBM and Brown University. Pre-trained models generated from this framework can be applied to various downstream tasks, such as regression, classification, forecasting, and missing value imputation.
The method works as follows: the main idea of the proposed approach is to use a transformer encoder. The transformer model is adapted from the traditional transformer to process sequences of feature vectors that represent multivariate time series instead of sequences of discrete word indices. Positional encodings are incorporated to ensure the model understands the sequential nature of time series data. In an unsupervised pre-training fashion, the model is trained to predict masked values as part of an autoregressive denoising task where some input is hidden.
Namely, they mask a proportion of each variable sequence in the input independently across each variable. Using a linear layer on top of the final vector representations, the model tries to predict the full, uncorrupted input vectors. This unsupervised pre-training approach leverages the same labeled data samples, and in some cases, it demonstrates performance improvements even when compared to the fully supervised methods. Like any transformer architecture, the pre-trained can be used for regression and classification tasks by adding output layers.
The paper introduces an interesting approach to using transformer-based models for effective representation learning in multivariate time series data. When evaluated on various benchmark datasets, it shows improvements over existing methods and outperforms them in multivariate time series regression and classification. The framework demonstrates superior performance even with limited training samples while maintaining computational efficiency.
Discover the recent advances in the application of AI to industrial infrastructures.
Overview of Predictive maintenance of pumps in civil infrastructure using AI
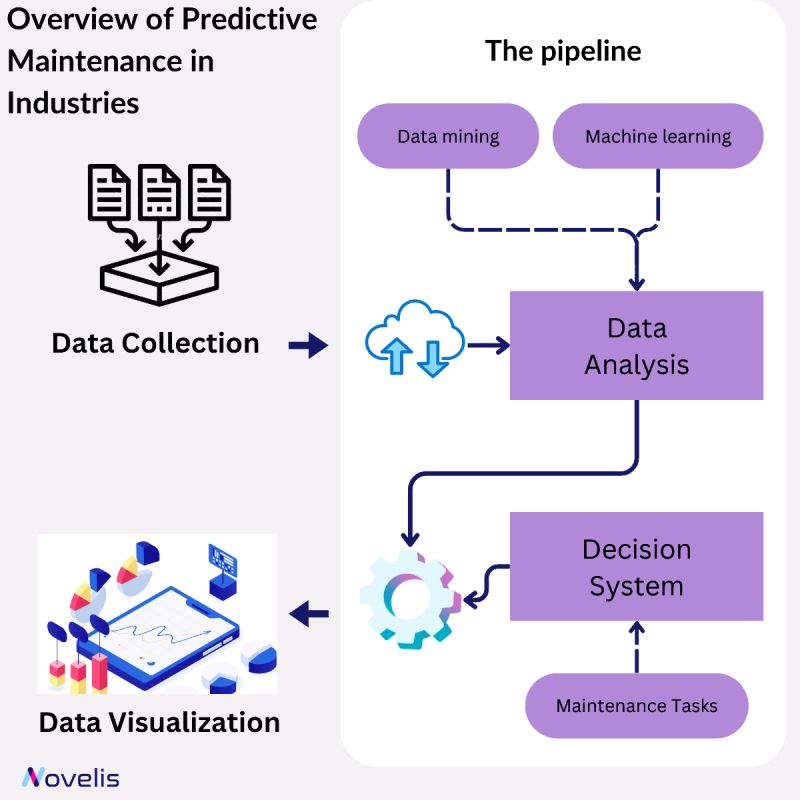
Predictive maintenance (PdM) is a proactive maintenance strategy that leverages data-driven analysis, analytics, artificial intelligence (AI) methods, and advanced technologies to predict when equipment or machinery is likely to fail. An example of predictive maintenance using AI techniques is in civil infrastructure, particularly in the upkeep of pumps.
Three main maintenance strategies are applied to pumps in civil infrastructure: corrective maintenance, preventive maintenance, and predictive maintenance (PdM). Corrective maintenance involves diagnosing, isolating, and rectifying pump faults after they occur, aiming to restore the failed pump to a functional state. Preventive maintenance adheres to a predefined schedule, replacing deteriorated pump parts at regular intervals, irrespective of whether they require replacement. In contrast, to overcome the drawbacks of corrective and preventive maintenance approaches, PdM utilizes data-driven analysis. The process involves continuous monitoring of real-time data from machinery. By employing sensors to gather information like vibration, temperature, and other relevant metrics, the system establishes a baseline for normal operational conditions. Machine learning algorithms then analyze this data, identifying patterns and anomalies indicative of potential issues or deterioration.
A cutting-edge advancement in technology is the ADT-enabled Predictive Maintenance (PdM) framework designed specifically for Wastewater Treatment Plant (WWTP) pumps.
Why is this essential? This technology is important because predictive maintenance of pumps in civil infrastructure, powered by AI, prevents unexpected failures. It enhances system reliability, reduces downtime, and optimizes resource allocation. Detecting issues early through data-driven analysis ensures efficient and resilient operations, which is crucial for the functionality of vital infrastructure components.
LCSA – Machine Learning Based Model
Artificial Intelligence for Smarter, More Sustainable Building Design
In the last couple of years, the field of artificial intelligence (AI) has had an influence on a great deal of fields from healthcare (check out our posts from last month! 😉), to finance, and even construction!
This month our theme is AI for industrial infrastructures. A large component of industrial infrastructures is the construction of physical infrastructures likes roads, bridges, sewage systems and buildings. This post seeks to tackle AI applications in the construction of buildings. Specifically, we take a deeper look into how AI and machine learning (ML) can help towards designing more sustainable homes and buildings in the future, as well as re-assessing the environmental impacts of existing buildings.
