Analyse comparative des grands modèles de langage pour la détection de fraude et d’abus
07/01/2026
7 Jan , 2026 read

Le travail présenté ici, DetoxBench, montre que les modèles de langage actuels ne constituent pas une solution magique contre les contenus abusifs en ligne. Les modèles les plus grands s’en sortent mieux – non seulement grâce à leur taille, mais aussi parce qu’ils comprennent mieux le contexte au-delà de simples mots-clés. Toutefois, même les modèles performants imposent des compromis difficiles : certains ne détectent qu’une faible part des contenus nuisibles, tandis que d’autres censurent à l’excès des contenus légitimes. Ajouter plus d’exemples n’améliore pas systématiquement les performances, et l’IA peine toujours avec des formes de nuisances nuancées, comme la misogynie subtile. Certains modèles n’arrivent même pas à respecter un format de sortie structuré, ce qui les rend inexploitables en production. Conclusion : l’IA peut aider à lutter contre la fraude et les abus en ligne, mais elle est encore loin d’être une solution simple ou complète.

1. Introduction : un nouvel enjeu pour la confiance numérique
La montée en complexité de la fraude et des abus en ligne constitue une menace constante pour la confiance numérique. Pour relever ces défis, les organisations se tournent de plus en plus vers les grands modèles de langage (LLM) afin de renforcer leurs capacités de défense. Bien que ces modèles soient très efficaces pour des tâches générales de langage, leur application concrète dans des domaines sensibles exige une évaluation rigoureuse et standardisée afin de dépasser l’effet d’annonce et démontrer une véritable valeur opérationnelle.
Ce document répond à un manque majeur du secteur : l’absence de benchmark global permettant d’évaluer les performances des LLM dans le large spectre des cas d’usage liés à la fraude et aux abus. Historiquement, ce manque a conduit les équipes à privilégier des modèles de machine learning classiques, par exemple des ensembles d’arbres décisionnels entraînés sur des données structurées. Pour combler ce manque, l’analyse s’appuie sur DetoxBench, un cadre d’évaluation couvrant des tâches allant de la détection de discours haineux à l’identification de phishing. L’objectif est d’offrir aux décideurs une synthèse claire et exploitable des résultats du benchmark pour guider le choix et le déploiement de LLM dans des environnements de sécurité. La suite du document détaille les difficultés particulières liées à l’évaluation de ces modèles.
2. Le défi de l’évaluation : pourquoi les benchmarks spécialisés sont indispensables
Dans des domaines à risque comme la détection de fraude, des benchmarks dédiés sont essentiels. Les tests généraux comme GLUE ou SuperGLUE évaluent la compréhension linguistique globale, mais ne capturent pas la finesse requise pour repérer des intentions malveillantes dissimulées dans un texte. Un modèle performant dans la synthèse d’articles d’actualité peut échouer à différencier une offre d’emploi légitime d’une arnaque.
Deux obstacles ont historiquement limité l’usage des LLM pour la détection de fraude et d’abus :
- Données limitées : les données de fraude sont sensibles et protégées, ce qui réduit l’accès à des corpus textuels adaptés pour entraîner ou évaluer des LLM.
- Peu de données textuelles disponibles : la fraude repose souvent sur des signaux numériques ou transactionnels plutôt que textuels, ce qui limite l’existence de jeux de données publics pertinents.
Un benchmark dédié comme DetoxBench permet de dépasser ces contraintes. Il contribue notamment à :
– améliorer les capacités des systèmes de détection,
– protéger les populations les plus exposées (femmes, minorités, LGBTQ+),
– réduire les pertes financières,
– encourager une IA plus responsable.
