6 Oct , 2025 read
Dans le monde en constante évolution de l’intelligence artificielle, la recherche de modèles capables de comprendre, générer et manipuler de manière fluide des informations visuelles et textuelles a franchi une étape importante avec Ovis-U1.
Ce modèle marque un véritable bond en avant dans l’IA multimodale unifiée, en trouvant l’équilibre entre compacité et performance. Avec seulement 3,6 milliards de paramètres (2,4 milliards dédiés à la compréhension et 1,2 milliard à la génération), Ovis-U1 égale ou dépasse les capacités de modèles beaucoup plus grands et spécialisés.

Sa conception illustre la puissance d’un entraînement unifié soigneusement pensé, comblant le fossé entre efficacité et haut niveau de performance, là où les approches modulaires précédentes paraissent désormais dépassées.
Une approche véritablement unifiée
Au cœur d’Ovis-U1 se trouve un moteur de 3 milliards de paramètres, intégrant trois capacités essentielles : la compréhension multimodale, la génération texte-vers-image et l’édition d’images. Contrairement aux modèles conçus pour une tâche unique, Ovis-U1 exploite pleinement l’interaction entre ces fonctions. Sa compréhension du contenu visuel enrichit la génération d’images, tandis que le processus génératif affine à son tour la compréhension des relations complexes entre texte et image. Inspiré par l’ambition de GPT-4o en matière d’intelligence unifiée, Ovis-U1 atteint une qualité de génération comparable tout en conservant une architecture plus compacte et économe en ressources. Cette synergie entre les tâches fait d’Ovis-U1 bien plus qu’un ensemble d’outils spécialisés : un véritable résolveur de problèmes multimodal cohérent.
Repousser les limites de la compréhension multimodale
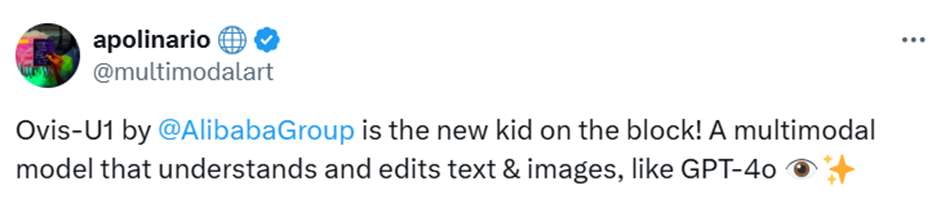
Lors de son évaluation sur le benchmark académique multimodal OpenCompass, Ovis-U1 a obtenu un score impressionnant de 69,6, se plaçant en tête des modèles de la gamme des 3 milliards de paramètres.

Même comparé à des modèles plus grands comme GPT-4o (75,4), Ovis-U1 affiche une compréhension remarquable pour sa taille. Des études d’ablation révèlent un point clé : intégrer les tâches de génération et d’édition dans l’entraînement améliore la performance de compréhension de 1,14 point, soulignant la forte synergie de l’apprentissage multi-tâches. Concrètement, le modèle ne se limite pas à « voir » ou décrire une image : il l’interprète, la contextualise et raisonne dessus avec une agilité autrefois réservée à des réseaux bien plus vastes.
Capturer l’imaginaire : génération texte-vers-image

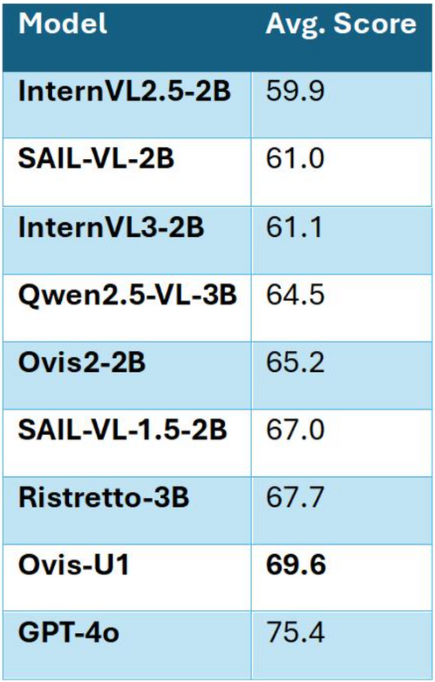
Les capacités d’Ovis-U1 s’étendent au domaine créatif de la génération d’images à partir de texte, avec un score de 83,72 sur DPG-Bench et 0,89 sur GenEval, dépassant même GPT-4o sur certaines tâches complexes. Que ce soit pour générer des scènes multi-objets, compter des éléments ou positionner précisément des objets, Ovis-U1 démontre une maîtrise fine des relations spatiales et contextuelles.