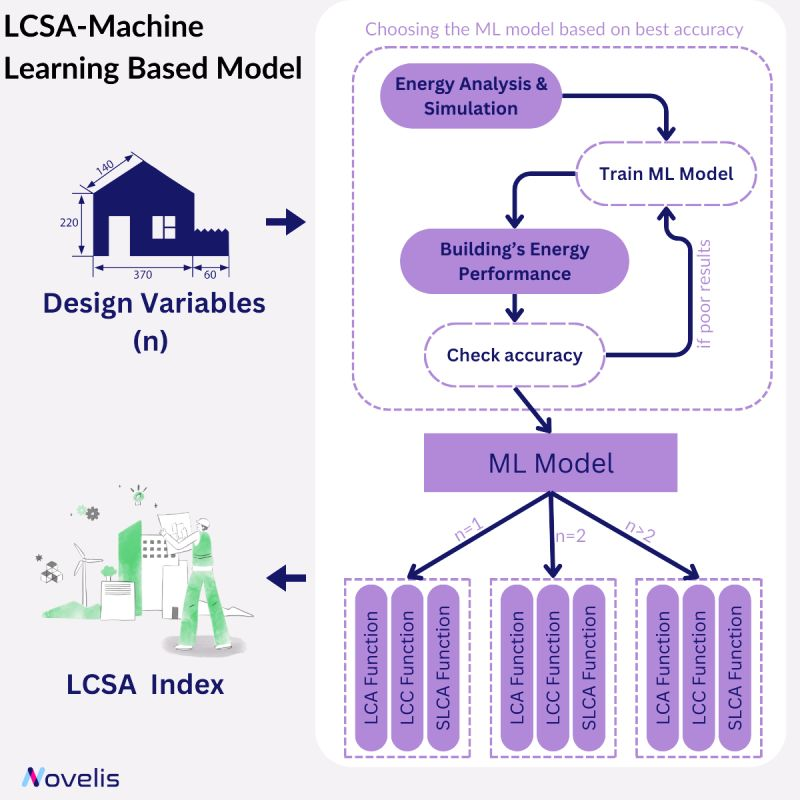
One technique in combatting the negative environmental impacts of the construction industry is to assess the impact of a project before hand, using the Life Cycle Sustainable Assessment (LCSA) approach. The latter takes into account a building’s environmental (Life Cycle Assessment, LCA), economic (Life Cycle Costing, LCC), and social (Social Life Cycle Assessment, SLCA) performance throughout the whole life cycle of a building and gives a better indication of the sustainability of a project.
With the use of an ML model (the best one might differ depending on the project), the building’s energy performance can be predicted and can further help determine the (possibly very complicated) functions for the LCA, LCC and SLCA indexes. The typically tedious and lengthy task of computing the LCSA thus becomes significantly more straightforward.
Why is this essential? This methodology allows for not only the faster assessment and rejection of projects that have unfavourable short and long-term impacts, but the quicker acceptance of better and more sustainable building designs for a greener future!
Smart Quality Inspection
AI-Based Quality Inspection for Manufacturing
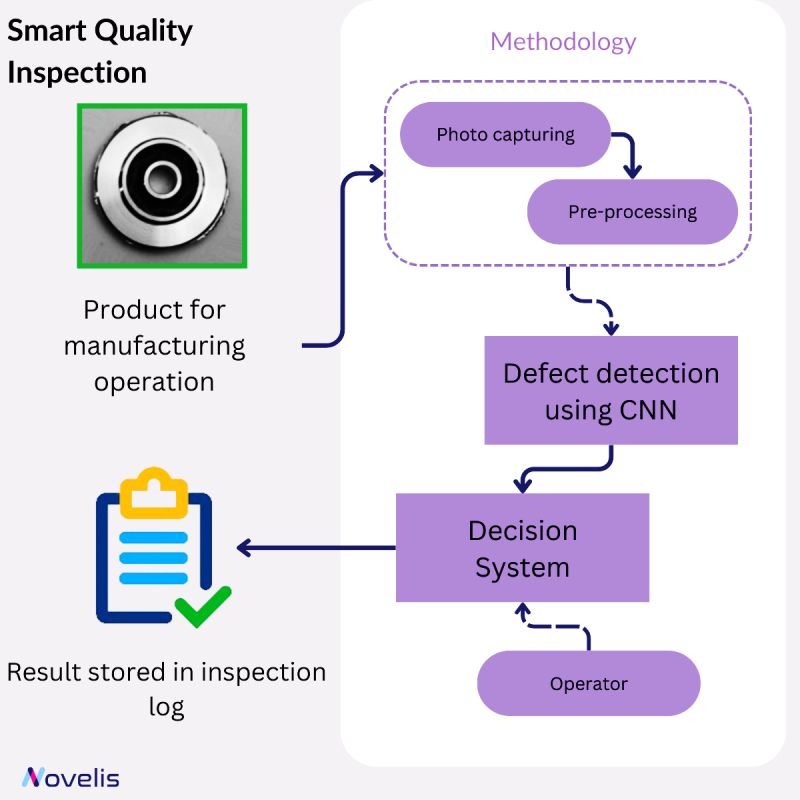
Quality inspection is one of the critical processes to ensure an optimal and low-cost manufacturing system. Human-operated quality inspection accuracy is around 80%. An AI-based approach could boost the accuracy of the visual inspection process up to 99.86%. Find out how:
The Smart Quality Inspection (SQI) process consists of six stages. The first stage involves bringing the product to the inspection area from the assembly line and placing it in a designated location. A high-quality camera captures images of the item during inspection. The lighting conditions and distance from the product are adjusted based on size and camera equipment, and any necessary image transformation is done at this stage. The next stage involves using a custom Convolutional Neural Network (CNN) architecture to detect defects during the AI-based inspection. The CNN architecture can handle different types of images with minimal modifications, and it is trained on images of defective and non-defective products to learn the necessary feature representations. The defect detection model is integrated into an application used on the shop floor to streamline the inspection process. During the inspection, the operator uses the defect detection algorithm, and based on the results, a decision is made on whether to accept or reject the product. The results of the inspection process are input into the SQI shop floor application and are automatically stored in a spreadsheet. This makes it easier for the team to track and analyze the results.
Why is this essential? This technology is crucial for monitoring the manufacturing environment’s health, preventing unforeseen repairs and shutdowns, and detecting defective products that could result in significant losses.
