StreamingLLM : Permettre aux LLM de répondre en temps réel
StreamingLLM : briser la limitation de contexte court
Avez-vous déjà eu une conversation prolongée avec un chatbot (comme ChatGPT), pour vous rendre compte qu’il a perdu le fil ou n’est plus aussi cohérent ? Ou vous êtes-vous retrouvé face à une limite de longueur d’entrée épuisée avec les API de certains fournisseurs de modèles de langage ? La principale contrainte des LLM est la longueur de contexte limitée, ce qui empêche des interactions prolongées et de tirer pleinement parti de leurs capacités.
Des chercheurs du MIT, de Meta AI et de l’université Carnegie Mellon ont publié un article intitulé « Efficient Streaming Language Models With Attention Sinks ». Cet article présente une nouvelle technique permettant d’augmenter la longueur d’entrée des LLM sans perte d’efficacité ni dégradation des performances, et ce, sans avoir à réentraîner les modèles.
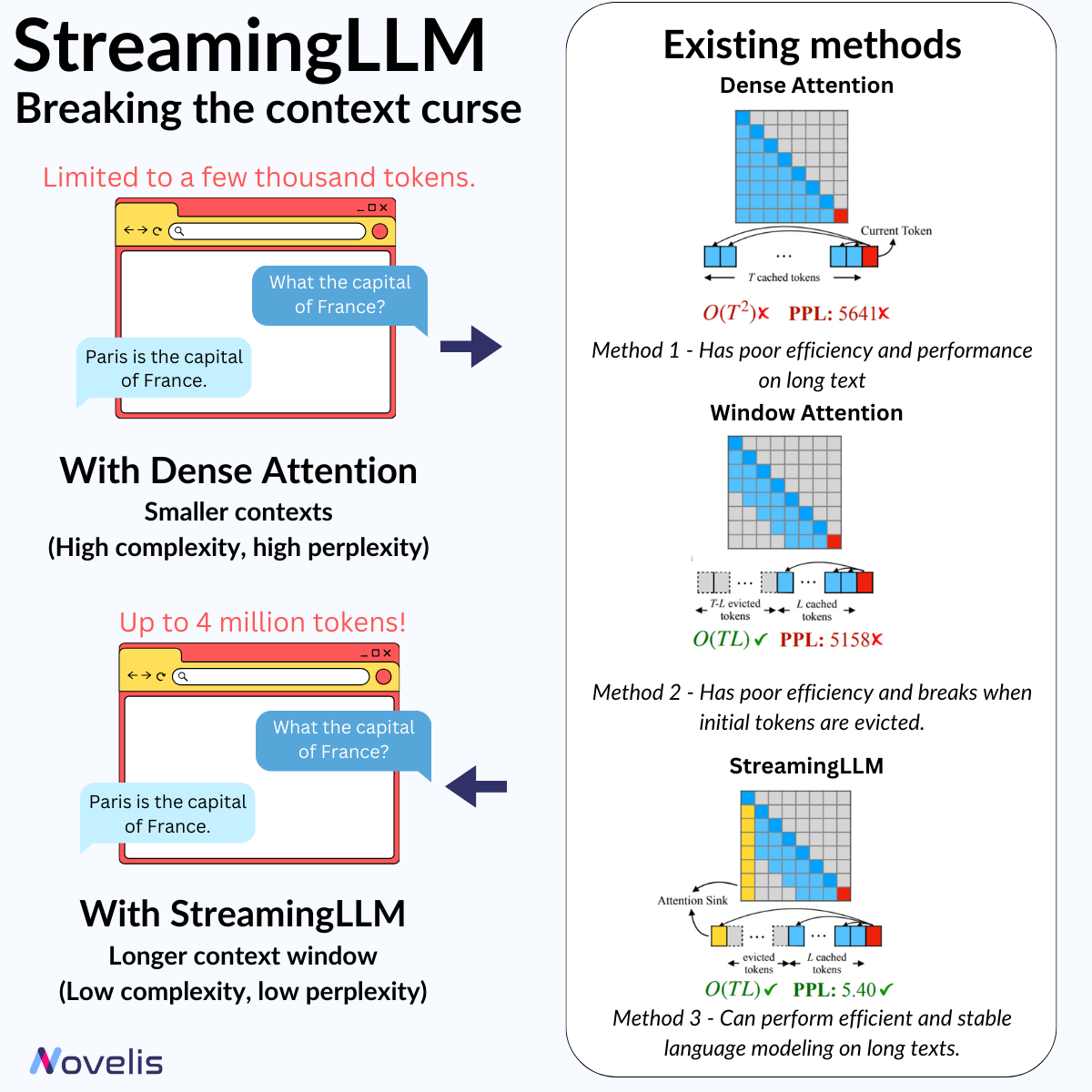
