Analyse comparative des modèles Vision-Langage pour une reconnaissance des déchets à grande échelle
01/12/2025
1 Déc , 2025 read
Pourquoi l’automatisation devient indispensable dans la gestion des déchets
Le monde fait face à un défi croissant en matière de gestion des déchets. Avec l’augmentation des populations et le développement économique, la quantité de déchets municipaux produits chaque année devrait passer de juste au-dessus de 2 milliards de tonnes aujourd’hui à 3,4 milliards de tonnes d’ici 2050. Les systèmes traditionnels – basés sur la collecte routinière, le tri manuel et une forte dépendance aux décharges – ne parviennent plus à suivre le rythme. Ces pratiques dépassées entraînent des bacs qui débordent, des émissions inutiles liées aux véhicules de collecte et des risques environnementaux et sanitaires importants, allant de la pollution de l’eau à la propagation de maladies.
À consulter : Comment les robots pourraient sauver plus de 6 milliards de dollars de matériaux recyclables chaque année | AI in Action

Pour répondre à ces enjeux, l’automatisation devient un levier essentiel, notamment dans les centres de tri (MRF). Les systèmes robotisés équipés de capteurs avancés améliorent fortement l’efficacité, réduisent les coûts opérationnels et protègent les opérateurs des conditions dangereuses du tri manuel. Au cœur de ces systèmes se trouve la vision par ordinateur (CV), la technologie qui permet aux machines de reconnaître et classifier des matériaux sur un convoyeur.

TCe livre blanc compare deux grandes approches de vision par ordinateur pour la reconnaissance des déchets : les modèles unimodaux classiques (basés uniquement sur l’image) et la nouvelle génération de modèles multimodaux Vision-Langage (VLMs). Nous examinons leurs performances en zéro-shot, few-shot et apprentissage supervisé complet. Notre analyse montre que, si les modèles classiques atteignent de bonnes performances, leur dépendance à de vastes jeux d’images annotées limite fortement leur capacité à s’adapter à grande échelle. Les VLMs offrent une alternative flexible et scalable.
Nous commençons par une revue du cadre conventionnel de vision par ordinateur et de ses forces et limites.
L’approche conventionnelle : la vision par ordinateur unimodale pour la classification des déchets
Comprendre les méthodes actuelles est essentiel : ces systèmes unimodaux ont posé les bases de l’automatisation du tri. Depuis des années, ils permettent aux robots de prendre en charge des tâches de tri de plus en plus complexes. Mais les fondations techniques qui font leur force introduisent aussi des contraintes qui limitent leur adaptabilité dans l’environnement imprévisible d’un centre de tri.
Les modèles classiques reposent sur des architectures connues de deep learning comme les réseaux convolutifs (CNN) – par exemple ResNet – ou des Vision Transformers (ViT) modernes comme Swin Transformer. Ils sont généralement pré-entraînés sur de grands jeux d’images génériques (comme ImageNet) avant d’être adaptés sur des images de déchets. Une autre approche courante utilise des réseaux neuronaux (ANN) associés à des techniques d’extraction de caractéristiques (histogrammes de couleur, HOG, LBP…).
Avec suffisamment de données annotées, ces modèles offrent d’excellents résultats. Quelques performances rapportées :
| Architecture | Précision rapportée |
|---|---|
| ResNet18 (TrashNet) | 95,87 % |
| Swin Transformer (jeu de données interne) | 99,75 % |
| MobileNetV2 amélioré | 90,7 % |
| ANN avec fusion de caractéristiques | 91,7 % |
Malgré ces bons résultats, leur limite majeure est la quantité massive de données annotées requises, tant pour l’entraînement initial que pour les cycles fréquents de ré-entraînement. Les déchets réels sont beaucoup plus variés que les jeux d’images propres et bien catégorisés, ce qui oblige à réentraîner les modèles pour reconnaître de nouveaux matériaux, des déchets abîmés ou contaminés. Cette dépendance à une annotation continue constitue un frein majeur à l’évolutivité et à la rentabilité.
Ces obstacles ouvrent la voie à une alternative plus flexible : les modèles Vision-Langage.