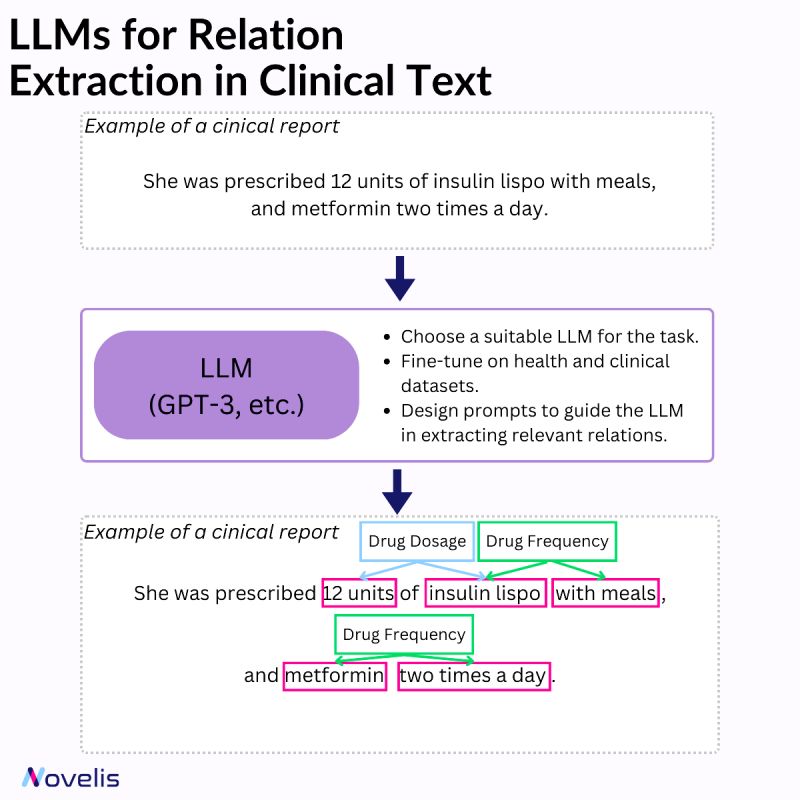
Clinical Insights: Leveraging LLMs for Relation Extraction in Clinical Text
Relation extraction involves identifying connections between named entities in text. In the clinical domain, it helps extract valuable information from documents such as diseases, symptoms, treatments, and medications. Various techniques can be used for named entity recognition and relation extraction (rule-based systems, machine learning approaches, and hybrid systems that combine both).
Large Language Models (LLMs) have significantly impacted the field of machine learning, especially in natural language processing (NLP). These models, which are trained on large amounts of text data, are capable of understanding and generating natural language text with impressive accuracy. They have learned to identify complex patterns and semantic relationships within language, can handle various types of entities, and can be adapted to different domains and languages. They can also capture contextual information and dependencies more efficiently and are capable of transfer learning. When combined with a set of prompt-based heuristics and upon fine-tuning them on clinical data, they can be particularly useful for named entity recognition and relation extraction tasks.
Why is this essential? By identifying the relationships between different entities, it becomes possible to gain a better understanding of how various aspects of a patient’s health are connected. This, in turn, can help in developing effective interventions. For instance, clinical decision support can be improved by extracting relationships among diseases, symptoms, and treatments from electronic health records. Similarly, identifying potential interactions between different medications can ensure patient safety and optimize treatment plans. Automating the medical literature review process can facilitate quick access to relevant information.
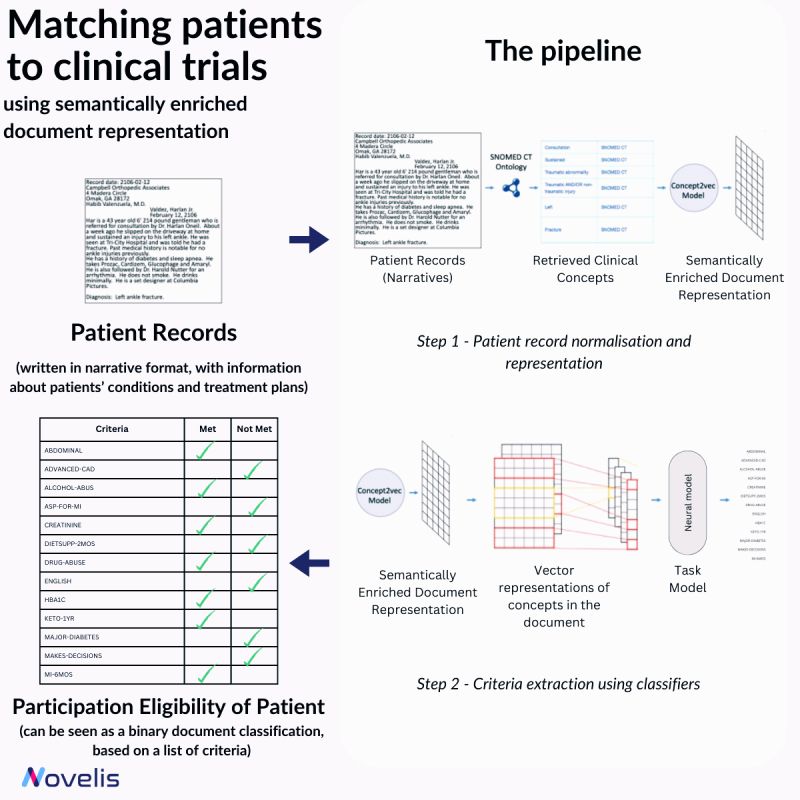
Matching patients to clinical trials
Matching Patients to Clinical Trials Using Semantically Enriched Document Representation
Recruiting eligible patients for clinical trials is crucial for advancing medical interventions. However, the current process is manual and takes a lot of time. Researchers ask themselves, “Which interventions lead to the best outcomes for a particular patient?” To answer this question, they explore scientific literature, match patients with potential trials, and analyze patient phenotypes to extract demographic and biomarker information from clinical notes. An approach presented in the paper “Matching Patients to Clinical Trials Using Semantically Enriched Document Representation” automates patient recruitment by identifying which patients meet the criteria for selection from a corpus of medical records.
This approach is utilized to extract important information from narrative clinical documents, gather evidence for eligibility decisions based on inclusion/exclusion criteria, and overcome challenges such as differences in reporting style with the help of semantic vector representations from domain ontologies. The SNOMED CT ontology is used to normalize the clinical documents, and the DBpedia articles are used to expand the concepts in SNOMED CT oncology. The team effectively overcame reporting style differences and sub-language challenges by enriching narrative clinical documents with domain ontological knowledge. The study involved comparing various models, and a neural-based method outperformed conventional machine learning models. The results showed an impressive overall F1-Score of 84% for 13 different eligibility criteria. This demonstrated that using semantically enriched documents was better than using original documents for cohort selection.
Why is this essential? This research is a significant step towards improving clinical trial recruitment processes. The automation of patient eligibility determination not only saves time but also opens avenues for more efficient drug development and medical research.
