Computer Vision
05/10/2023
5 Oct , 2023 read
Découvrez 4 articles sur la vision par ordinateur réalisés par notre équipe de recherche.
YOLO : un algorithme de détection d’objets en temps réel pour plusieurs objets dans une image en un seul passage
YOLO : Simplifier la détection d’objets
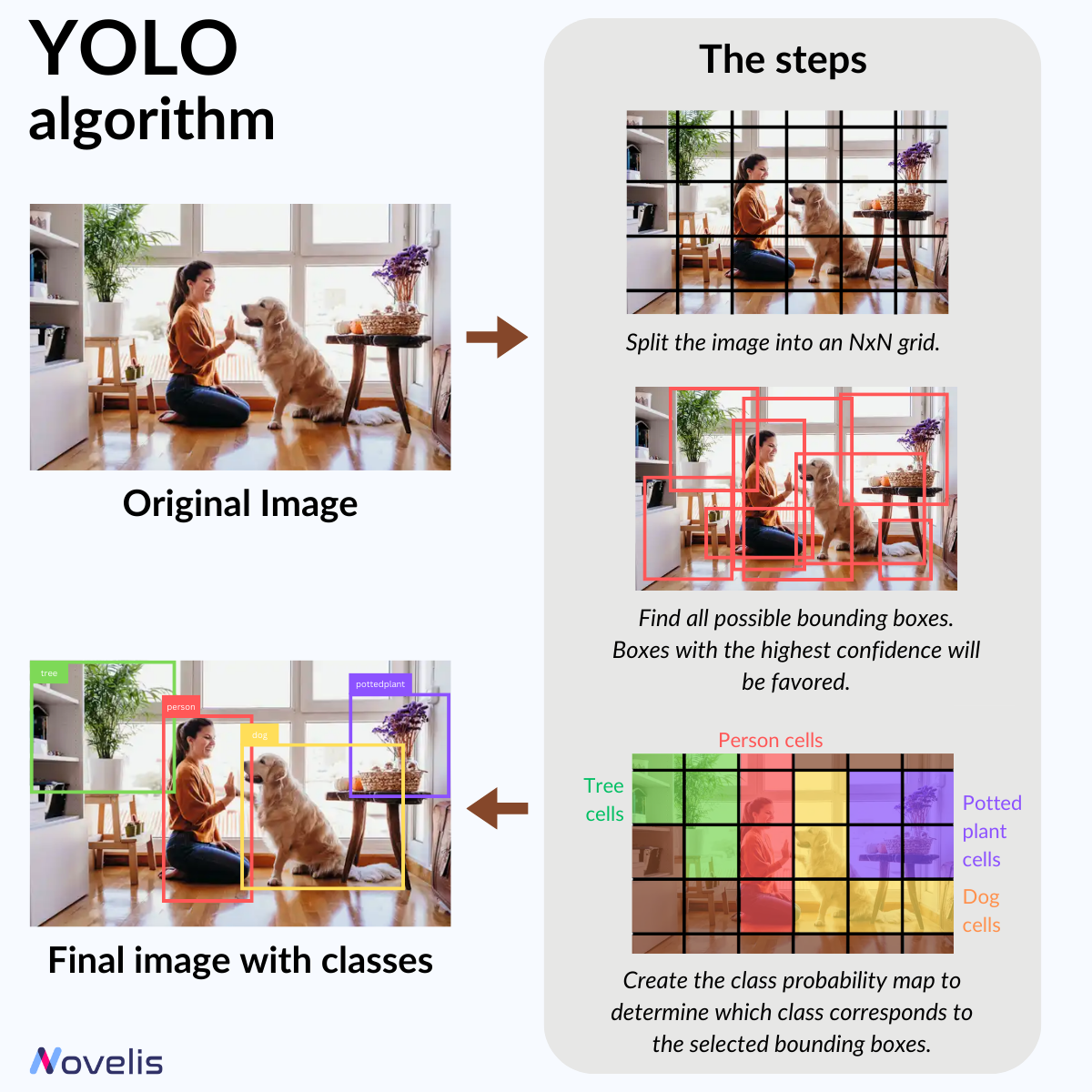
YOLO (You Only Look Once) est une technique de détection d’objets en temps réel de pointe dans la vision par ordinateur. Il utilise un réseau de neurones pour une détection rapide d’objets en divisant l’image en zones pour identifier des objets de différentes tailles. Il prédit la classe d’objet pour chaque boîte (chien, chat, plante, etc.) en apprenant une carte de probabilité de classe pour déterminer l’objet associé aux boîtes détectées.