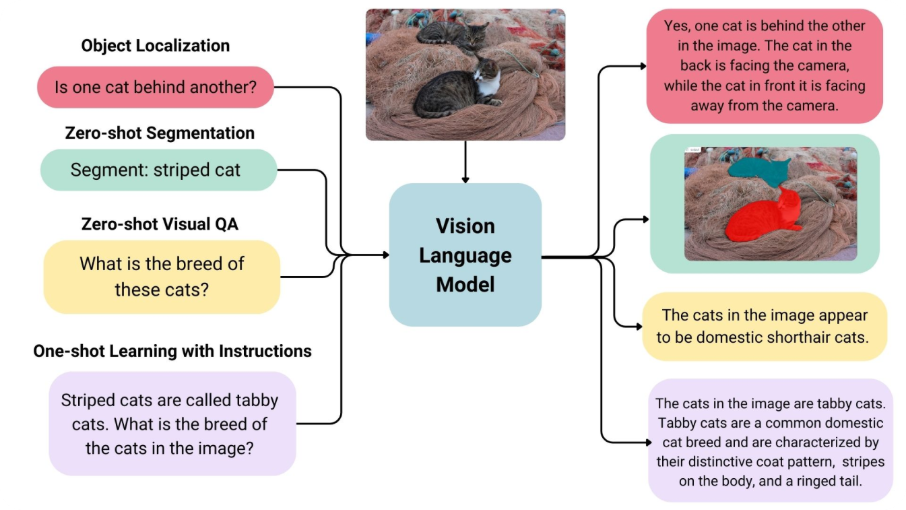
Un nouveau paradigme : les Vision-Language Models (VLMs)
Les VLMs représentent un changement important dans la manière dont les machines interprètent les images. Plutôt que d’apprendre uniquement à partir d’images, ils établissent un lien entre le visuel et le langage naturel. Cette approche multimodale leur confère une grande flexibilité pour reconnaître des objets même sans données annotées spécifiques.
Les VLMs reposent sur deux composants :
- un encodeur visuel (ViT ou CNN) qui convertit l’image en un embedding sémantique ;
- un encodeur texte (souvent un Transformer) qui transforme une description écrite en embedding textuel.
Grâce à l’apprentissage contrastif sur d’immenses jeux d’images–textes, des modèles comme CLIP, OpenCLIP ou MetaCLIP apprennent à rapprocher dans un même espace les images et textes correspondant.
La force du zéro-shot
Le principal avantage des VLMs est leur capacité à classer des objets sans aucun entraînement spécifique, uniquement à partir d’instructions textuelles. Le modèle :
- encode l’image ;
- encode des textes comme « photo d’une boîte en carton », « image d’une bouteille en plastique » ;
- calcule la similarité entre l’image et chaque description ;
- choisit la catégorie la plus proche.
Cela élimine la nécessité d’un jeu de données annoté pour les déchets et permet de classifier dès le premier usage.
Apprentissage supervisé efficace avec peu de données
Quand des données annotées existent, les VLMs restent performants : il suffit d’entraîner un simple classifieur linéaire sur les embeddings d’images. Cela réduit fortement les coûts de calcul par rapport au fine-tuning d’un modèle classique.
Performances comparées : précision, rapidité et passage à l’échelle
De bons résultats en zéro-shot
Sur un jeu de données multi-classe, OpenCLIP (ViT L/14-2B) atteint 82,71 % de précision en zéro-shot – sans avoir vu la moindre image annotée. Cette précision dépasse celle de modèles entraînés avec seulement dix exemples par classe.
Apprentissage rapide en few-shot et en supervisé complet
Avec quelques images annotées, les VLMs progressent vite. La précision augmente fortement entre 1 et 15 images par classe, puis se stabilise. En supervisé complet, OpenCLIP atteint 97,18 %, comparable aux modèles traditionnels les plus avancés mais avec un coût d’entraînement bien moindre.
Rapidité adaptée à l’industrie
Le tri est une activité en flux rapide. Un modèle doit fonctionner en temps réel. Une analyse Pareto montre qu’OpenCLIP (ViT L/14-2B) offre le meilleur compromis :
- 3,79 ms par image
- ~263 FPS, largement au-dessus des 30–60 FPS requis
Ce qui le rend utilisable sur des lignes industrielles rapides.