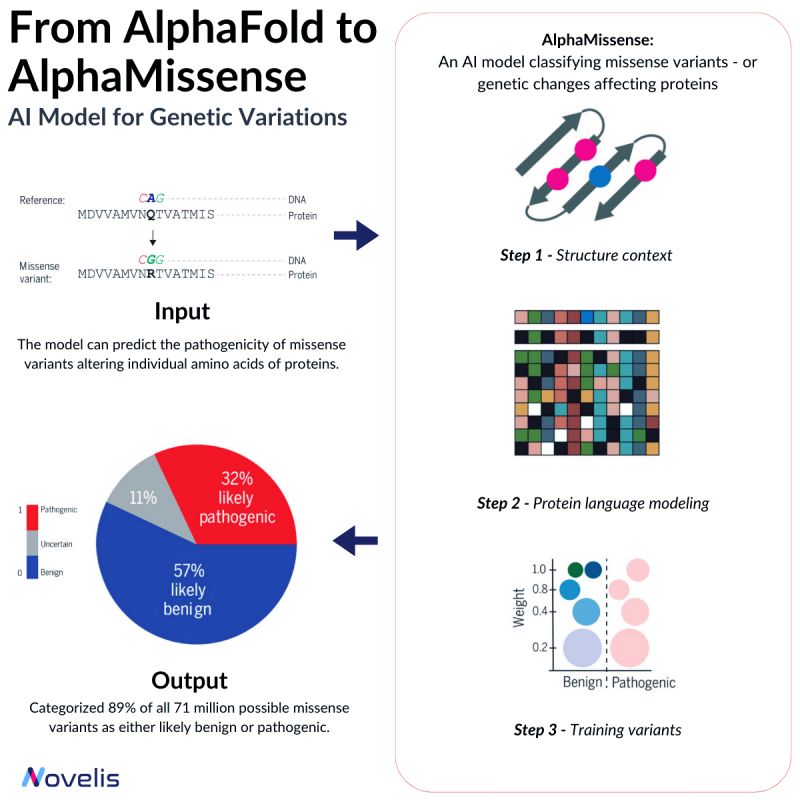
From AlphaFold to AlphaMissense
From AlphaFold to AlphaMissense: Models for Genetic Variations
Missense mutations are responsible for contributing to a number of diseases, such as Marfan Syndrome and Huntington’s Disease. These mutations cause a change in the sequence of amino acids in a protein, which can lead to unpredictable effects on the organism. Depending on their nature, missense mutations can either be pathogenic or benign. Pathogenic variants significantly affect protein function, causing impairment in overall organism behavior, whereas benign variants have minimal or no effect on organism behavior.
Why is this essential? Despite identifying over 4 million missense variants in the human genome, only around 2% have been conclusively labeled as either pathogenic or benign. The significance of the majority of missense variants is yet to be determined, making it difficult to predict their clinical implications. Hence, ongoing efforts aim to develop highly effective methods for accurately predicting the clinical implications of these variants.
The missense mutation problem shares similarities with the protein folding problem, both seeking to enhance explainability and predict outcomes related to variations in the amino acid structure. In 2018, DeepMind and EMBL-EBI launched AlphaFold, a groundbreaking protein structures prediction model. Alphafold facilitates the prediction of protein structures from previously inaccessible amino acid sequences.
By leveraging the capabilities of Transfer Learning on binary labeled public databases (such as BFD, MGnify, and UniRef90), DeepMind proposes AlphaMissense, an AlphaFold finetune that achieves state-of-the-art predictions on ClinVar (a genetic mutation dataset) without the need for explicit training on such data.
The tool is currently available as a freely provided Variant Effect Predictor software plugin.
Meet GatorTronGPT, an advanced AI model developed by researchers at the University of Florida in collaboration with NVIDIA. This model transforms medical documentation, helping create precise notes. Its ability to understand complex medical language makes it a game-changer.
The language model was trained using the GPT-3 architecture. It was trained on a large amount of data, including de-identified clinical text from the University of Florida Health and diverse English text from the Pile dataset. GatorTronGPT was then employed to tackle two important biomedical natural language processing tasks: biomedical relation extraction and question answering.
A Turing test was conducted to evaluate the performance of GatorTronGPT. Here, the model generated synthetic clinical text paragraphs, and these were mixed with real-world paragraphs written by University of Florida Health physicians. The task was identifying which paragraphs were human-written and which were synthetic based on text quality, coherence, and relevance. Even experienced doctors could not differentiate between the generated and human-written paragraphs, which is a testament to the high quality of the GatorTronGPT output.
Powered by OpenAI’s GPT-3 framework, GatorTronGPT was trained on the supercomputer HiPerGator, with support from NVIDIA.
Why is this essential? By replicating the writing skills of human clinicians, GatorTronGPT allows healthcare professionals to save time, reduce burnout, and focus more on patient care.
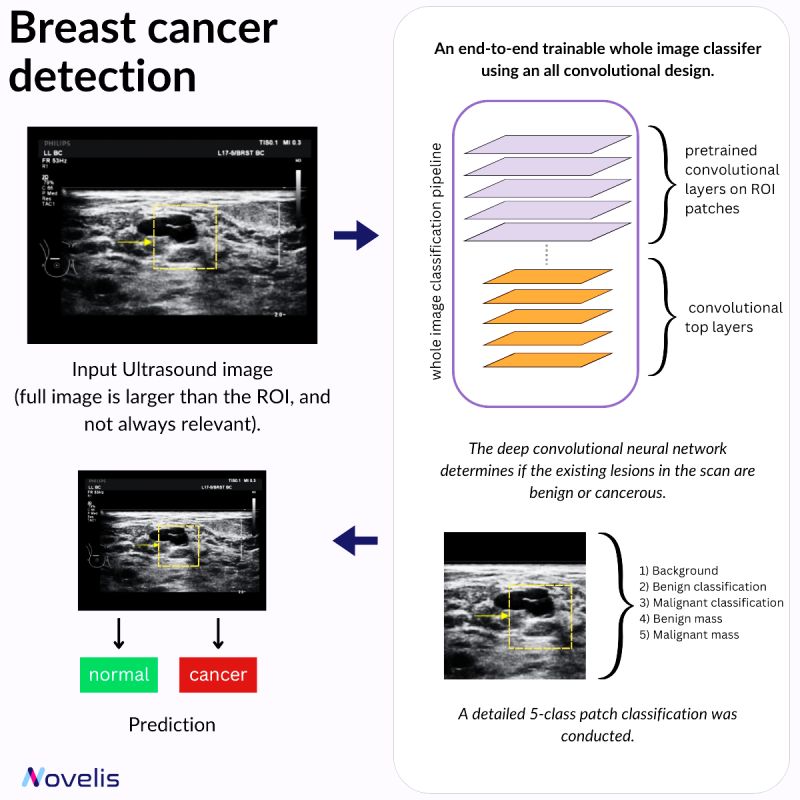
Deep Learning to Improve Breast Cancer Detection on Screening Mammography
Our focus this month is on how AI can be used in healthcare. This post will present a paper titled “Deep Learning to Improve Breast Cancer Detection on Screening Mammography” that covers an innovative deep-learning approach that aims to enhance breast cancer detection in screening mammography. A full-field digital mammography (FFDM) image typically has a resolution of 4000 x 3000 pixels, while a potentially cancerous region of interest (ROI) can be as small as 100 × 100 pixels. The method leverages these clinical ROI annotations to refine mammogram classification, which holds promise for significantly improving screening accuracy.