Le cadre StreamingLLM stocke les quatre premiers jetons (appelés « sinks ») dans un cache KV en tant que « Attention Sink » sur des modèles pré-entraînés comme LLaMA, Mistral, Falcon, etc. Ces jetons essentiels résolvent les défis de performance liés à l’attention classique, permettant d’étendre les capacités des LLM au-delà des limites de taille de contexte et de cache. L’utilisation de StreamingLLM aide à réduire la perplexité (indicateur de la capacité d’un modèle à prédire le prochain mot dans un contexte) ainsi que la complexité de calcul du modèle.
Pourquoi est-ce important ? Cette technique permet aux LLM de gérer des séquences de plus de 4 millions de jetons sans réentraînement, tout en minimisant la latence et l’empreinte mémoire par rapport aux méthodes précédentes.
RLHF : Adapter les modèles d’IA grâce à l’intervention humaine
Renforcer l’IA avec l’apprentissage par renforcement à partir du feedback humain
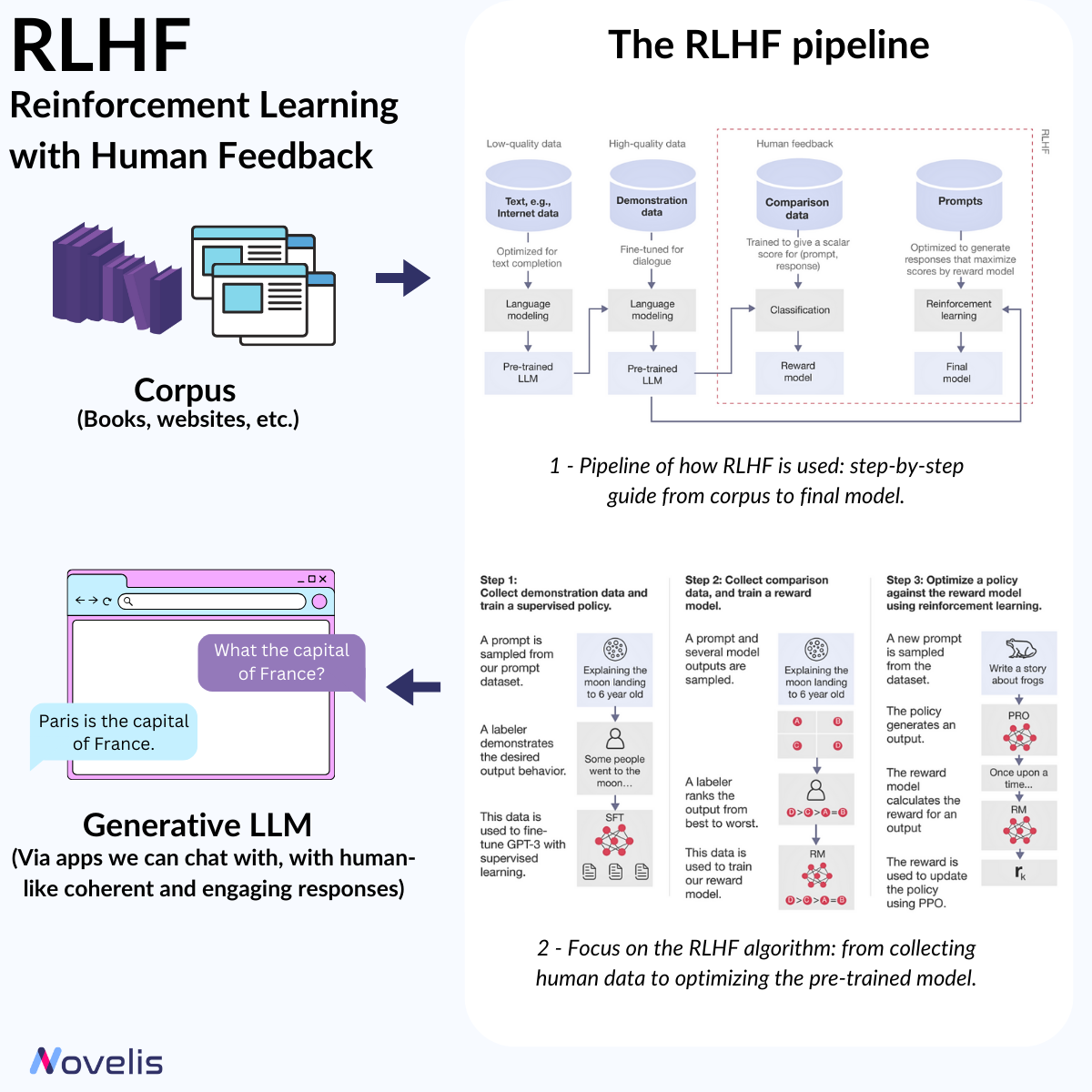
Le Renforcement par l’Apprentissage de Retours Humains (RLHF) est une avancée importante dans le traitement du langage naturel (NLP). Il permet d’ajuster les modèles de machine learning en utilisant