YOLO fonctionne en capturant les caractéristiques essentielles de l’image, en les affinant et en identifiant les emplacements possibles des objets. Il apprend à reconnaître des objets dans les images d’entrée en s’entraînant sur des exemples étiquetés. Lors de la prédiction, il analyse l’image en une seule fois, détecte rapidement les objets et élimine les doublons.
La dernière version de YOLO est la v8, développée par Ultralytics, mais la v5 reste largement utilisée.
Pourquoi est-ce essentiel ? C’est comme apprendre à un ordinateur à repérer des objets instantanément ! YOLO se distingue par sa rapidité et sa précision, idéal pour des tâches comme la robotique ou les voitures autonomes.
OCR et IDP : une technologie qui convertit le texte imprimé en texte lisible par machine
La magie de la reconnaissance optique de caractères (OCR)
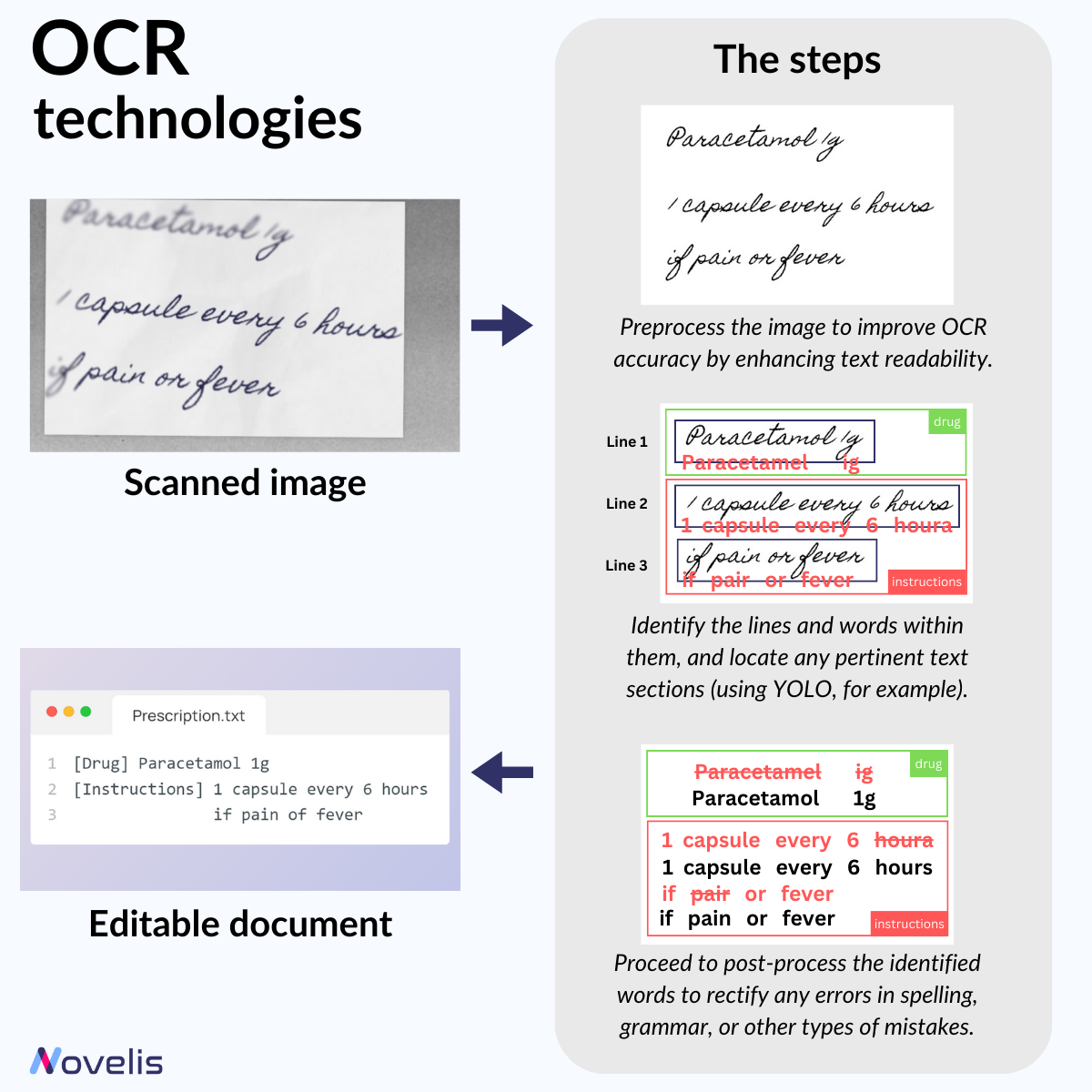
Vous vous demandez comment fonctionne le traitement intelligent de documents (IDP) ? Parmi ses fonctionnalités, il y a la conversion de texte scanné ou manuscrit en texte éditable et consultable, rendue possible grâce aux technologies de reconnaissance optique de caractères (OCR). Dans notre série sur les tâches de vision par ordinateur (voir notre article précédent sur YOLO), examinons de près l’OCR et son fonctionnement.
