Dans le domaine en pleine évolution de l’IA multimodale, les grands modèles de langage vidéo (VLLMs) émergent comme un outil puissant pour comprendre et raisonner sur du contenu visuel dynamique.

Ces systèmes, construits sur la combinaison d’encodeurs visuels et de grands modèles de langage, sont capables de réaliser des tâches complexes telles que la réponse à des questions sur des vidéos, la compréhension de vidéos longues et le raisonnement multimodal.
Un obstacle majeur persiste : la surcharge en tokens. Même les vidéos courtes peuvent générer des dizaines de milliers de tokens visuels. Chaque image apporte son lot de tokens et, lorsqu’ils sont encodés de façon séquentielle, le modèle doit traiter un volume massif de données, entraînant des coûts mémoire élevés, une inférence lente et une faible scalabilité. La redondance entre les images et à l’intérieur d’une même image aggrave encore le problème, car de nombreux tokens représentent des contenus identiques ou qui se chevauchent.
C’est ce problème que LLaVA-Scissor a été conçu pour résoudre.
Repenser la compression des tokens : au-delà des cartes d’attention
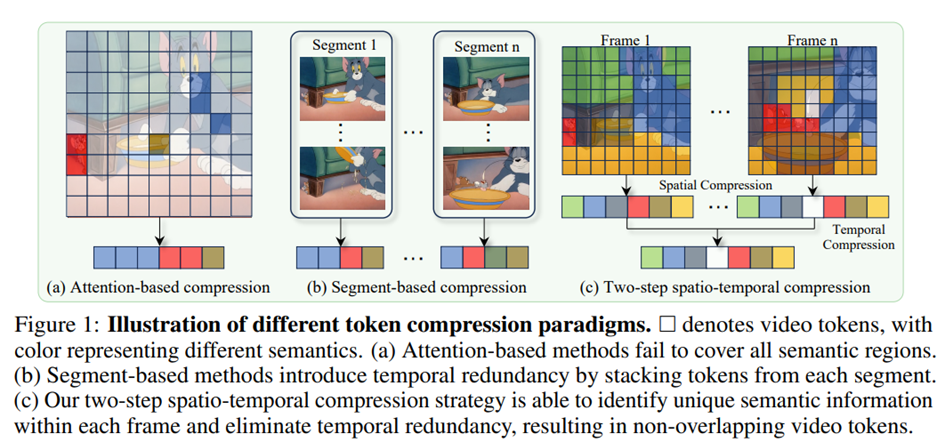
Les approches traditionnelles de compression des tokens dans les modèles vision-langage s’appuient souvent sur les scores d’attention pour sélectionner les tokens à conserver. Bien que logique, cette stratégie tend à privilégier les objets les plus visibles tout en négligeant des indices contextuels importants. Pire, elle sélectionne fréquemment les mêmes caractéristiques dominantes sur plusieurs images, entraînant une répétition plutôt qu’une véritable réduction.
D’autres méthodes cherchent à réduire les tokens grâce à des astuces architecturales (modules de pooling entraînables, segmentation de scènes, interpolation inter-images…), mais elles nécessitent généralement un nouvel entraînement, se généralisent mal et ont du mal à gérer le contenu temporellement incohérent.
LLaVA-Scissor adopte une autre approche. Il introduit un algorithme de compression, sans entraînement, appliqué au moment de l’inférence, qui identifie des groupes de tokens sémantiquement uniques et réduit efficacement la redondance, sans perte de compréhension.
Composants connectés sémantiques : une approche basée sur les graphes
Au cœur de LLaVA-Scissor se trouve une idée simple mais élégante : traiter les tokens comme un graphe et les réduire en identifiant des composants connectés sur la base de leur similarité sémantique.
Voici comment cela fonctionne.
Chaque token est représenté comme un vecteur de grande dimension (issu de l’encodeur visuel). LLaVA-Scissor calcule les similarités par paires entre tous les tokens d’une image (ou entre plusieurs images) et construit une matrice d’adjacence binaire basée sur un seuil de similarité. Les tokens suffisamment similaires sont considérés comme connectés.