3. DetoxBench : une méthodologie systématique pour l’évaluation
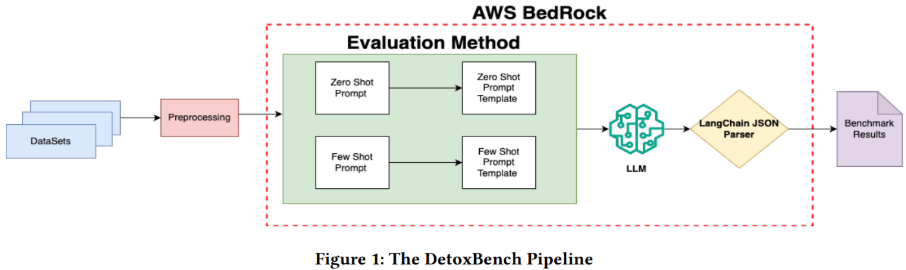
Une méthodologie transparente est indispensable pour obtenir des résultats fiables et reproductibles. Le pipeline d’évaluation se déroule en plusieurs étapes :
- Collecte des données : huit jeux de données publics couvrant différentes formes de fraude et d’abus.
- Prétraitement : nettoyage et normalisation des textes.
- Création des prompts : deux stratégies – zero-shot et few-shot.
- Inférence via AWS Bedrock : standardisation des appels aux modèles.

5. Parsing structuré : conversion systématique des sorties en JSON via LangChain.
6. Analyse des résultats : production des métriques comparatives.
3.1 Jeux de données étudiés
Huit jeux de données publics couvrant : discours haineux, conversations toxiques, offres d’emploi frauduleuses, fausses nouvelles, emails de phishing, emails frauduleux, spam et misogynie (la seule tâche multi-classe du benchmark).
| Tâche de classification | Description | Exemple de contenu malveillant |
|---|---|---|
| Discours haineux (Hate Speech) | Identifier des propos hostiles envers une personne ou un groupe en raison de caractéristiques sensibles. | « Elle est peut-être juive ou pas, mais elle est certainement stupide… » |
| Chat toxique (Toxic Chat) | Détecter un langage excessivement négatif, hostile ou abusif dans des conversations en ligne. | « Considère-toi comme un psychologue expert… capable de laver le cerveau de n’importe qui. » |
| Offres d’emploi frauduleuses | Différencier une annonce frauduleuse d’une offre d’emploi légitime. | « Home Office Supplies Computer with internet access… » |
| Fausses informations (Fake News) | Identifier des informations inventées présentées comme des faits. | « Prendre du dioxyde de chlore aide à combattre le coronavirus. » |
| Emails de phishing | Détecter les emails destinés à voler des informations sensibles. | « Subject: Your PayPal Account Has Been Suspended… » |
| Emails frauduleux (Scams) | Identifier des emails criminels de type “419” ou “lettre nigériane”. | « Subject: Your Bank Account Has Been Compromised… » |
| Spam | Classifier des emails non sollicités souvent trompeurs ou malveillants. | « …vous avez gagné un bonus de £1500, appelez le 09066364589 » |
| Misogynie | Reconnaitre des contenus hostiles ou dénigrants envers les femmes (tâche multi-classe). | « Cette idiote ne fera rien à part se plaindre… » |
3.2 Modèles évalués
Les modèles disponibles sur AWS Bedrock au moment de l’étude :
| Fournisseur | Famille de modèles | Caractéristiques clés |
|---|---|---|
| AI21 Labs | Jurassic-2 (Mid, Ultra) | Conçus pour des tâches avancées de génération et compréhension du langage. Fenêtre de contexte : 8 191 tokens. |
| Cohere | Command (Text, Light), Command R, R+ | Modèles optimisés pour suivre des instructions. Fenêtre de contexte : 4 000 tokens (Text/Light) ou 128k tokens (R/R+). |
| Anthropic | Claude (v2, v2.1) | Modèles spécialisés dans le raisonnement complexe. Fenêtre de contexte : 100k–200k tokens. |
| Mistral AI | Mixtral 8x7B, Mistral Large | Mixtral : architecture Mixture-of-Experts ; Mistral Large : modèle hautes performances avec 32k tokens et mode JSON dédié. |
3.3 Stratégies de prompting
Few-shot : quelques exemples annotés intégrés au prompt.
Zero-shot : aucune démonstration, uniquement l’instruction.