Améliorer les performances grâce au prompt engineering
Le prompt engineering est une méthode simple et efficace pour améliorer la précision d’un VLM sans ré-entraînement. Il consiste à reformuler les descriptions textuelles utilisées pour la classification :
- identifier les prompts faibles ;
- les affiner pour plus de clarté et de précision.
Exemple : « débris de verre » peut être trop vague, tandis que « photo d’un bocal en verre et de bouteilles » reflète mieux ce que la machine voit sur un convoyeur.
Sur OpenCLIP, cette optimisation a fait passer la précision zéro-shot de 82,71 % à 90,48 %, uniquement en ajustant le texte.
Cette méthode demande toutefois de l’itération : améliorer un prompt peut en dégrader un autre.
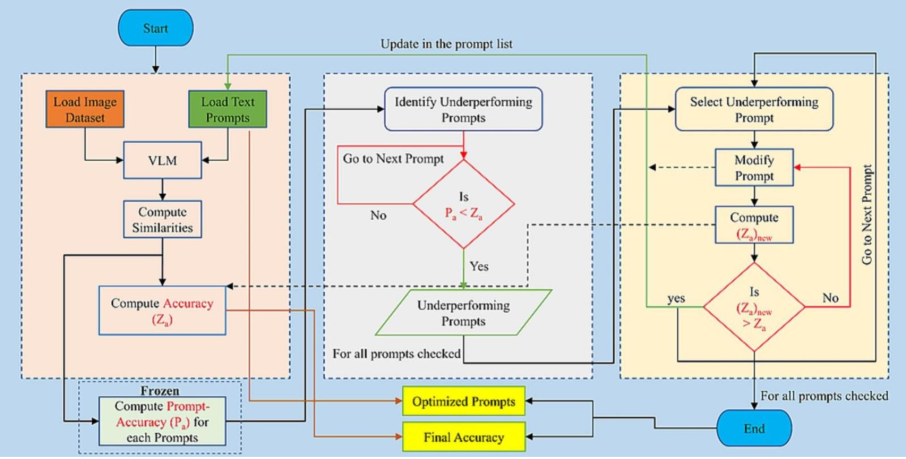
Figure : Schéma d’optimisation des prompts
Cependant, le travail sur les prompts doit être réalisé avec soin. Améliorer un prompt peut parfois réduire la précision d’autres, ce qui rend l’exercice délicat et nécessite de l’itération ainsi qu’une évaluation rigoureuse.
Jeux de données
Le jeu de données principal utilisé pour les tests dans les études citées est celui de Kumsetty et al. (2022). Sa partie test de 1 596 images sert de référence pour évaluer les modèles de classification des déchets en zéro-shot, few-shot et supervisé, y compris les modèles Vision-Langage (VLMs).
Il contient 14 310 images, réparties en six catégories : carton, e-déchets, verre, métal, papier et plastique.
La partie test est spécifiquement utilisée pour mesurer la précision en zéro-shot, analyser la capacité de généralisation et comparer les performances selon différents modes d’apprentissage.
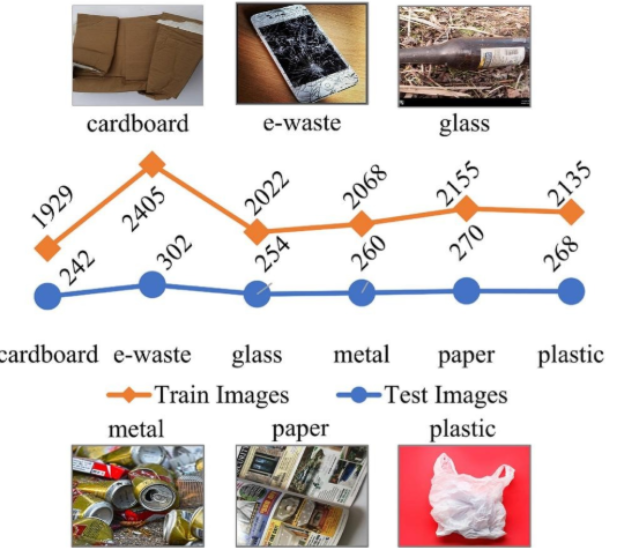
Figure : Exemples et répartition des images du dataset Kumsetty et al.