Ce processus transforme le problème de compression des tokens en un problème de clustering de graphe. En utilisant un algorithme union-find efficace, le modèle extrait les composants connectés, c’est-à-dire des groupes de tokens sémantiquement similaires. Chaque groupe est ensuite compressé en un seul token représentatif, calculé comme la moyenne de tous les tokens du composant.
Fait crucial, aucune hypothèse n’est faite sur l’adjacence spatiale ou temporelle. Cela permet au système d’identifier la similarité sémantique entre des tokens même s’ils proviennent de différentes images ou de positions spatiales différentes. Le résultat est un ensemble de tokens représentatifs qui préserve la diversité du contenu sémantique sans dupliquer l’information.
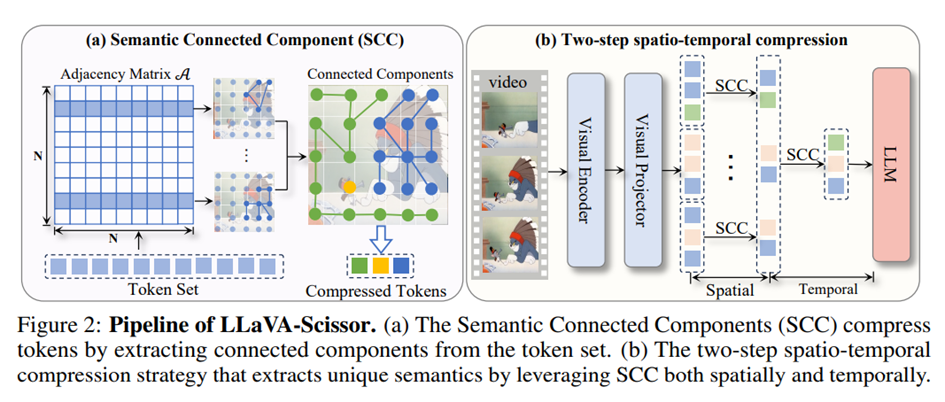
Une stratégie en deux étapes : compression spatiale et temporelle
Comprendre une vidéo nécessite de réduire la redondance à la fois à l’intérieur d’une image et entre les images.
LLaVA-Scissor utilise donc un pipeline de compression en deux étapes :
- Compression spatiale : dans chaque image, les composantes connectées sont identifiées et fusionnées, donnant un ensemble réduit de tokens représentatifs.
- Compression temporelle : ces tokens représentatifs sont ensuite concaténés sur l’ensemble des images, puis compressés à nouveau pour supprimer les redondances temporelles.
Ce processus hiérarchique permet d’éliminer les concepts visuels redondants dans l’espace et le temps, aboutissant à un jeu final de tokens compact, expressif et sans redondance.
Une étape optionnelle de fusion peut réaligner l’ensemble original de tokens avec l’ensemble compressé pour améliorer la fidélité : chaque token original est associé à son représentant le plus proche, puis moyenné. Cette étape renforce les performances, notamment lorsque le budget de tokens est faible.
Résultats expérimentaux : moins de tokens, plus de performance
LLaVA-Scissor a été évalué sur plusieurs grands benchmarks :
- Vidéo QA : ActivityNet-QA, Video-ChatGPT, Next-QA
- Compréhension de vidéos longues : EgoSchema, MLVU, VideoMME, VideoMMMU
- Raisonnement multi-choix : MVBench
Pour garantir une base solide, LLaVA-Scissor s’appuie sur une version améliorée de l’architecture LLaVA-OneVision. La version originale de LLaVA-OneVision combinait CLIP comme encodeur visuel avec Qwen 2 comme modèle de langage.
Pour LLaVA-Scissor, les auteurs ont amélioré cette base en remplaçant CLIP par SIGLIP et en utilisant Qwen 2.5 comme LLM, puis ont réentraîné une version enrichie du modèle LLaVA-OneVision en utilisant les données open source Oryx. Ils ont également testé une variante plus petite, LLaVA-OneVision-0.5B, qui utilisait également SIGLIP et Qwen-2.5-0.5B, afin de vérifier la robustesse même à des échelles réduites.