Lors de la conversion d’une image en texte, l’OCR passe par plusieurs étapes. La première est le prétraitement, où l’image est nettoyée pour rendre le texte plus lisible. Ensuite, on procède à la reconnaissance des caractères. Les anciennes méthodes OCR identifiaient chaque caractère ou mot en les comparant à des modèles connus. Les méthodes modernes utilisent des réseaux de neurones capables de reconnaître des lignes de texte complètes. La phase finale est le post-traitement pour corriger les erreurs. Des méthodes de détection d’objets comme YOLO peuvent aussi être utilisées pour identifier les champs et régions textuelles dans les documents.
Tesseract est le logiciel OCR de référence pour son haut degré de personnalisation et sa prise en charge de nombreuses langues. D’autres algorithmes, comme le DONUT « sans OCR », gagnent également en popularité.
Pourquoi est-ce essentiel ? Les technologies OCR permettent aux entreprises d’accélérer leurs flux de travail et aux individus d’accéder facilement à l’information. Elles favorisent l’innovation et transforment des secteurs comme la santé, la finance, l’éducation et le juridique.
DINOv2 : un modèle Vision Transformer qui produit des caractéristiques universelles adaptées aux tâches visuelles d’image
DINOv2 : La prochaine révolution en vision par ordinateur ?
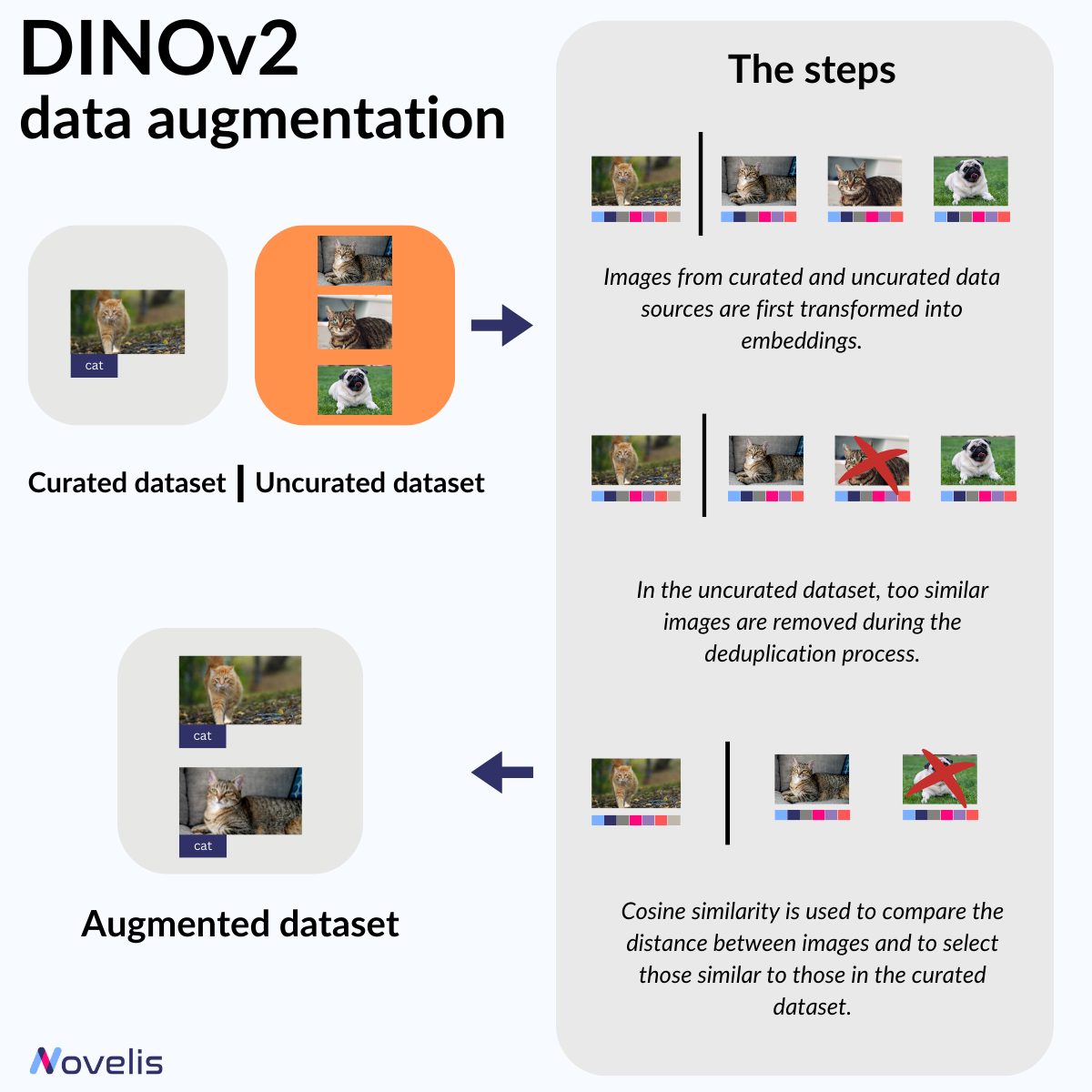
