4 Juin , 2025 read
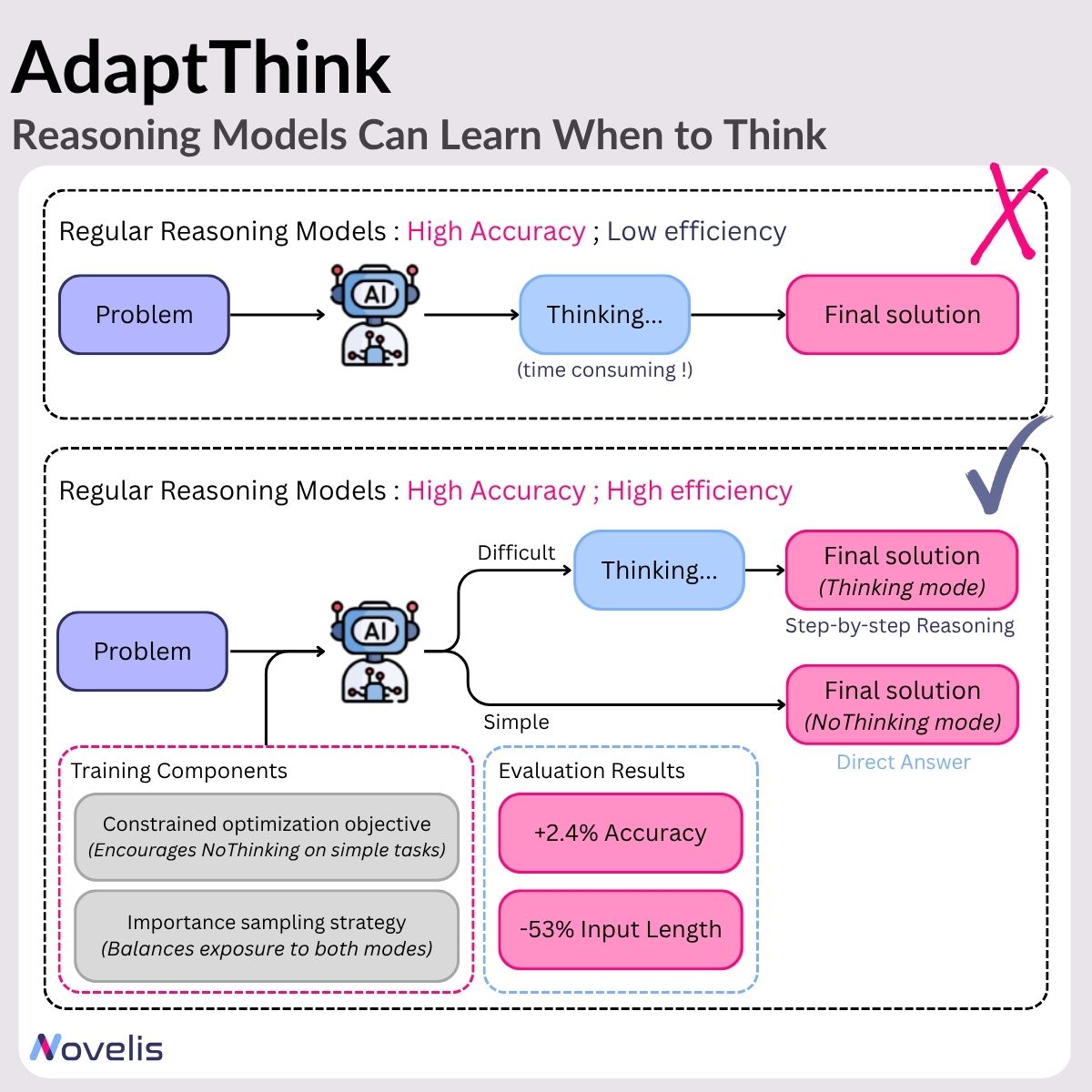
Les grands modèles de raisonnement (LRMs) ont montré des performances impressionnantes en générant des étapes intermédiaires détaillées avant de produire une réponse (un processus souvent qualifié de « réflexion »). Cela améliore les résultats sur les tâches complexes, mais engendre aussi une lourde charge computationnelle, en particulier pour les problèmes simples où une telle réflexion est superflue. En résumé : ces modèles ont tendance à sur-réfléchir, même pour des questions faciles, gaspillant temps et ressources.
AdaptThink est un cadre basé sur l’apprentissage par renforcement qui apprend aux LRMs à choisir dynamiquement entre deux modes de raisonnement, selon la difficulté du problème :
Mode Thinking : engage un raisonnement pas à pas
Mode NoThinking : saute les étapes intermédiaires et donne directement la réponse
Ce cadre repose sur deux éléments clés :
- Un objectif d’optimisation contraint, qui pousse le modèle à privilégier le mode NoThinking pour les tâches simples, tout en maintenant une précision globale ;
- Une stratégie d’échantillonnage par importance, garantissant une exposition équilibrée aux deux modes pendant l’entraînement, pour un apprentissage efficace et diversifié.
Les auteurs ont évalué AdaptThink sur trois jeux de données de raisonnement mathématique, en utilisant le modèle DeepSeek-R1-Distill-Qwen-1.5B. Les principaux résultats sont :
- Gains d’efficacité : réduction de 53 % de la longueur moyenne des réponses, en limitant la réflexion inutile
- Gains de performance : amélioration de 2,4 % de la précision, prouvant que l’efficacité accrue ne nuit pas à la justesse
Ces résultats suggèrent qu’AdaptThink peut gérer efficacement le compromis entre profondeur de raisonnement et efficacité computationnelle.
⚠️ Quelques limites à noter : pour l’instant, le cadre n’a été testé que sur des problèmes mathématiques, donc son potentiel de généralisation à d’autres types de tâches reste à prouver. De plus, comme il repose sur l’apprentissage par renforcement, son entraînement est plus complexe et coûteux que les approches classiques.
Pour aller plus loin :
📄 AdaptThink: Reasoning Models Can Learn When to Think
📄 Thinkless: LLM Learns When to Think