Cette fidélité est rendue possible par son décodage visuel de 1 milliard de paramètres, basé sur le Multimodal Diffusion Transformer (MMDiT) et le Rotary Positional Embedding (RoPE). Une stratégie d’entraînement progressive affine encore l’intégration des textes, garantissant que chaque image générée reflète fidèlement l’intention du prompt.
Redéfinir l’édition d’images
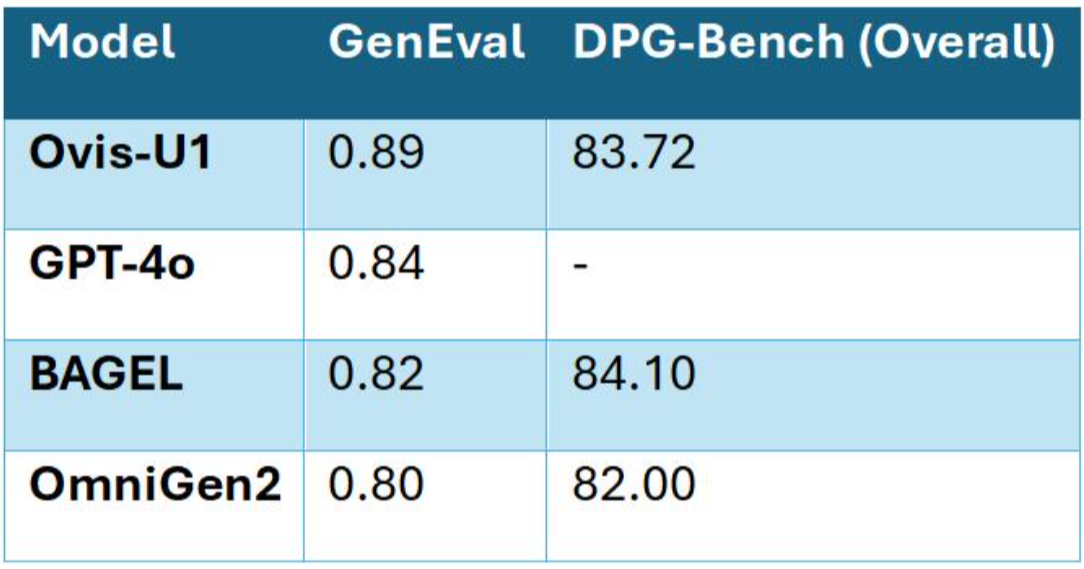
Ovis-U1 brille tout autant dans l’édition d’images, avec des résultats solides sur ImgEdit-Bench (4,00) et GEdit-Bench-EN (6,42).

Son raffineur de tokens bidirectionnel joue ici un rôle central, renforçant le dialogue entre représentations textuelles et visuelles. Remplacer des objets, supprimer des éléments ou ajuster finement un style se fait avec précision, là où il fallait auparavant recourir à plusieurs systèmes spécialisés. En pratique, Ovis-U1 ne se contente pas de générer : il collabore avec l’intention de l’utilisateur pour traduire naturellement les descriptions en modifications visuelles tangibles.