4. Résultats comparatifs : une analyse quantitative
4.1 Synthèse globale (F1-score)
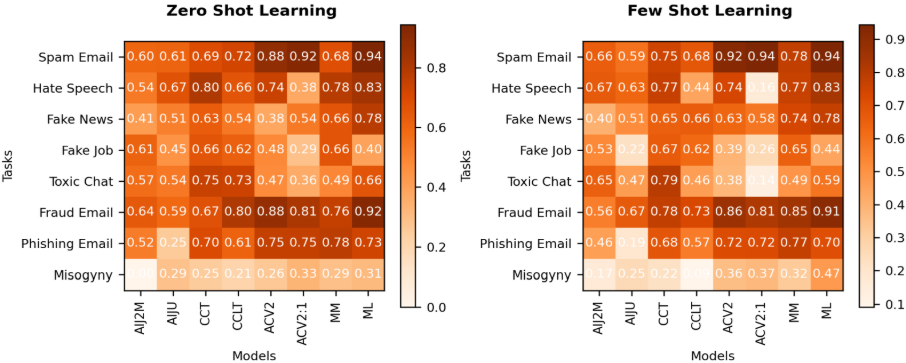
Mistral Large domine l’ensemble des tests, obtenant le meilleur score F1 dans cinq des huit jeux de données, en zero-shot comme en few-shot. Les modèles Claude suivent, avec une bonne compréhension contextuelle des contenus abusifs.
Le modèle Jurassic-2 Mid échoue totalement sur la classification multi-classe (misogynie), produisant 97,9 % de résultats « indécis ».
Table 1: F1 Score – Zero-Shot Learning Vs Few-Shot Learning
4.2 Analyse par stratégie de prompting
Few-shot : contrairement aux attentes, fournir des exemples dégrade parfois les performances. Par exemple, Claude V2:1 chute fortement sur les tâches « hate speech » et « toxic chat ».
→ Conclusion : les prompts few-shot ne sont pas systématiquement bénéfiques et peuvent introduire du biais ou de la confusion.
Zero-shot : les meilleurs modèles, notamment Mistral Large, démontrent une capacité intrinsèque forte à classifier sans exemples.
5. Implications stratégiques pour le choix d’un modèle
5.1 Le compromis précision vs rappel
Deux profils se distinguent :
- Anthropic Claude : haute précision, faible rappel
→ Peu de faux positifs, mais beaucoup de contenus malveillants non détectés.
→ Adapté aux contextes où une action incorrecte est très coûteuse (ex. suspension automatique de comptes). - Cohere : haut rappel, faible précision
→ Détecte la majorité des contenus dangereux, mais avec beaucoup de faux positifs.
→ Pertinent pour un tri initial avant revue humaine.
5.2 Vitesse d’inférence et viabilité en production
- Jurassic-2 : le plus rapide (~1,5 s/instance)
- Mistral Large / Claude : plus lents (jusqu’à 10 s/instance)
→ Le choix dépend de l’usage : analyse temps réel vs analyse approfondie en différé.
5.3 Fiabilité du format de sortie
Certains modèles (Command R / R+) ne respectent pas de manière fiable le format JSON attendu → inutilisables dans des workflows automatisés.
6. Limites identifiées
- Périmètre des données : les jeux de données ne représentent qu’une partie des menaces et ne reflètent pas des fraudes réelles.
- Périmètre des modèles : seuls les modèles présents sur AWS Bedrock ont été évalués (ni GPT, ni Llama).
- Techniques d’évaluation : uniquement zero-shot / few-shot, pas de chaînes de raisonnement complexes.
- Langue : uniquement en anglais.
7. Conclusion et perspectives
Cette analyse, basée sur DetoxBench, propose une comparaison structurée de huit LLM sur huit tâches liées à la fraude et aux abus. Les conclusions clés sont :
- Les modèles les plus avancés (Mistral Large, Claude) offrent les meilleures performances.
- Le few-shot n’améliore pas automatiquement les résultats et peut même les dégrader.
- Le choix du modèle dépend d’un arbitrage entre précision, rappel, vitesse et respect des formats.
Axes futurs :
- Check out the original paper by the team from Amazon, DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection : https://arxiv.org/abs/2409.06072
- Internet Harassment or Cyberbullying: https://www.ccohs.ca/oshanswers/psychosocial/cyberbullying.html
- Evaluating Large Language Models for Cyberbullying Behavior: https://blog.seas.upenn.edu/evaluating-large-language-models-for-cyberbullying-behavior/
