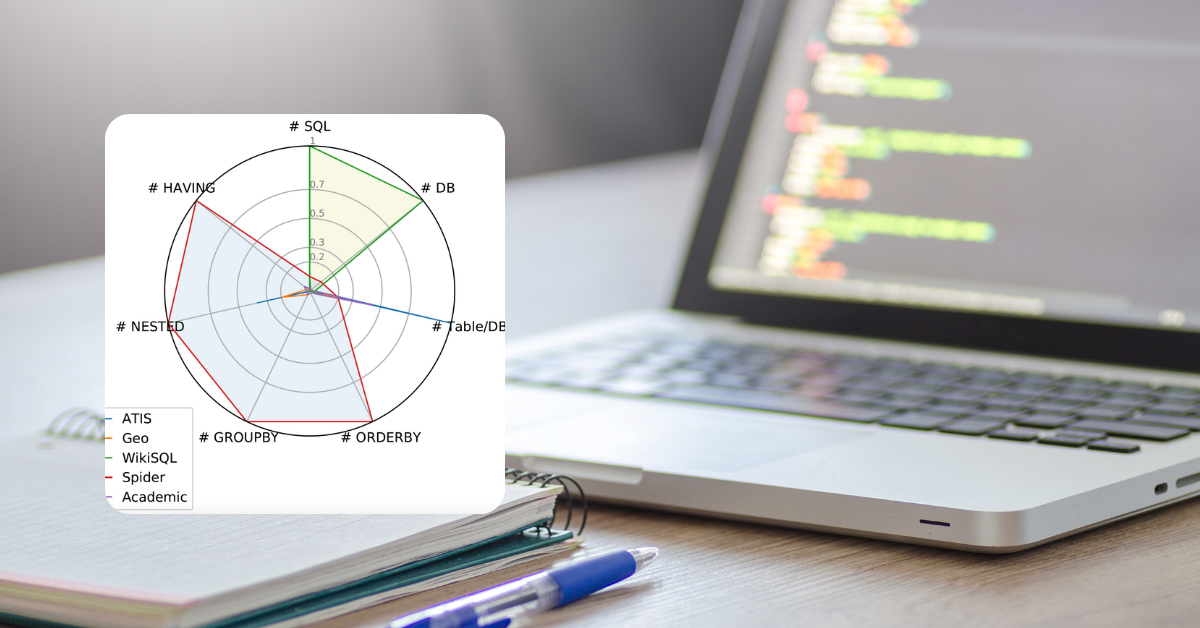
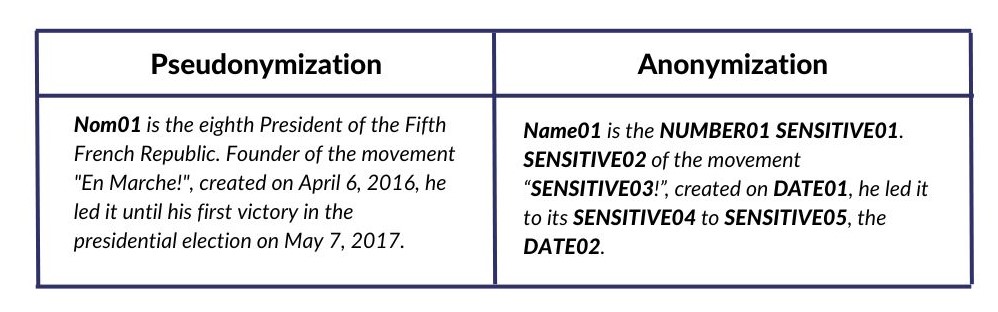
GPT-4, released by OpenAI in 2023, is the language model that holds one of the largest neural networks ever created, far beyond the language models that came before it. It is also the latest large multimodal model capable of processing images and text as input and producing text as output. Not only does GPT-4 outperform existing models by a considerable margin in English, but it also demonstrates great performance in other languages. GPT-4 is an even more powerful and sophisticated model than GPT-3.5, showing unparalleled performance in many NLP (natural language processing) tasks, including translation and Q&A.