La force de la diversité dans l’entraînement
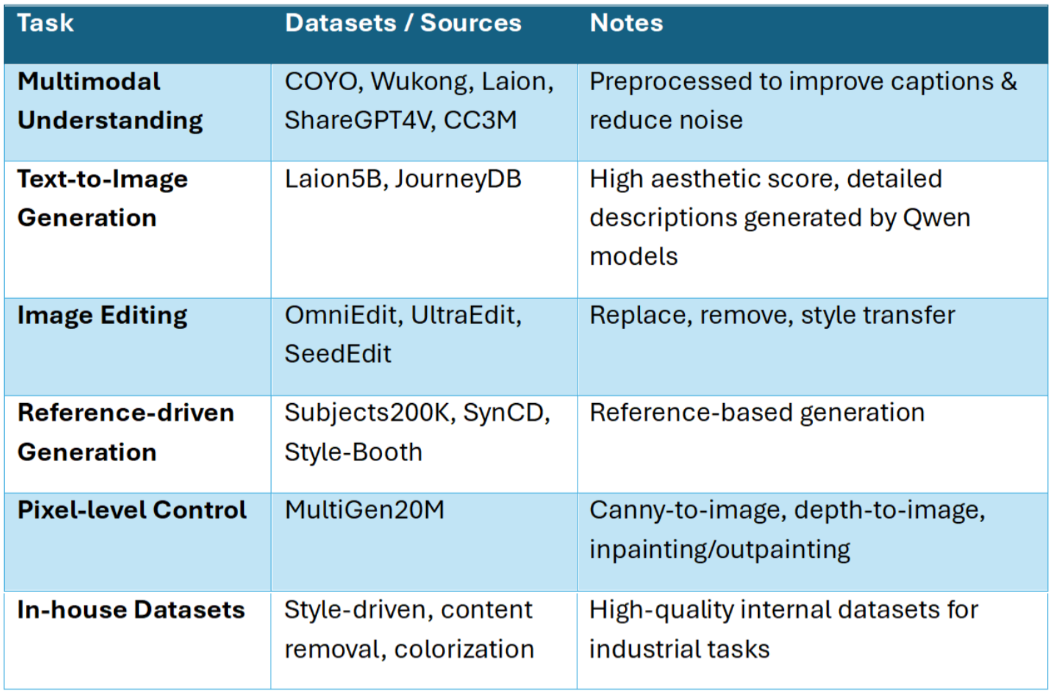
La performance d’Ovis-U1 repose sur la variété et la richesse de ses données d’entraînement. Des jeux publics comme COYO, Wukong, Laion, ShareGPT4V sont prétraités pour plus de clarté, tandis que de grands ensembles texte-image (Laion5B, JourneyDB) apportent une guidance esthétique de qualité. Le modèle exploite aussi des jeux spécialisés pour l’édition, la génération guidée par référence, le contrôle pixel, ainsi que des données internes pour le transfert de style, la suppression de contenu ou l’amélioration d’image.
En six étapes d’entraînement unifié, ces sources convergent, apprenant au modèle à comprendre, générer et éditer de manière cohérente.
Innovations architecturales
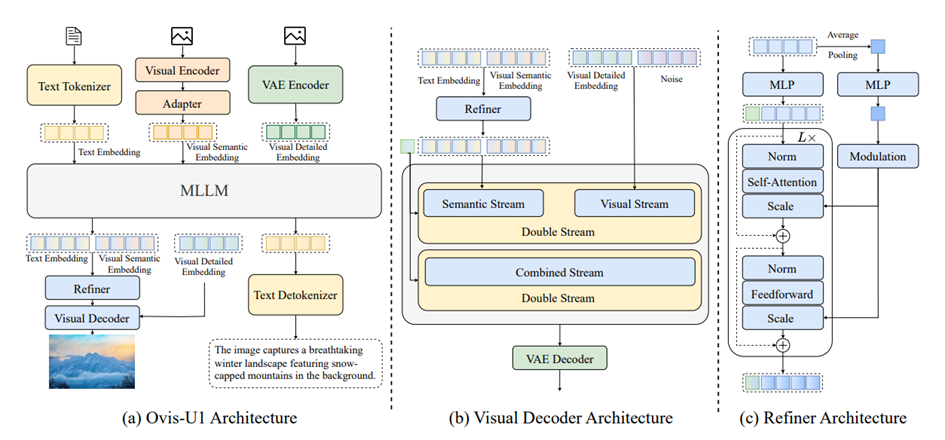
L’architecture d’Ovis-U1 illustre un équilibre précis entre compacité et capacités. Son décodage visuel, son raffineur bidirectionnel et son LLM Qwen3-1.7B travaillent de concert avec un encodeur visuel adapté aux résolutions arbitraires. Cette conception favorise l’intégration efficace des connaissances multimodales, garantissant que compréhension visuelle et génération se renforcent mutuellement. En traitant texte et image comme des processus liés et non séparés, Ovis-U1 atteint une cohésion rarement observée dans des modèles de cette taille.