l’intuition humaine, rendant les systèmes d’IA plus contextuels. Le RLHF est une méthode d’apprentissage où les modèles d’IA (ici, les LLM) sont affinés via des feedbacks humains. Cela implique de créer un « modèle de récompense » basé sur des retours, qui sert ensuite à optimiser le comportement de l’agent IA par le biais d’algorithmes de renforcement. En pratique, le RLHF permet aux machines d’apprendre et de s’améliorer grâce aux jugements des évaluateurs humains. Par exemple, un modèle d’IA peut être formé pour générer des résumés convaincants ou engager des conversations plus pertinentes en utilisant le RLHF.
Pourquoi est-ce essentiel ? Comprendre le RLHF est crucial pour saisir l’évolution du NLP et des LLM, et comment ils offrent des réponses claires et engageantes. RLHF permet d’aligner les modèles d’IA sur les valeurs humaines en fournissant des réponses plus proches de nos préférences.
RAG : Combiner les LLM avec des bases de données externes
L’efficacité simple du Retrieval Augmented Generation (RAG)
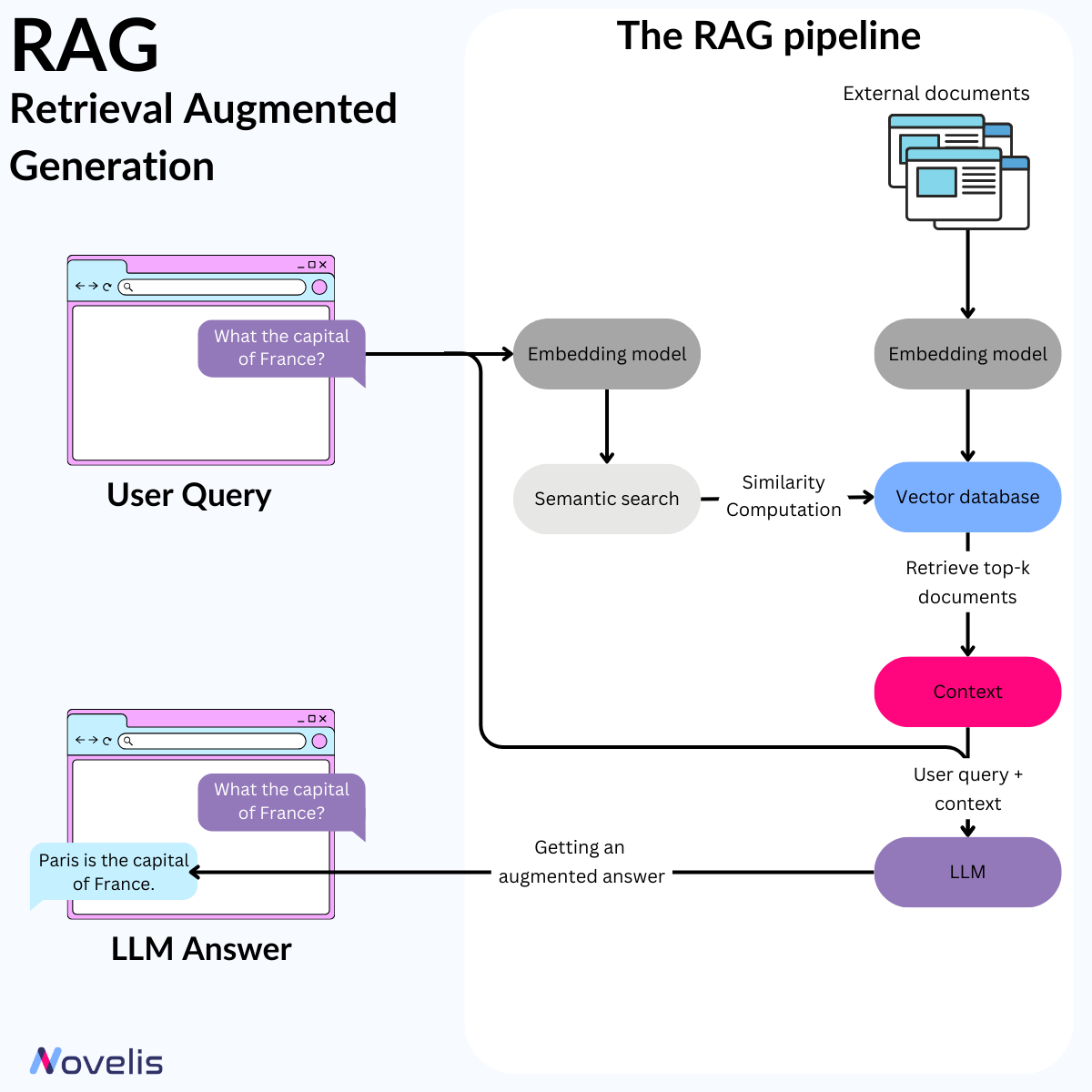
L’intelligence artificielle progresse rapidement avec des modèles comme GPT-4, Mistral, et Llama qui fixent de nouveaux standards. Cependant, ces modèles restent limités par leurs connaissances internes. En septembre 2020, Meta AI a introduit le cadre RAG (Retrieval Augmented Generation), conçu pour améliorer les réponses des LLM en intégrant des sources de connaissance externes et en enrichissant leurs bases de données internes. RAG est un système d’IA qui combine les LLM avec des bases de données externes pour fournir des réponses précises et actualisées.
Pourquoi est-ce essentiel ? Les LLM sont souvent limités par des données obsolètes et peuvent générer des informations erronées. Le RAG résout ces problèmes en assurant une précision factuelle et une cohérence, réduisant la nécessité de réentraîner fréquemment les modèles. Cela permet de diminuer les ressources computationnelles et financières nécessaires au maintien des LLM.
CoT : Concevoir les meilleurs prompts pour obtenir les meilleurs résultats
Chain-of-Thought : les LLM peuvent-ils raisonner ?
