Dans cet article nous allons découvrir le modèle Yolov7, un algorithme de détection d’objet. Nous étudierons tout d’abord son utilisation et ses caractéristiques au travers d’une base de données publique. Puis nous verrons comment entraîner ce modèle nous-même à partir de ce dataset. Enfin, nous entraînerons Yolov7 à identifier des objets personnalisés à partir de nos propres.
Qu’est-ce que Yolo ? Pourquoi Yolov7 ?
Yolo est un algorithme de détection d’objets dans une image. L’objectif de la détection d’objet est de classifier de manière automatique, à l’aide d’un réseau de neurones, la présence et la position d’objets humainement identifiables sur une image. L’intérêt repose donc sur les capacités et performances en termes de détection, reconnaissance et localisation des algorithmes, dont les applications pratiques sont multiples dans le domaine de l’image. La force de Yolo repose sur sa capacité à exécuter ces tâches en temps réel, ce qui le rend particulièrement utilisé avec des flux vidéo de dizaines d’images par seconde.
YOLO est en réalité un acronyme pour « You Only Look Once ». En effet, contrairement à de nombreux algorithmes de détections, Yolo est un réseau de neurones qui évalue la position et la classe des objets identifiés à partir d’un seul réseau de bout en bout qui détecte les classes à l’aide d’une couche entièrement connectée. Yolo n’a donc besoin de « voir » qu’une fois une image pour détecter les objets présents, là où certains algorithmes détectent uniquement des régions d’intérêt, avant de réévaluer celles-ci afin d’identifier les classes présentes.
Intersection over Union : IoU
Intersection over Union (littéralement Intersection sur Union, ou IoU) est une métrique permettant de mesurer la précision de la localisation d’un objet. Comme son nom l’indique, elle est calculée à partir du ratio entre la zone d’intersection Objet détecté-Objet réel et de la zone d’union de ces mêmes objets (cf. équation 1). En notant Adétecté et Aréel les aires respectives de l’objet détecté par YOLO et de l’objet tel que réellement situé sur l’image, on peut alors écrire :
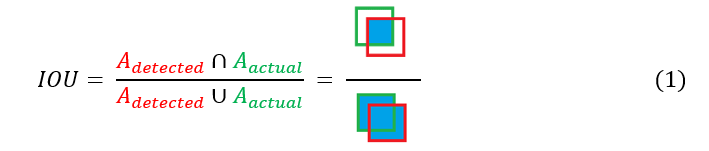
On notera qu’un IoU de 0 indique que les 2 aires sont complètement distinctes et qu’un IoU de 1 indique que les 2 objets sont parfaitement superposés. En général, un IoU > 0.5 représente un critère de localisation valide.
(mean) Average Precision : mAP
Average Precision (précision moyenne) est une métrique de précision de classification. Elle est basée sur la moyenne des prédictions correctes sur les prédictions totales. On cherche donc à se rapprocher d’un score de mAP de 100% (aucune erreur au moment de déterminer la classe d’un objet).
En revenant à notre point précédent, Yolo reste un modèle d’architecture, et non la propriété d’un développeur en particulier. Ceci explique pourquoi les versions de Yolo sont de contributeurs différents. En effet, on incrémente la version de Yolo (Yolov7 à ce jour : janvier 2023) à chaque fois que les métriques précédemment citées (surtout le mAP et son temps d’exécution associé) dépassent nettement le précédent modèle et donc l’état de l’art. Ainsi, chaque nouveau modèle YolovX est en réalité une amélioration montrée par un document de recherche associé publié en parallèle.
Comment fonctionne Yolo ?
Yolo fonctionne en segmentant l’image qu’il analyse. Il va tout d’abord quadriller l’espace, puis réaliser 2 opérations : localisation et classification.

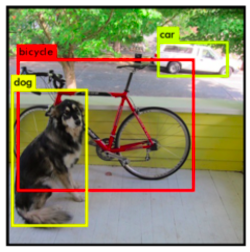
Dans un premier temps, Yolo identifie tous les objets présents à l’aide de cadres en leur associant un degré de confiance (ici représenté par l’épaisseur de la boite).

Puis, l’algorithme attribue une classe à chaque boîte selon l’objet qu’il pense avoir détecté à partir de la carte de probabilité.