Une symphonie d’entraînement en six étapes
La performance du modèle ne doit rien au hasard.
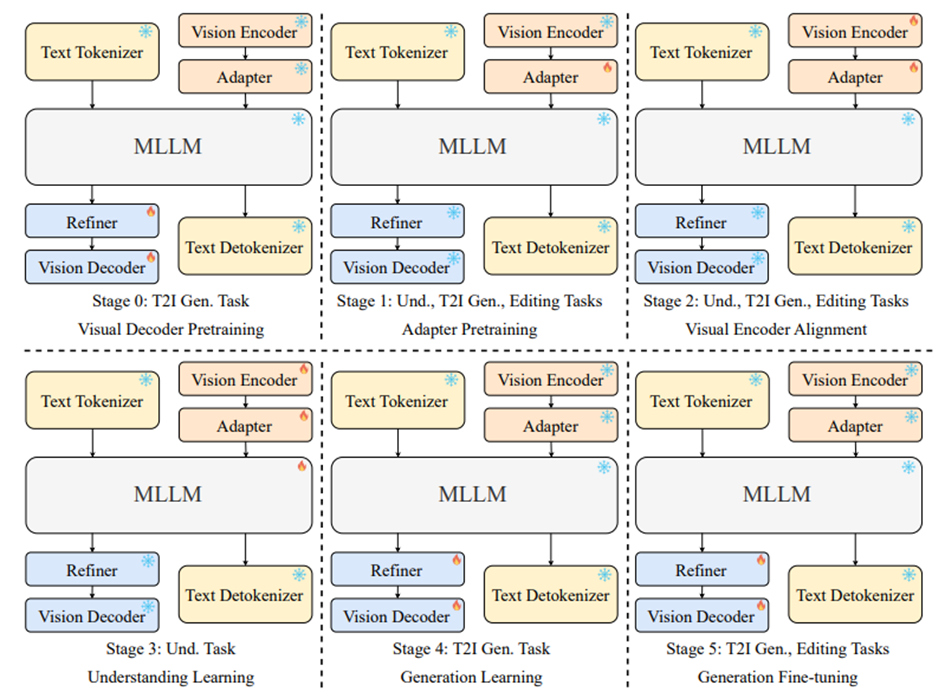
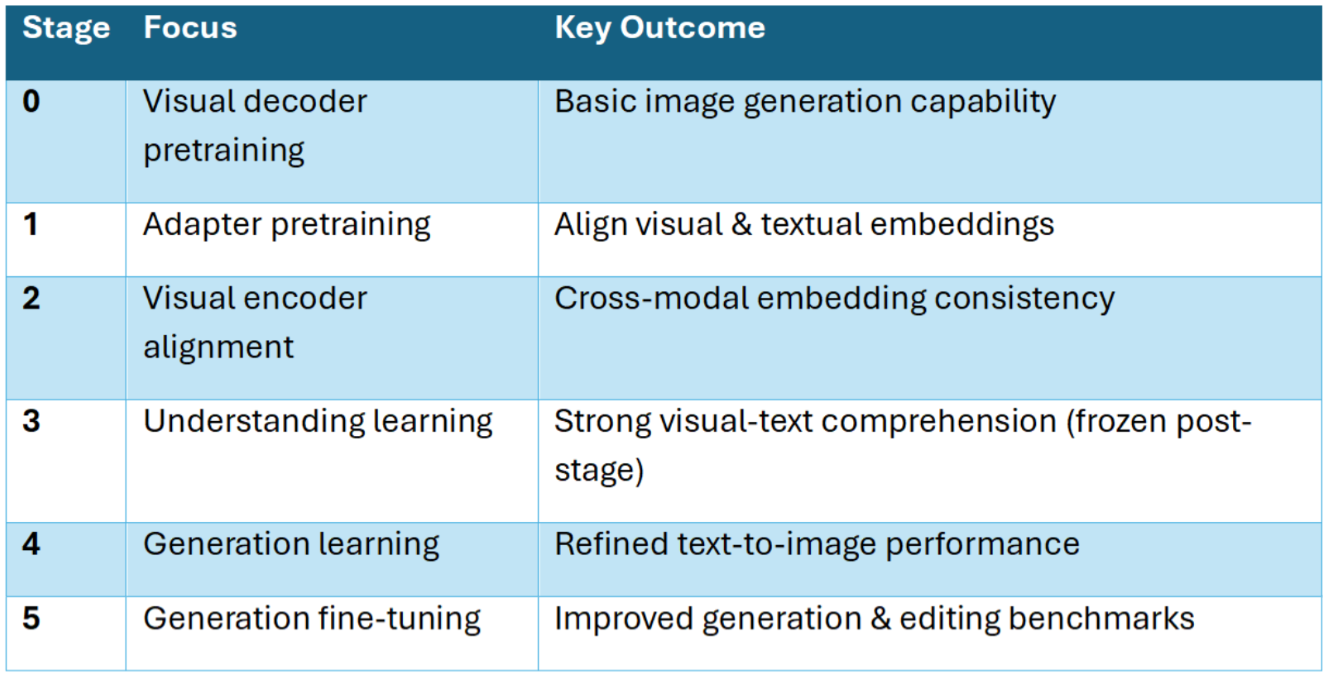
Son pipeline d’entraînement en six étapes aligne méthodiquement compréhension, génération et édition : du pré-entraînement initial du décodeur visuel à l’alignement par adaptateurs, en passant par le raffinement des embeddings multimodaux et l’apprentissage progressif en compréhension comme en génération. La dernière étape, un affinage avec des données d’édition d’images, renforce à la fois les capacités de génération et d’édition. Cette progression structurée est la clé pour atteindre une performance fluide entre les tâches, permettant à Ovis-U1 de fonctionner comme un cerveau unifié plutôt qu’un assemblage de systèmes spécialisés.
Impact industriel concret
En pratique, les capacités unifiées d’Ovis-U1 se traduisent par des bénéfices tangibles. En regroupant plusieurs modèles spécialisés en un seul, il simplifie les workflows : itérations de design, synthèse multi-vues, transfert de style, édition d’images… le tout via de simples instructions en langage naturel.