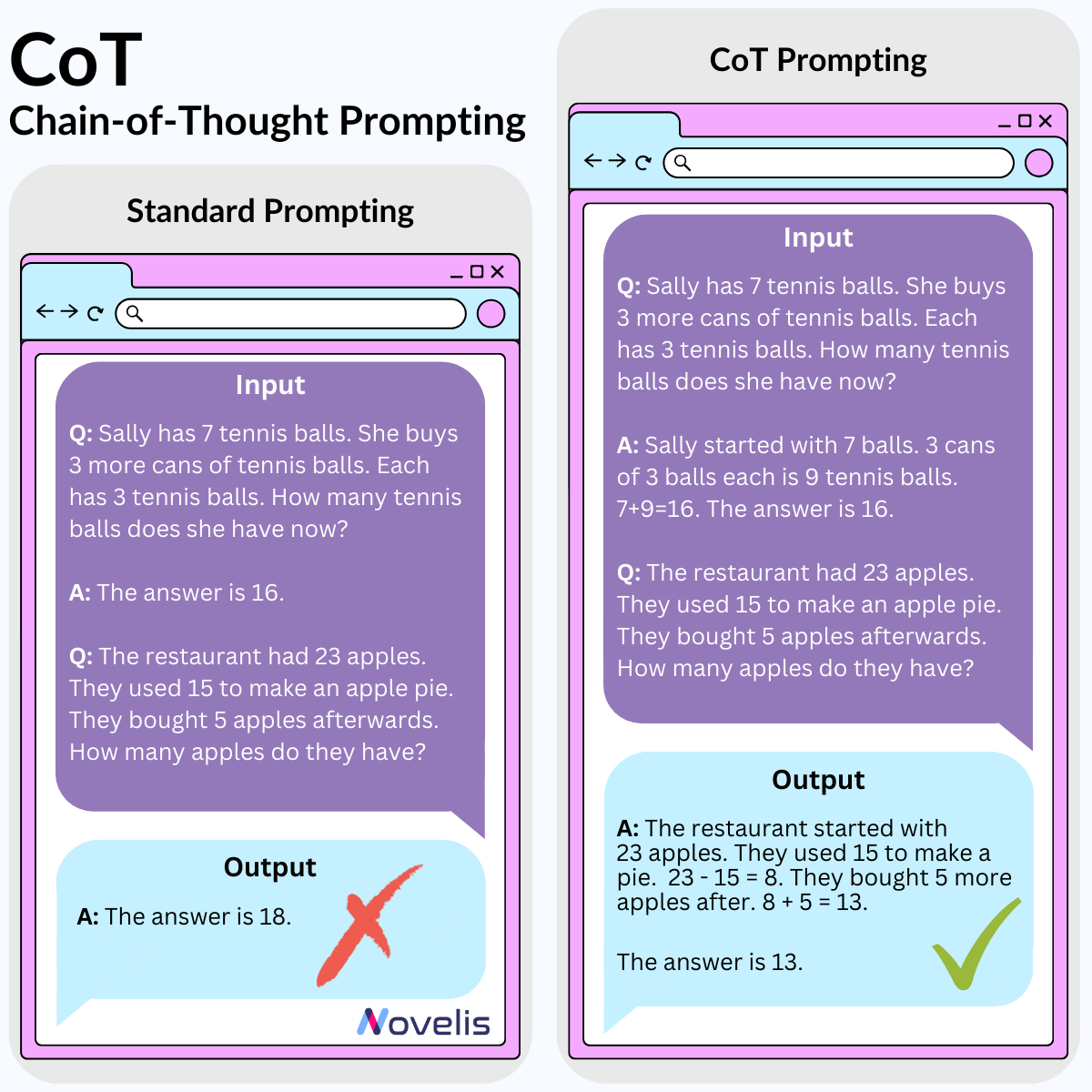
Nous avons exploré comment mieux utiliser les LLM grâce au Chain-of-Thought (CoT), une technique de prompt engineering. Cette méthode consiste à structurer les prompts de manière à décomposer un problème complexe en sous-problèmes plus simples, simulant la façon dont les humains résolvent les problèmes. Cela fonctionne bien pour des tâches de raisonnement arithmétique, de bon sens, et de logique symbolique.
Pourquoi est-ce essentiel ? Appliquer la technique CoT peut améliorer les résultats lorsqu’il s’agit de résoudre des problèmes arithmétiques, de bon sens ou de logique dans les LLM. Cela aide également à comprendre où le modèle pourrait se tromper