Le domaine de la vision par ordinateur évolue constamment. Dans nos précédents articles, nous avons abordé plusieurs méthodes de vision par ordinateur, qui nécessitent souvent de grandes quantités d’images étiquetées pour donner de bons résultats. DINOv2, un modèle de Meta Research (abréviation de “self-DIstillation with NO labels”), est un modèle innovant en vision par ordinateur utilisant l’apprentissage auto-supervisé, supprimant le besoin d’étiquetage manuel des images.
DINOv2 fonctionne sans avoir à étiqueter manuellement chaque image, une tâche souvent longue. Son architecture suit la méthode de masquage courante en NLP, mais c’est le processus de sélection de données qui rend DINOv2 unique. Il utilise des embeddings pour comparer les images d’un petit ensemble de données avec celles d’un ensemble plus large, puis il écarte les images similaires pour éviter les redondances et sélectionne des images proches pour enrichir l’ensemble de données initial.
La dernière version de DINOv2, lancée en avril 2023 par Meta Research, peut être utilisée dans diverses applications visuelles, notamment pour l’estimation de profondeur, la segmentation sémantique et la récupération d’instances.
Pourquoi est-ce essentiel ? Avec DINOv2, on évite l’étiquetage manuel, ce qui permet de gagner du temps. Ce modèle puissant simplifie la création de pipelines de vision par ordinateur précis et adaptables, particulièrement utile dans des secteurs spécialisés comme le médical ou l’industriel, où l’étiquetage de données est coûteux et complexe.