The technology utilizes an “end-to-end” training approach. It is trained on local image patches with detailed annotations and then adapts to whole images, requiring only image-level labels. This approach reduces dependence on detailed annotations, making it more versatile and scalable across various mammography databases.
Why is this essential? This paper is significant due to its potential to improve the accuracy of breast cancer detection in mammograms. It offers a more generalizable and scalable solution compared to traditional methods, reducing the risk of false positives and negatives. This approach could play a crucial role in early breast cancer detection and, therefore, help save lives by identifying cancer at more treatable stages.
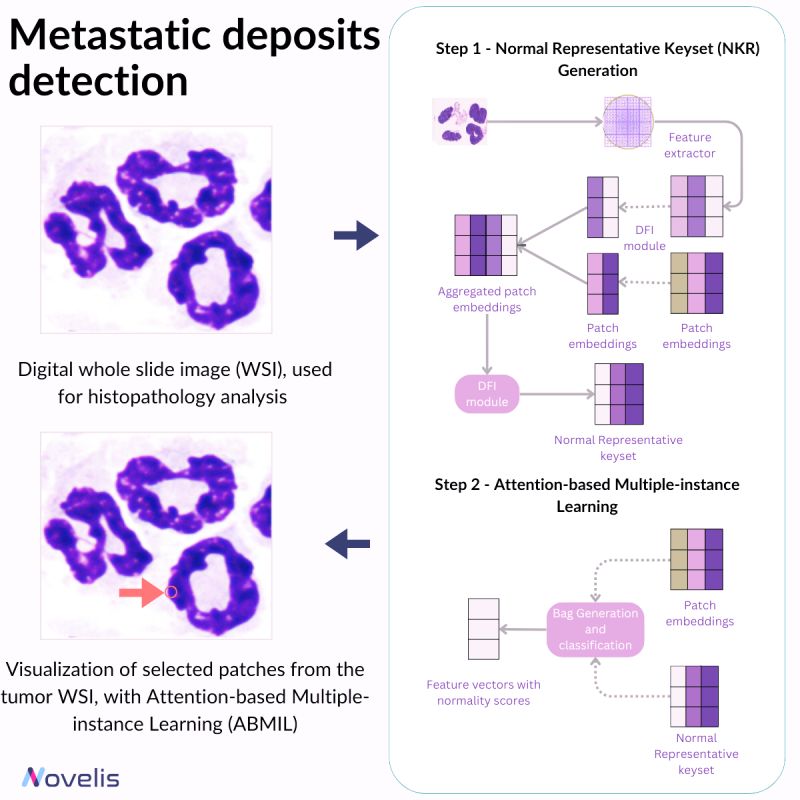
Metastatic deposits detection
Revolutionizing Cancer Diagnosis: The Vital Role of AI in Early Detection
Recent advancements in AI have significantly contributed to cancer research, particularly in analyzing histopathological imaging data. This reduces the need for extensive human intervention. In breast cancer, early detection of lymph node metastasis holds paramount importance, especially in the case of smaller tumors. Early diagnosis plays a crucial role in determining the treatment outcome. Pathologists often face difficulties in identifying tiny or subtle metastatic deposits, which leads to greater reliance on cytokeratin stains for improved detection. However, this method has inherent limitations and can be improved upon. This is where deep learning comes in as a vital alternative to address the intricacies of detecting small tumors early.
A notable approach within deep learning is the normal representative keyset attention-based multiple-instance learning (NRK-ABMIL). This technique consists of fine-tuning the attention mechanism to prioritize the detection of lesions. To achieve it, NRK-ABMIL establishes an optimal keyset of normal patch embeddings, referred to as the normal representative keyset.
Why is this essential? It is important to continue the research in whole slide images (WSIs) methods, with a particular emphasis on enhancing the detection of small lesions more precisely and accurately. This pursuit is crucial because advancing our understanding and refinement of WSIs can significantly impact early diagnosis and treatment efficacy.