In this article, we present the ten Large Language Models (LLMs) that have had a significant impact on the evolution of NLP in recent years. These models have been specifically designed to tackle various tasks in the Natural Language Processing (NLP), such as question answering, automatic summarization, text-to-code generation, and more. For each model, we have provided an overview of its strengths and weaknesses as compared to other models in its category.
A LLM (Large Language Model) model is trained on a large corpus of text data, designed to generate text like humans. The emergency of LLMs such as GPT-1 (Radford et al., 2018) and BERT (Devlin et al., 2018) was a breakthrough for artificial intelligence.
The first LLM, developed by OpenAI, is GPT-1 (Generative Pretrained Transformer) in 2018 (Radford et al., 2018). It is based on Transformer (Vaswani et al., 2017) neural network, but it has 12 layers and 768 hidden units per layer. The model was trained to predict the next token in a sequence, given the context of the previous tokens. GPT-1 is capable of performing a wide range of language tasks, including answering questions, translating text, and generating creative writing. Since it is the first LLM, GPT-1 has some limitations, for example:
- Bias- GPT-1 is trained on a large corpus of text data, which can introduce biases into the model;
- Lack of common sense: being trained from texts it has difficulties in linking knowledge to some form of understanding of the world;
- Limited interpretability: since it has millions of parameters, it is difficult to interpret how it makes decisions and why it generates certain outputs.
In the same year as GPT-1, Google IA introduced BERT (Bidirectional Encoder Representations from Transformers). Unlike GPT-1, BERT (Devlin et al., 2018) focused on pre-training the model on a masked language modeling task, where the model was trained to predict missing words in a sentence given the context. This approach allowed BERT to learn rich contextual representations of words, which led to improved performance on a range of NLP tasks, such as sentiment analysis and named entity recognition. BERT shares with GPT-1 some limitations, for example, the lack of common sense knowledge about the world, and the limitation in the interpretability to know how it takes decisions and the reason behind to generate some outputs. Moreover, BERT only uses a limited context to make predictions, which can result in unexpected or nonsensical outputs when the model is presented with new or unconventional information.
In the early 2019, surged the third LLM introduced by OpenAI, known as GPT-2 (Generative Pretrained Transformer 2). GPT-2 (Radford et al., 2019) was designed to generate coherent and human-like text by predicting the next word in a sentence based on the preceding words. Its architecture is based on a transformer neural network, similar to its predecessor GPT-1, which uses self-attention to process input sequences. However, GPT-2 is a significantly larger model than GPT-1, with 1.5 billion parameters compared to GPT-1’s 117 million parameters. This increased size enables GPT-2 to generate higher quality text and perform well on a wide range of natural language processing tasks. Additionally, GPT-2 can perform a wider range of tasks, such as summarization, translation, and text completion, compared to GPT-1. However, one limitation of GPT-2 is its computational requirements, which can make it difficult to train and deploy on certain hardware. Additionally, some researchers have raised concerns about the potential misuse of GPT-2 for generating fake news or misleading information, leading OpenAI to initially limit its release.
GPT-2 has been followed by other models such as XLNet and RoBERTa. XLNet (Generalized Autoregressive Pretraining for Language Understanding) was introduced by Google IA. XLNet (Yang et al., 2019) is a variant of the Transformer-based architecture. XLNet is different from traditional
Transformer-based models, such as BERT and RoBERTa, because it uses a permutation-based training method that allows the model to consider all possible word orderings in a sequence, rather than just a fixed left-to-right or right-to-left order. This approach leads to improved performance on NLP tasks such as text classification, question answering, and sentiment analysis. It has state-of-the-art results of NLP benchmark datasets, but like any other model has some limitations. For instance, it has a complex training algorithm (it uses a permutation-based training algorithm), and it needs a large amount of high-quality, diverse training data to perform well.