Efficient ViT : un modèle de vision rapide pour les tâches de prédiction dense haute résolution
Attention accélérée pour la segmentation sémantique haute résolution
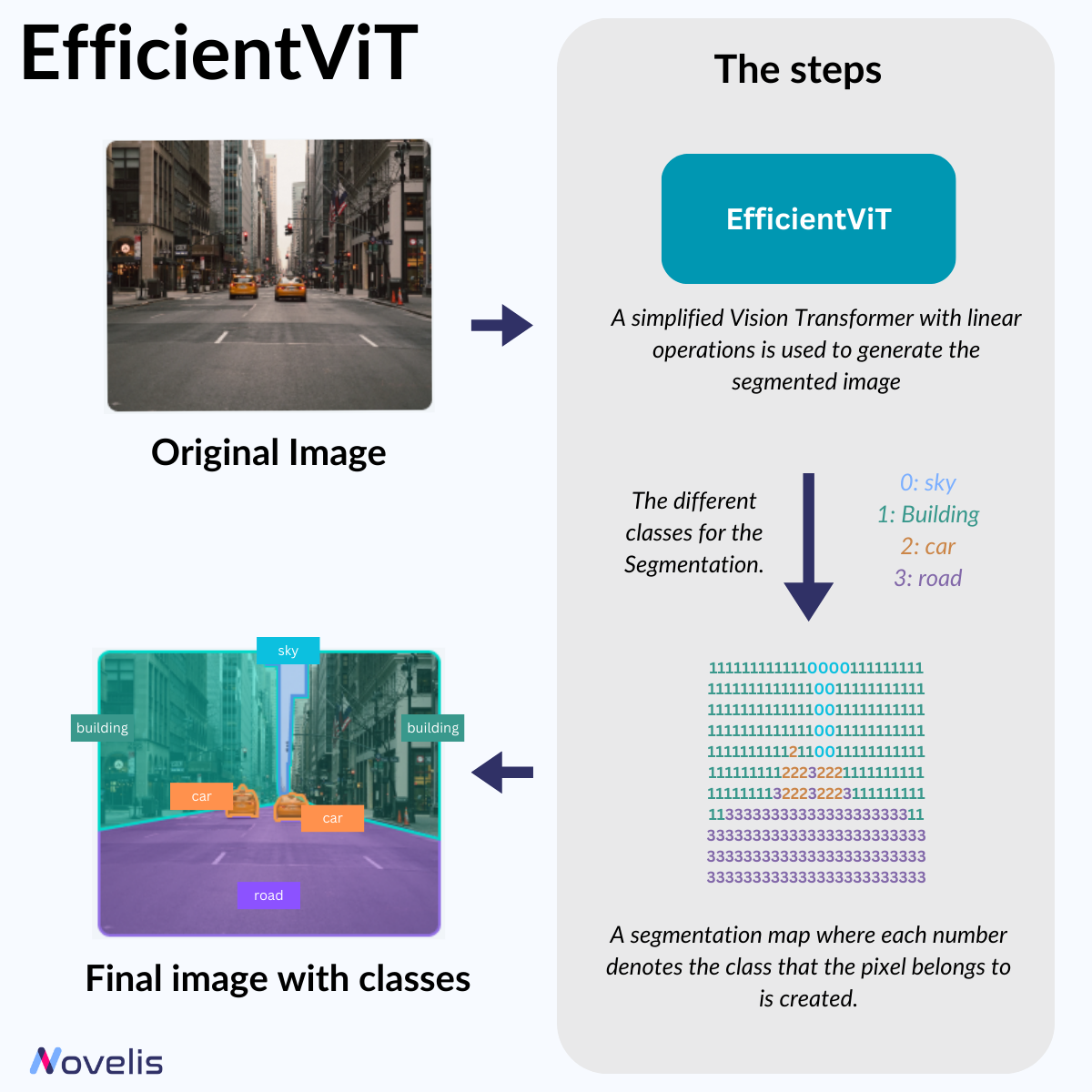
En vision par ordinateur en temps réel, comme pour les voitures autonomes, il est crucial de reconnaître rapidement et précisément les objets. Cela est possible grâce à la segmentation sémantique, qui analyse des images haute résolution de l’environnement. Cependant, cette méthode exige beaucoup de puissance de traitement. Pour l’utiliser sur des appareils avec des capacités limitées, des chercheurs du MIT ont développé un modèle qui réduit considérablement la complexité computationnelle.
EfficientViT est un nouveau transformer de vision qui simplifie la construction de la carte d’attention. Pour cela, les chercheurs ont modifié deux aspects : ils ont remplacé la fonction de similarité non linéaire par une linéaire, et réorganisé les opérations pour réduire les calculs nécessaires tout en maintenant la fonctionnalité. Deux éléments permettent cette simplification : l’un capture les interactions locales des caractéristiques et l’autre aide à détecter les petits et grands objets. Le transformer de vision simplifié génère une carte de segmentation où chaque pixel est associé à une classe.
Ce travail, principalement académique, a été rendu public par le MIT-IBM Watson AI Lab en 2022 sur GitHub, avec des mises à jour continues.
Pourquoi est-ce important ? Réduire la complexité computationnelle est essentiel pour la segmentation d’images en temps réel sur des appareils tels que les smartphones ou les systèmes embarqués avec une puissance de calcul limitée.