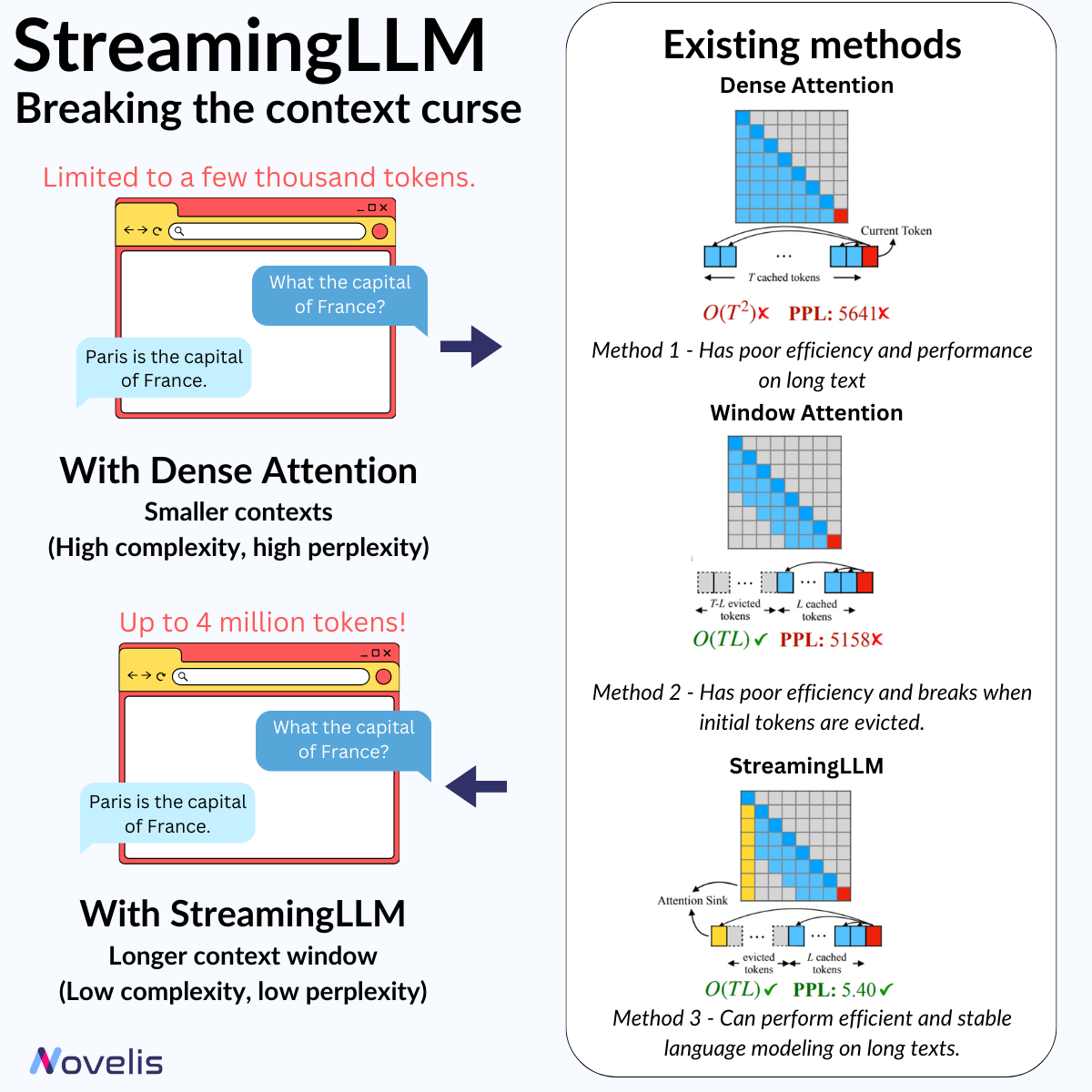
Have you ever had a lengthy conversation with a chatbot (such as ChatGPT), only to realize that it has lost track of previous discussions or is no longer fluent? Or you’ve faced a situation where the input limit has been exhausted when using language model providers’ APIs. The main challenge with large language models (LLMs) is the context length limitation, which prevents us from having prolonged interactions with them and utilizing their full potential.
Researchers from the Massachusetts Institute of Technology, Meta AI, and Carnegie Mellon University have released a paper titled “Efficient Streaming Language Models With Attention Sinks”. The paper introduces a new technique for increasing the input lengths of LLMs without any loss in efficiency or performance degradation, all without model retraining.
The StreamingLLM framework stores the initial four tokens (called “sinks”) in a KV Cache as an “Attention Sink” on the already pre-trained models like LLaMA, Mistral, Falcon, etc. These crucial tokens effectively address the performance challenges associated with conventional “Window Attention” in LLMs, allowing them to extend their capabilities beyond their original input length and cache size limits. Using the StreamingLLM framework can help reduce both the perplexity (which measures how well a model predicts the next word based on context) and the computational complexity of the model.
Why is this important? This technique expands current LLMs to model sequences of over 4 million tokens without retraining while minimizing latency and memory footprint compared to previous methods.
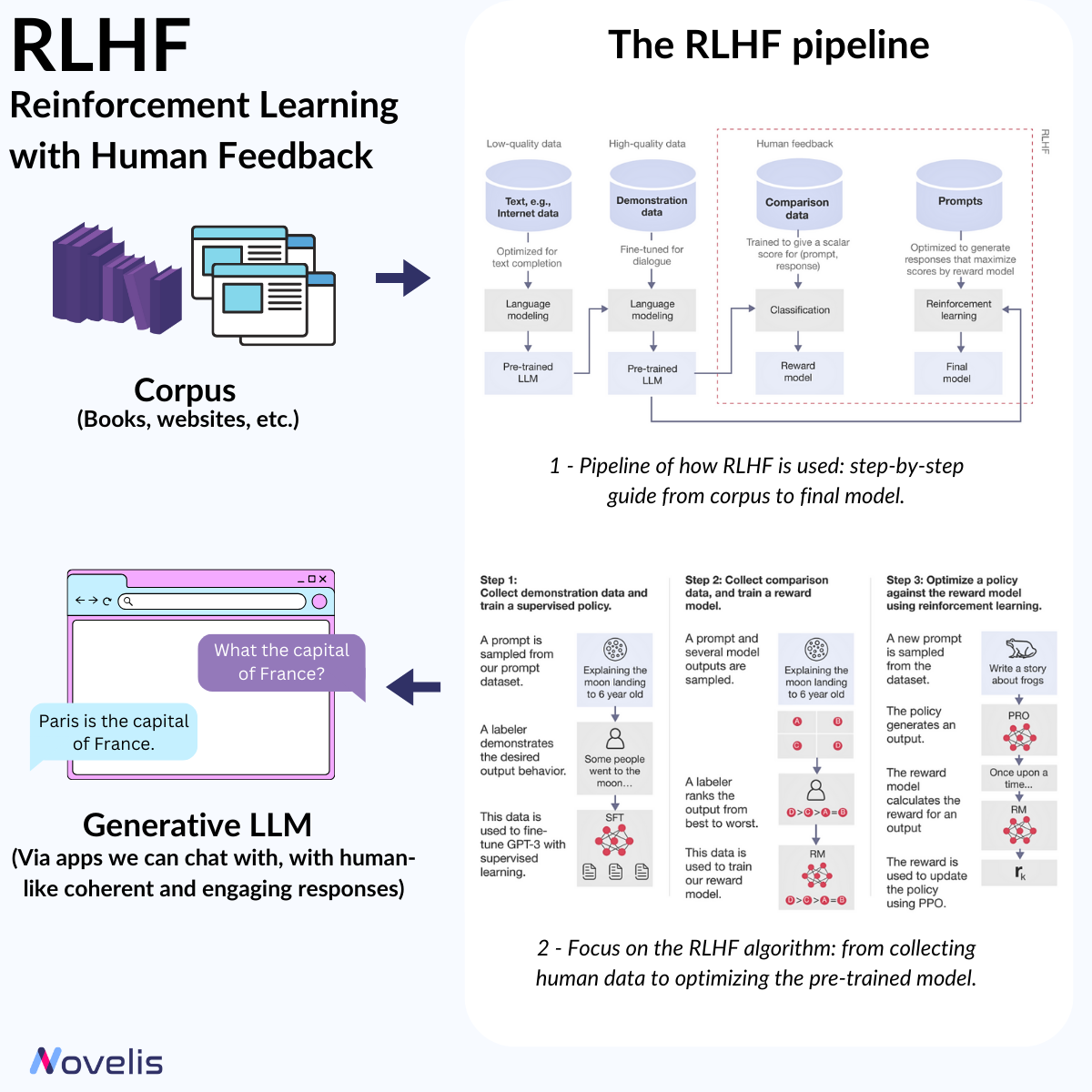
RLHF : adapt AI models with human input
Unlocking the Power of Reinforcement Learning from Human Feedback for Natural Language Processing