Simultaneously, RoBERTa (Robustly Optimized BERT Pretraining Approach) was also introduced in 2019, but by Facebook AI. RoBERTa (Liu et al., 2019) improves upon BERT by training on a larger corpus of data, dynamic masking , and training with the whole sentence, rather than just the masked tokens. These modifications lead to improved performance on a wide range of NLP tasks, such as question answering, sentiment analysis, and text classification. RoBERTa is a highly performance LLM, but it has also some limitations. For example, since RoBERTa has a large number of parameters, the inference can be slow; the model is has better proficiency in English, but it does not have the same performance in other languages.
Few months later, Salesforce Research Team released CTRL (Conditional Transformer Language Model). CTRL (Keskar et al., 2019) is designed to generate text conditioned on specific prompts or topics, allowing it to generate coherent and relevant text for specific tasks or domains. CTRL is based on a transformer neural network, similar to other large language models such as GPT-2 and BERT. However, it also includes a novel conditioning mechanism, which allows the model to be fine-tuned for specific tasks or domains. One advantage of CTRL is its ability to generate highly relevant and coherent text for specific tasks or domains, thanks to its conditioning mechanism. However, one limitation of its that it may not perform as well as more general-purpose language models on more diverse or open-ended tasks. Moreover, the conditioning mechanism used by CTRL may require additional preprocessing steps or specialized knowledge to set up effectively.
In the same month as CTRL model, NVIDIA introduced MEGATRON-LM (Shoeybi et al., 2019). MEGATRON-LM is designed to be highly efficient and scalable, enabling researchers and developers to train massive language models with billions of parameters using distributed computing techniques. Its architecture is similar to other large language models such as GPT-2 and BERT. However, Megatron-LM uses a combination of model parallelism and data parallelism to distribute the workload across multiple GPUs, allowing it to train models with up to 8 billion parameters. However, one limitation of Megatron-LM is its complexity and high computational requirements, which can make it challenging to set up and use effectively. Additionally, the distributed computing techniques used by Megatron-LM can introduce additional overhead and communication costs, which can affect training time and efficiency.
Subsequently, a few months later, Hugging Face developed a model called DistilBERT (Aurélien et al., 2019). DistilBERT is a light version of BERT model. It was designed to provide a more efficient and faster alternative to BERT, while still retaining a high level of performance on a variety of NLP tasks. The model is able to achieve up to 40% smaller model sizes and 60% faster inference times compared to BERT, without sacrificing much of its performance accuracy. DistillBERT can perform well in tasks such as sentiment analysis, question answering, and named entity recognition. However, DistillBERT does not perform as well on some NLP tasks as BERT. As well, it has been pre-trained on a smaller dataset compared to BERT, which limits its ability to transfer its knowledge to new tasks and domains.
Simultaneously, Facebook AI released BART (Denoising Autoencoder for Regularizing Translation) in June 2019. BART (Lewis et al., 2019) is a sequence-to-sequence (Seq2Seq) pre-trained model for natural language generation, translation, and comprehension. BART is a denoising autoencoder that uses a combination of denoising objectives in the pre-training. The denoising objectives help the model to learn robust representations. BART has limitations for multi-language translation, its performance can be sensitive to the choice of hyperparameters, and finding the optimal hyperparameters can be a challenge. Additionally, the autoencoder of BART has limitations, such as a lack of ability to model long-range dependencies between input and output variables.
Finally, we highlight the T5 (Transfer Learning with a Unified Text-to-Text Transformer) model, which was introduced by Google AI. T5 (Raffel et al., 2020) is a sequence to-sequence transformer-based. It uses the MSP (Masked Span Prediction) objective in the pre-training, which it consists in randomly masking spans of text with arbitrary lengths. Later, the model predicts the masked spans. Although T5 achieved results in the state of the art, T5 is designed to be a general-purpose text-to-text model, which can sometimes result in predictions that are not directly relevant to a specific task or are not in the desired format. Moreover, T5 is a large model, and it requires a high memory usage, and sometimes takes long time in the inference.
In this article, we have point out the pros and cons of the ten groundbreaking LLMs that have emerged over the last five years. We have also delved into the architectures that these models were built upon, showcasing the significant contributions they have made in advancing the NLP domain.