En complément de ce dataset central, plusieurs études mentionnent l’utilisation d’autres jeux de données dans leurs protocoles, bien qu’ils ne soient pas inclus dans l’évaluation zéro-shot des VLMs. Parmi eux :
Le Yang Trash Dataset (TrashNet), un benchmark largement utilisé pour tester des modèles ANN et ResNet dans la classification de déchets.
HUAWEI-40 : 14 683 images réparties en quatre grandes catégories, utilisé pour tester une version améliorée de MobileNetV2.
Un jeu de données manuel basé sur Stanford Trash/TrashNet, contenant 2 400 images capturées manuellement, utilisé pour évaluer une méthode de tri automatisé basée sur un ANN.

Figure : Exemple TrashNet
Perspectives et défis pour le déploiement en conditions réelles
Les Vision-Language Models offrent des avantages solides, mais leur déploiement industriel nécessite une analyse équilibrée des opportunités et des contraintes.
Atouts majeurs
- Scalabilité et adaptabilité : les VLMs réduisent fortement la dépendance aux jeux d’images annotées, ce qui facilite l’ajout de nouvelles catégories de déchets.
- Efficacité de calcul : l’apprentissage few-shot et supervisé demande bien moins de temps et d’énergie que les modèles traditionnels.
- Précision élevée de base : les capacités zéro-shot et le travail sur les prompts permettent d’obtenir de bonnes performances sans entraînement spécifique sur images.
Contraintes opérationnelles
- Charge liée au prompt engineering : l’affinage des prompts nécessite souvent des itérations manuelles et peut introduire des biais s’il n’est pas soigneusement contrôlé.
- Limites matérielles : les VLMs volumineux peuvent poser problème dans des environnements avec des ressources de calcul limitées ou des contraintes d’edge computing.
- Absence de datasets standardisés : le manque de jeux de données unifiés complique les comparaisons entre systèmes.
- Investissement initial : malgré les gains futurs, le coût d’installation de systèmes avancés de tri automatisé reste un frein pour de nombreux opérateurs.
Surmonter ces obstacles sera déterminant pour une adoption à grande échelle.
Conclusion : l’avenir de la reconnaissance automatisée des déchets
Les systèmes classiques de vision par ordinateur offrent de bonnes performances, mais leur dépendance à des volumes importants de données soigneusement annotées crée des blocages importants. Cette contrainte ralentit et renchérit l’adaptation des centres de tri face à l’évolution des flux de déchets.
Les modèles Vision-Langage constituent une alternative solide. Leur flexibilité en zéro-shot, leur efficacité en apprentissage supervisé et les gains obtenus via le prompt engineering répondent directement aux limites des approches traditionnelles. En combinant image et langage, ils permettent de développer des systèmes de tri plus adaptatifs, plus performants et plus économes.
Les VLMs représentent ainsi une avancée technologique majeure. Leur capacité d’adaptation et leur efficacité en font un outil clé pour concevoir la prochaine génération de systèmes automatisés, capables d’accompagner la transition vers une économie circulaire.
Plus d’articles
- AMP Robotics raises $55 million for AI that picks and sorts recyclables : https://venturebeat.com/ai/amp-robotics-raises-55-million-for-ai-that-picks-and-sorts-recyclables
- Automated waste-sorting and recycling classification using artificial neural network and features fusion: a digital-enabled circular economy vision for smart cities: https://link.springer.com/article/10.1007/s11042-021-11537-0
- Garbage detection and classification using a new deep learning-based machine vision system as a tool for sustainable waste recycling: https://www.sciencedirect.com/science/article/abs/pii/S0956053X23001915
- Recent Developments in Technology for Sorting Plastic for Recycling: The Emergence of Artificial Intelligence and the Rise of the Robots: https://www.mdpi.com/2313-4321/9/4/59
- Revolutionizing urban solid waste management with AI and IoT: A review of smart solutions for waste collection, sorting, and recycling: https://www.sciencedirect.com/science/article/pii/S2590123025001069
- Enhancing waste recognition with vision-language models: A prompt engineering approach for a scalable solution: https://www.sciencedirect.com/science/article/pii/S0956053X25003502