Reinforcement Learning from Human Feedback (RLHF) is a significant breakthrough in Natural Language Processing (NLP). It allows machine learning models to be refined using human intuition, leading to more contextually aware AI systems. RLHF is a machine learning method that adapt AI models (here, LLMs) using human input. The process involves creating a “reward model” based on human feedback, which is then used to optimize the behavior of an AI agent through reinforcement learning algorithms. Simply put, RLHF helps machines learn and improve by using the insights of human evaluators. For instance, an AI model can be trained to generate compelling summaries or engage in meaningful conversations using RLHF. The technique collects human feedback, often in the form of rankings or preferences, to create a reward model. This model helps the AI agent distinguish between good and bad outcomes and subsequently undergoes fine-tuning to align its behavior with the preferences identified in the human feedback. The result is more accurate, nuanced, and contextually appropriate responses.
OpenAI’s ChatGPT is a prime example of RLHF’s implementation in natural language processing applications.
Why is this essential? A clear understanding of RLHF is crucial to understanding the evolution of NLP and LLM and how they offer coherent, engaging, and easy-to-understand responses. RLHF helps AI models align with human values, providing answers that align with our preferences.
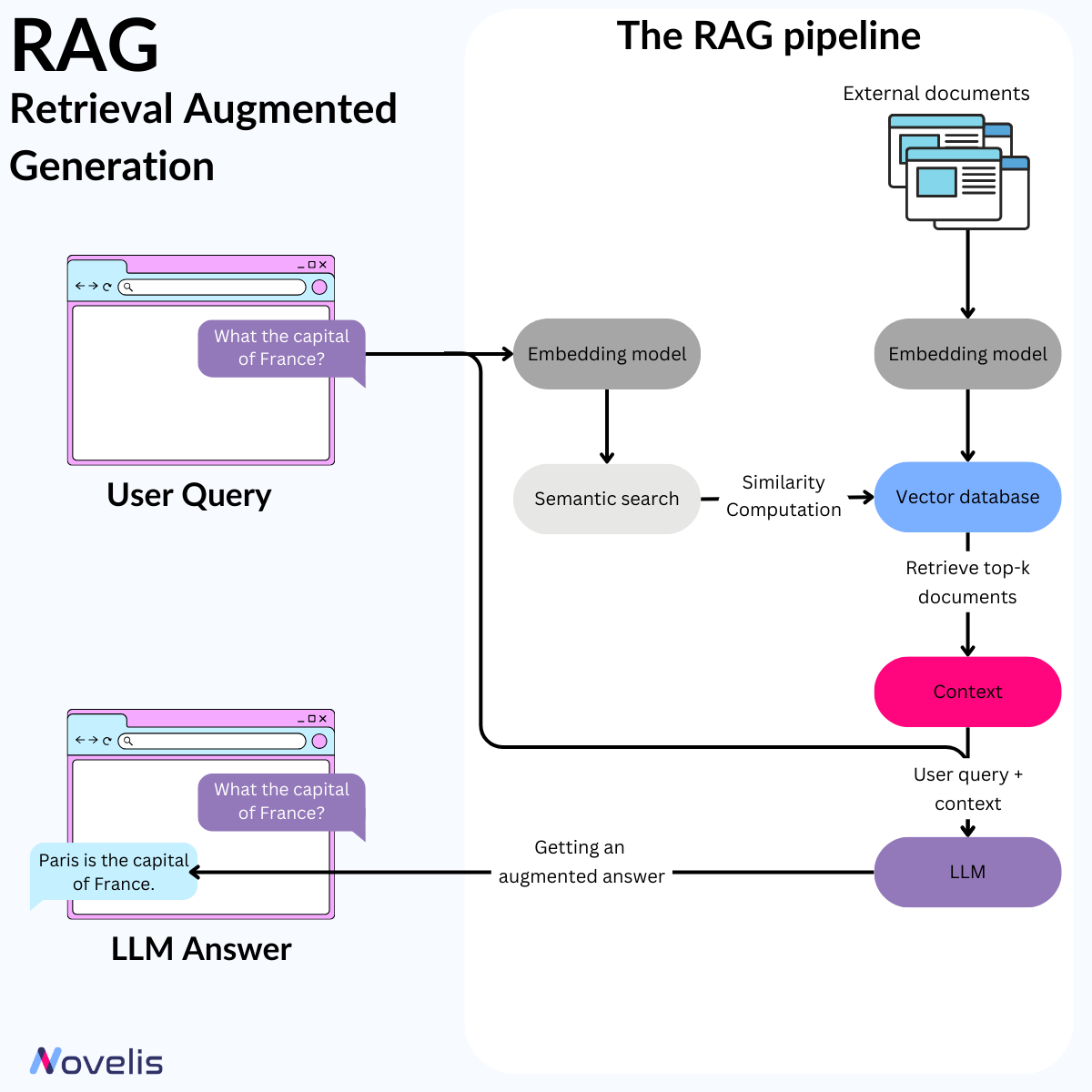
RAG : combine LLMs with external databases
The Surprisingly Simple Efficiency of Retrieval Augmented Generation (RAG)
Artificial intelligence is evolving rapidly, with large language models (LLMs) like GPT-4, Mistral, Llama, and Zephyr setting new standards. Although these models have improved interactions between humans and machines, they are still limited by existing knowledge. In September 2020, Meta AI introduced an AI framework called Retrieval Augmented Generation (RAG), which resolves some issues previously encountered by LMs and LLMs. RAG is designed to enhance the quality of responses generated by LLMs by incorporating external sources of knowledge and enriching the LLMs’ internal databases with accurate and up-to-date information. RAG is an AI system that combines LLMs with external databases to provide accurate and up-to-date answers to queries.