Enfin, Yolo supprime toutes les boîtes superflues à l’aide de la méthode NMS.
NMS : Non-Maxima Suppression
La méthode NMS se base sur un parcours des boîtes à haut indice de confiance, puis une suppression des boîtes superposées à celles-là en mesurant l’IoU. Pour cela, on suit 4 étapes. En partant de la liste complète des boîtes détectées :
- Suppression de toutes les boîtes d’indice de confiance trop faible.
- Identification de la boîte d’indice de confiance le plus grand.
- Suppression de toutes les boîtes ayant un IoU trop grand (c’est-à-dire de toutes les boîtes trop similaires à notre boîte référence).
- En ignorant la boîte de référence ainsi utilisée, répétition des étapes 2) et 3) jusqu’à avoir éliminé toutes les boîtes de notre liste originale (c’est-à-dire en prenant la 2nde boîte d’indice de confiance le plus grand, puis la 3ème, etc.).
On obtient alors le résultat suivant :
Comment utiliser Yolov7 avec le dataset COCO ?
Maintenant que nous avons vu le modèle Yolo dans le détail, nous allons étudier son utilisation avec une base de données d’images : le dataset COCO.
Le dataset MICROSOFT COCO (pour Common Objects in COntext), plus communément appelé MS COCO, est un ensemble d’images représentant des objets communs dans un contexte commun. Cependant, à l’inverse des bases de données habituelles utilisées pour la détection et la reconnaissance d’objets, MS COCO ne présente pas des objets ou des scènes isolés. En effet, le but lors de la création de ce dataset était d’avoir des images proches de la vie réelle, afin d’avoir une base d’entraînement plus robuste pour des flux d’images classiques, reflétant la vie quotidienne.