Sa polyvalence couvre aussi la détection d’objets, la segmentation, l’estimation de profondeur et plus encore, ce qui en fait un atout pour l’industrie manufacturière, le design, le marketing, la robotique et l’informatique spatiale. Sa taille compacte garantit par ailleurs une efficacité computationnelle qui facilite le déploiement sans sacrifier les performances.
Perspectives
L’avenir d’Ovis-U1 s’annonce prometteur. L’agrandissement du modèle devrait offrir des sorties encore plus fidèles, tandis que la curation de jeux de données image-texte plus riches renforcera sa capacité de généralisation. Des optimisations architecturales et l’usage de l’apprentissage par renforcement pourraient améliorer sa compréhension de l’intention humaine, produisant des résultats à la fois plus justes, sûrs et alignés avec les attentes des utilisateurs.
Conclusion
Ovis-U1 démontre que des modèles multimodaux unifiés et compacts peuvent rivaliser, voire surpasser, des systèmes plus grands et spécialisés. Grâce à une architecture innovante, un raffinement bidirectionnel, des données variées et un entraînement méthodique, il atteint un niveau de performance de pointe en compréhension, génération et édition. Plus qu’une prouesse technique, Ovis-U1 représente une solution pratique, scalable et polyvalente, prête à transformer les workflows industriels comme les usages créatifs — une nouvelle étape dans l’évolution de l’IA.