Les résultats sont très intéressants. Sur les tâches de vidéo QA, LLaVA-Scissor a égalé ou dépassé les autres méthodes avec 50% de tokens conservés. Mais sa véritable force est apparue lorsque le taux de rétention a diminué. À 10% de tokens conservés, il a obtenu un score moyen de 80,03%, dépassant FastV (78,76 %), PLLaVA (77,87 %) et VisionZip (65,09 %). Même à seulement 5%, les performances sont restées solides.
Sur les benchmarks de vidéos longues, où la compression temporelle est cruciale, LLaVA-Scissor est resté en tête. Avec un taux de rétention de 5%, il a surpassé toutes les autres méthodes, atteignant 92,6 % de précision moyenne contre 91,5% pour FastV et 90,4% pour PLLaVA à 10%.
Sur MVBench, qui inclut 20 tâches multimodales variées, LLaVA-Scissor a obtenu les meilleurs scores moyens à la fois à 35% et 10% de tokens conservés, prouvant ainsi sa polyvalence.
Efficace et évolutif : réduction des FLOPs et potentiel de déploiement
L’aspect le plus convaincant de LLaVA-Scissor est sans doute son efficacité.
Contrairement aux méthodes qui compressent les tokens pendant l’étape LLM (comme FastV), LLaVA-Scissor effectue la compression avant que les tokens n’atteignent le modèle de langage. Cela réduit drastiquement les FLOPs.

À 10% de tokens conservés, LLaVA-Scissor a réduit les FLOPs de l’étape LLM à seulement 9,66% du modèle complet, tout en maintenant plus de 96% de performance. À 5%, il a encore obtenu de bons résultats avec seulement 5,56% des FLOPs.
Cela fait de LLaVA-Scissor un candidat idéal pour :
- les applications vidéo en temps réel
- l’inférence embarquée
- les scénarios d’IA mobile ou en périphérie
Son caractère sans entraînement le rend également plug-and-play : il peut être intégré à n’importe quel pipeline vision-langage basé sur des transformeurs sans nécessiter de réentraînement ni d’adaptation spécifique.
Ce qui le rend efficace : enseignements des études d’ablation
Les études d’ablation confirment que chaque composant contribue au succès de LLaVA-Scissor :
- Sans compression temporelle, les performances chutent de plus d’un point sur MVBench.
- Sans fusion, la couverture des tokens devient trop faible.
- Les stratégies d’échantillonnage comme L2Norm ou la sélection uniforme donnent de moins bons résultats que SCC, qui préserve plus fidèlement la couverture sémantique.
De plus, la méthode reste robuste même sur des modèles de base plus petits, comme LLaVA-OneVision-0.5B, où la redondance est plus difficile à compenser. Cette robustesse souligne sa généralité et son applicabilité sur différents régimes de calcul.
Réflexions finales
LLaVA-Scissor n’est pas une rupture radicale dans la littérature sur la compression des tokens, mais il est remarquablement simple, élégant et étonnamment efficace.
Plutôt que d’ajuster les poids d’attention ou d’introduire de nouveaux régimes d’entraînement, il reformule la compression des tokens comme un problème de clustering sémantique. Avec un algorithme de graphe léger et sans besoin de réentraînement, il offre une solution pratique au problème d’explosion du nombre de tokens qui devient de plus en plus pressant dans les LLM vidéo.
Dans un contexte où les entrées multimodales augmentent plus vite que les budgets de calcul, nous pensons que des méthodes comme celle-ci (rapides, sans entraînement et efficaces) méritent une attention particulière.
Ressources complémentaires
Dépôt de code : GitHub – HumanMLLM/LLaVA-Scissor
- Explorez l’implémentation complète, y compris les scripts de prétraitement et les pipelines d’évaluation : https://github.com/HumanMLLM/LLaVA-Scissor
Modèle de référence : LLaVA-Scissor-baseline-7B sur Hugging Face
- Testez le modèle de référence directement via Hugging Face : https://huggingface.co/BBBBCHAN/LLaVA-Scissor-baseline-7B
Article de recherche : LLaVA-Scissor: Training-Free Token Compression for Video LLMs (arXiv)
- Approfondissez les détails techniques, la méthodologie et les résultats expérimentaux : https://arxiv.org/abs/2506.21862
Article de recherche : Video Understanding with Large Language Models: A Survey
- Un guide complet sur les LLM vidéo : https://arxiv.org/abs/2312.17432