Ainsi, en entrainant notre modèle Yolov7 avec le dataset MS COCO, il est possible d’obtenir un algorithme de reconnaissance de près d’une centaine de classes et catégorisant la majorité des objets, personnes et éléments du quotidien. Enfin, MS COCO est aujourd’hui la principale référence pour mesurer la précision et l’efficacité d’un modèle. Pour avoir un ordre d’idée, ci-dessous sont présentés les résultats des différentes versions de Yolo.
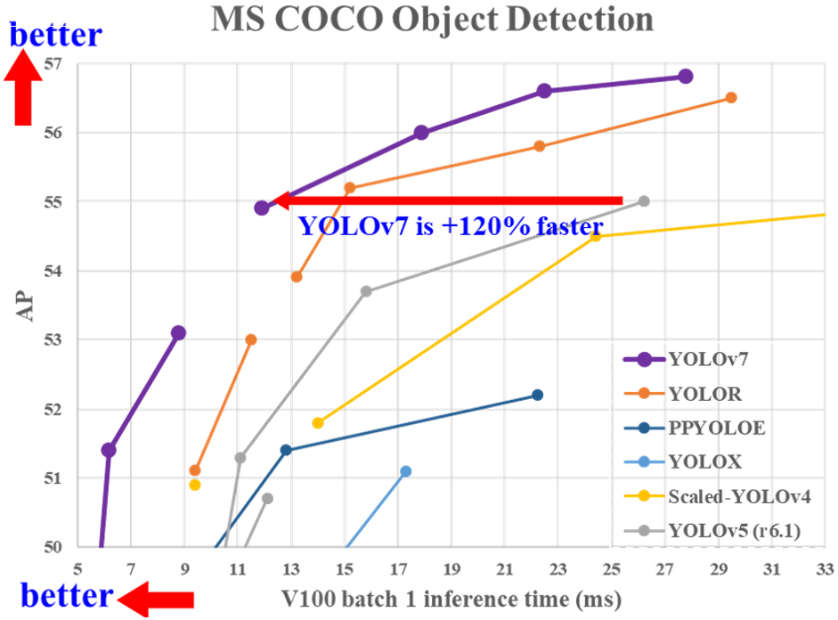
Sur ce graphique, chaque série de points représente la précision en fonctionnement d’un modèle sur le dataset MS COCO en fonction du temps attribué pour évaluer chaque image.
En abscisse, sont indiqués les temps accordés aux réseaux pour évaluer une image. Plus le temps est faible, plus on peut se permettre d’envoyer un flux d’images important à notre algorithme, au prix de la précision.
En ordonnée sont donc indiquées les précisions moyenne des modèles en fonction du temps accordé, comme vu précédemment.
On remarque alors 3 points importants :
- Quel que soit le temps accordé au réseau, Yolov7 surpasse les autres modèles Yolo en termes de précision de détection sur le dataset MS COCO. Ceci explique sa présence comme référence dans l’état de l’art actuel de la détection en temps réel d’objets sur image.
- L’augmentation du temps d’inférence sur chaque image n’a pas/peu d’intérêt une fois les 30ms/image dépassés. Cela implique que le modèle est plus optimal sur une utilisation nécessitant un traitement rapide des images, comme un flux vidéo (> 25 img/s).
- Quel que soit le modèle concerné, aucune ne dépasse les 57% de précision de détection. Ceci implique que le modèle est donc encore loin de pouvoir être utilisé de manière fiable dans un cadre public.
Pour obtenir soi-même les résultats précédents, il suffit de suivre les instructions de la page GitHub du modèle yolov7 pré-entraîné à partir du dataset MS COCO : https://github.com/WongKinYiu/yolov7.
Suivre tout d’abord la rubrique :
- Installation.
Puis l’encadré :
- Testing.
Comment entraîner Yolov7 ?
Maintenant que nous avons vu comment tester Yolov7 avec un dataset sur lequel il est entraîné, nous allons nous intéresser à la manière dont nous pouvons entraîner Yolov7 à l’aide de notre propre dataset. Nous allons commencer dans un premier temps un entraînement avec des données déjà préparées, ici le dataset MS COCO. Encore une fois, le GitHub de Yolov7 présente un encart spécifique prévu à cet effet :
- Training.
Il est décomposé en 2 étapes simples :
- Télécharger le dataset déjà annoté MS COCO.
- Lancer le script « train.py » intrinsèque au répertoire Git avec le dataset précédemment téléchargé.
Celui-ci va alors tourner sur 300 étapes pour se conformer au dataset MS COCO. On notera qu’en réalité cette opération a plus un but instructif étant donné que Yolov7 est déjà entraîné sur le dataset MS COCO et possède donc déjà un modèle adéquat.
Préparer ses propres données d’entraînement
Maintenant que nous avons vu ce qu’est Yolov7, comment le tester et l’entraîner, il ne nous reste plus qu’à lui fournir notre propre base d’images pour l’entraîner sur notre cas d’usage. Nous allons donc suivre 4 étapes pour créer notre propre dataset directement utilisable pour entraîner Yolov7 :
- Choix de notre base de données d’images.
- Optionnel : Labellisation de l’ensemble de nos images.
- Préparation du lancement (cas d’utilisation de Google Collab).
- Entraînement (et fonctionnement fractionné).
Pour illustrer le déroulé de ces opérations, nous allons prendre un cas similaire aux travaux de Novelis utilisés sur AIDA: la détection d’éléments dessinés sur une feuille de papier.

Pour commencer, il va donc nous falloir récupérer une quantité suffisante d’images similaires. Soit de notre propre collection, soit en utilisant une base de données préexistante (par exemple en prenant le dataset de notre choix à partir de ce lien. De notre côté, nous utiliserons le dataset Quick Draw. Une fois notre base formée, nous allons annoter nos images. Pour cela, de nombreux logiciels existent, la majorité du temps permettant de créer des boîtes, ou des polygones, et de les labelliser sous forme de classe. Dans notre cas, notre base de données est déjà labellisée, sinon il faudrait créer une classe pour chaque élément à détecter, puis identifier à la main sur chaque image les zones exactes de présences de ces classes. Une fois notre dataset labellisé, nous pouvons lancer une session sur Google Colab et commencer un nouveau Python Notebook. Nous l’appellerons ici « MyYolov7Project.ipynb » par exemple.
Étape préalable : copier votre dataset dans votre drive. Dans notre cas, on a déjà ajouté à notre drive un dossier « Yolov7_Dataset ». Voici l’arborescence du dossier :
Pour chaque dossier, on retrouve un dossier images, contenant les images, et un dossier labels contenant les labels associés générés précédemment. Dans notre cas, nous utilisons 20 000 images au total, dont 15 000 pour l’entrainement, 4 000 pour la validation et 1 000 pour le test.
Le fichier data.yaml contient quant à lui l’ensemble des chemins d’accès aux dossier :

Puis les caractéristiques des classes :

Nous ne représenterons pas les 345 classes dans le détail mais elles devront bien être présentes dans votre fichier. Nous pouvons donc à présent commencer notre script « MyYolov7Project.ipynb » sur Colab. Première étape, lier notre Drive au Colab afin de pouvoir sauvegarder nos résultats (Attention : les données du réseau entraîné sont volumineuses).

