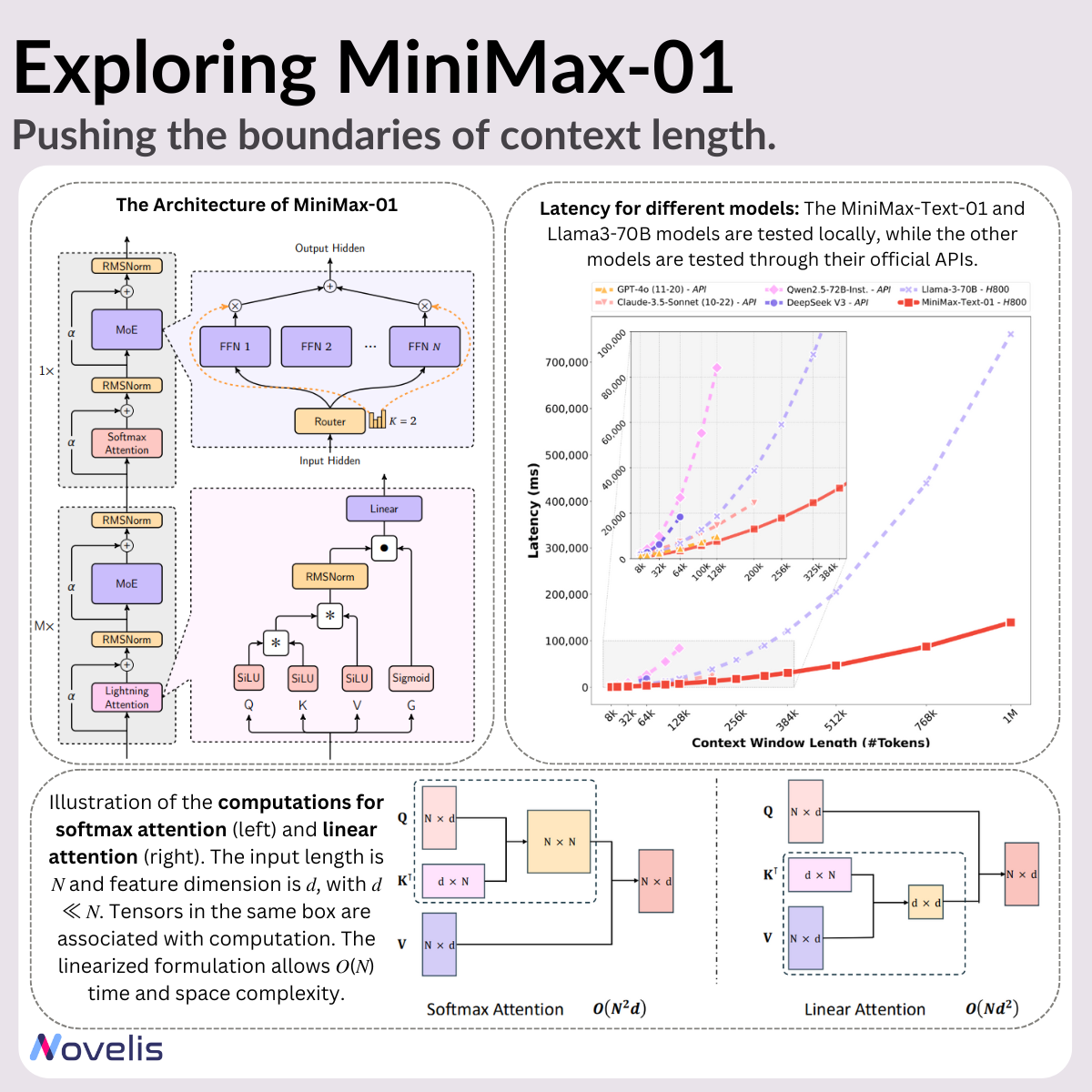
Pour les modèles de langage (LLMs), la capacité à gérer de longs contextes est essentielle. MiniMax-01, une nouvelle série de modèles développée par MiniMax, apporte des améliorations significatives en termes de scalabilité et d’efficacité computationnelle, atteignant des fenêtres de contexte allant jusqu’à 4 millions de tokens, soit 20 fois plus que la plupart des LLMs actuels.
Principales innovations de MiniMax-01 :
Des longueurs de contexte record :
MiniMax-01 dépasse les performances de modèles comme GPT-4 et Claude-3.5-Sonnet, permettant des longueurs de contexte allant jusqu’à 4 millions de tokens. Cela autorise le traitement de documents entiers, rapports ou livres multi-chapitres en une seule inférence, sans besoin de fragmenter les contenus.
Lightning Attention et Mixture of Experts :
- Lightning Attention : un mécanisme d’attention à complexité linéaire conçu pour un traitement séquentiel efficace.
- Mixture of Experts : une architecture comprenant 456 milliards de paramètres répartis sur 32 experts. Seulement 45,9 milliards de paramètres sont activés par token, réduisant ainsi la charge computationnelle tout en maintenant des performances élevées.
Entraînement et inférence efficaces :
MiniMax-01 optimise l’utilisation des GPU et réduit les surcoûts de communication grâce à :
- Techniques Expert Parallel et Tensor Parallel pour maximiser l’efficacité de l’entraînement.
- Padding multi-niveaux et parallélisme de séquence pour atteindre une utilisation GPU à 75 %.
MiniMax-VL-01 : un modèle Vision-Langage
En complément de MiniMax-Text-01, MiniMax a appliqué les mêmes innovations aux tâches multimodales avec MiniMax-VL-01. Entraîné sur 512 milliards de tokens vision-langage, ce modèle traite efficacement données textuelles et visuelles, le rendant adapté à des tâches comme la génération de descriptions d’images, le raisonnement basé sur les images et la compréhension multimodale.
Applications pratiques :
La capacité à gérer 4 millions de tokens ouvre des possibilités dans de nombreux secteurs :
- Analyse juridique et financière : traitement de dossiers juridiques ou de rapports financiers complets en une seule passe.
- Recherche scientifique : analyse de grands ensembles de données ou résumés d’années d’études.
- Écriture créative : génération de récits longs avec des arcs narratifs complexes.
- Applications multimodales : amélioration des tâches intégrant texte et images.
MiniMax a rendu MiniMax-01 accessible publiquement via Hugging Face.
🔗 Explore MiniMax-01 on Hugging Face