RAG has undergone continual refinement and integration with diverse language models, including the state-of-the-art GPT-4 and Llama 2.
Why is this essential? Reliance on potentially outdated data and a predisposition to generate inaccurate or misleading information are common issues faced by LLMs. However, RAG effectively addresses these problems by ensuring factual accuracy and consistency. It significantly mitigates the risks associated with data integrity breaches and dissemination of erroneous information. Moreover, RAG has displayed prowess across diverse benchmarks such as Natural Questions, WebQuestions, and CuratedTrec. This exemplifies its robustness and reliability. By integrating RAG, the need for frequent model retraining is reduced. This, in turn, reduces the computational and financial resources required to maintain LLMs.
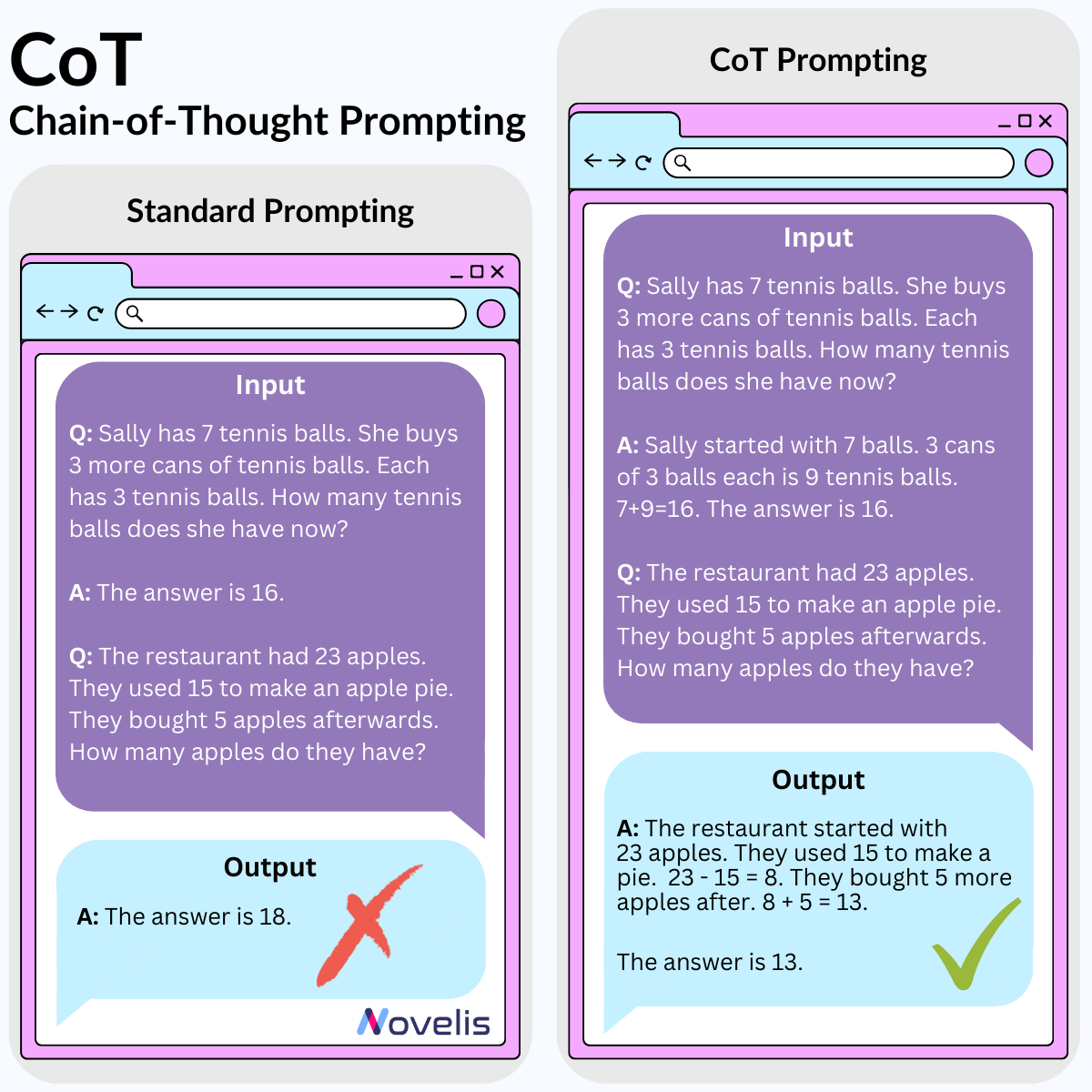
CoT : design the best prompts to produce the best results
Chain-of-Thought: Can large language models reason?
This month, we’ve been diving into the fascinating world of language modeling and generative AI. Today, we’ll be discussing on how to better use these LLMs. Ever heard of prompt engineering? This is the field of research dedicated to the design of better prompts in order for the large language model (LLM) you’re using to return the very best results. We’ll be introducing one such prompt engineering technique: Chain-of-Thought (CoT).
CoT prompting is a simple method that very closely resembles the way in which humans go about solving complex problems. If a problem seems a little long or a little too complex, we often tend to break that problem down into smaller sub-problems that we can more easily reason about. Well turns out this method works pretty well when replicated within (really) large language models (like GPT, BARD, PaLM, etc.). Give the model a couple examples of similar problems, explain how you’d handle them in plain language and that’s all! This works great for arithmetic problems, commonsense, and symbolic reasoning (aka good ol’ fashioned AI like rule-based problem solving).
Why is this essential? Applying CoT prompting has the potential to produce better results when handling arithmetic, commonsense, or rule-based problems when using your LLM of choice. It also helps to figure out where your LLM might be going wrong when trying to solve a problem (though the why of this question remains unknown). Try it out yourself! Now does this prove that our LLMs can really reason? That remains the million-dollar question.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.

![[Webinar] Take the Guesswork Out of Your Intelligent Automation Initiatives with Process Intelligence](https://novelis.io/wp-content/uploads/2024/09/ENG.png)