Une fois notre Drive lié, nous pouvons à présent cloner Yolov7 à partir du Git officiel :

En nous plaçant dans le dossier installé, nous vérifions les prérequis :

Nous aurons également besoin des bibliothèques sys et torch.

Nous pouvons alors lancer le script d’entrainement de notre réseau :

On notera que le batch size peut être modifié en fonction des capacités de votre GPU (avec la version gratuite de Collab, 16 reste le maximum possible). N’oubliez pas également de modifier votre chemin d’accès au fichier « data.yaml » en fonction de l’arborescence de votre Drive. À l’issue de l’entrainement, nous récupérons donc un dossier avec les métriques de l’entrainement ainsi qu’un modèle entraîné sur notre base de données. En lançant le script de détection (detect.py), nous pouvons donc obtenir le résultat de détection sur notre image de départ :
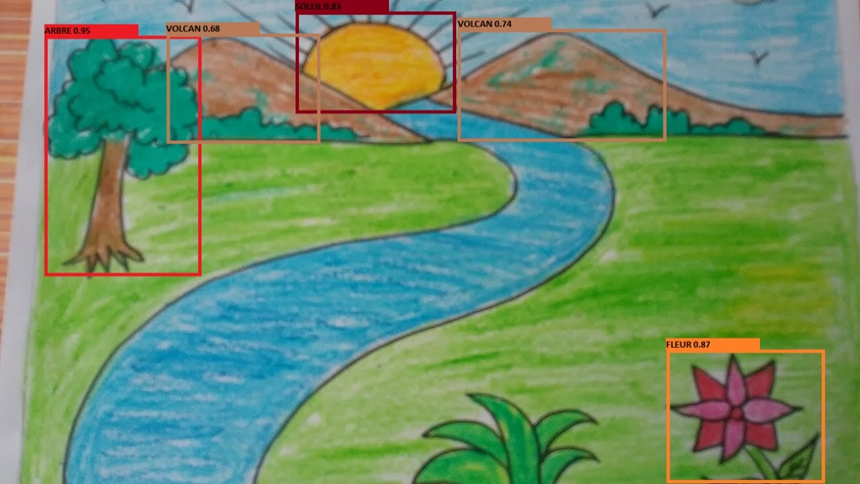
Comme on le voit, certains éléments n’ont pas été détectés (la rivière, l’herbe au premier plan) et certains ont été mal labellisés (les deux montagnes perçues comme des volcans, probablement dû aux rayons du soleil dépassant). Notre modèle est donc encore perfectible, soit en affinant notre base de données, soit en modifiant les paramètres d’entraînement.
Optionnel : Entrainement fractionné du réseau (En cas d’utilisation de de la version gratuite de Google Colab)
Bien que notre cas d’usage reste simpliste, en cas d’utilisation de la version gratuite de Google Colab, l’entrainement de notre réseau peut prendre plusieurs jours avant de s’achever. Or les restrictions de Google Colab (version gratuite) empêchent un programme de tourner plus de 12h. Pour conserver l’entrainement, il suffit alors de le relancer après l’arrêt d’une session avec en paramètre des poids (weights) notre dernier poids enregistré :

Ici un exemple lancé avec le 8ème run (remplacez le dossier « yolov78 » par le dernier entrainement réalisé). Vous pouvez retrouver l’ensemble de vos entrainements dans le dossier associé dans l’arborescence de Yolov7.
L’entrainement reprend alors du dernier epoch utilisé, et vous permet de progresser sans perdre le temps passé précédemment sur votre réseau.
Références :
- Travaux, expérimentations et retours d’expérience du Lab. R&D de Novelis.
- Contribution de WANG, Chien-Yao, BOCHKOVSKIY, Alexey, et LIAO, Hong-Yuan Mark. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv preprint arXiv:2207.02696, 2022. : https://arxiv.org/abs/2207.02696
- Official YOLOv7 code source : https://github.com/WongKinYiu/yolov7
- Microsoft COCO: Common Objects in Context : https://arxiv.org/pdf/1405.0312.pdf
- Créer son modèle avec YOLO https://datacorner.fr/yolo-custom-1/
