IA dans la Prévision des Séries Temporelles
02/04/2024
2 Avr , 2024 read
Découvrez l’application de l’IA pour utiliser efficacement les données issues des prévisions de séries temporelles.
CHRONOS – Modèle de Base pour la Prévision des Séries Temporelles

La prévision des séries temporelles est cruciale pour la prise de décision dans divers domaines, tels que le commerce de détail, l’énergie, la finance, la santé et la climatologie. Voyons comment l’IA peut être exploitée pour tirer parti de ces données essentielles.
L’émergence des techniques d’apprentissage profond a remis en question les modèles statistiques traditionnels qui dominaient la prévision des séries temporelles. Ces techniques sont en grande partie possibles grâce à la disponibilité d’importantes quantités de données de séries temporelles. Cependant, malgré les performances impressionnantes des modèles d’apprentissage profond, le besoin d’un modèle de prévision généraliste « fondamental » reste crucial dans ce domaine.
Des efforts récents ont exploré l’utilisation des grands modèles de langage (LLM) dotés de capacités d’apprentissage sans exemple (zero-shot) pour la prévision des séries temporelles. Ces approches sollicitent directement des LLM préentraînés ou les ajustent pour les tâches spécifiques de séries temporelles. Cependant, elles nécessitent toutes des ajustements spécifiques à la tâche ou des modèles coûteux en termes de calcul.
Avec Chronos, présenté dans le nouvel article “Chronos: Learning the Language of Time Series” de l’équipe d’Amazon, une approche innovante est adoptée en traitant les séries temporelles comme un langage et en les découpant en unités discrètes. Cela permet d’entraîner des modèles de langage standard sur le « langage des séries temporelles » sans modifier l’architecture traditionnelle des modèles linguistiques.
Les modèles Chronos préentraînés, avec des tailles allant de 20 à 710 millions de paramètres, sont basés sur la famille T5 et entraînés sur un ensemble de données diversifié. De plus, des stratégies d’augmentation des données sont mises en œuvre pour pallier le manque de jeux de données de séries temporelles de haute qualité accessibles au public. Chronos est désormais le modèle de prévision de référence en apprentissage sans exemple et pour des tâches spécifiques, surpassant les modèles traditionnels et les approches d’apprentissage profond spécifiques aux tâches.
Pourquoi est-ce essentiel ? En tant que modèle linguistique opérant sur un vocabulaire fixe, Chronos s’intègre parfaitement avec les avancées futures des LLM, le positionnant comme un candidat idéal pour devenir un modèle de séries temporelles généraliste à long terme.
Séries Temporelles Multivariées – Un Cadre Basé sur les Transformers pour l’Apprentissage de Représentations des Séries Temporelles Multivariées
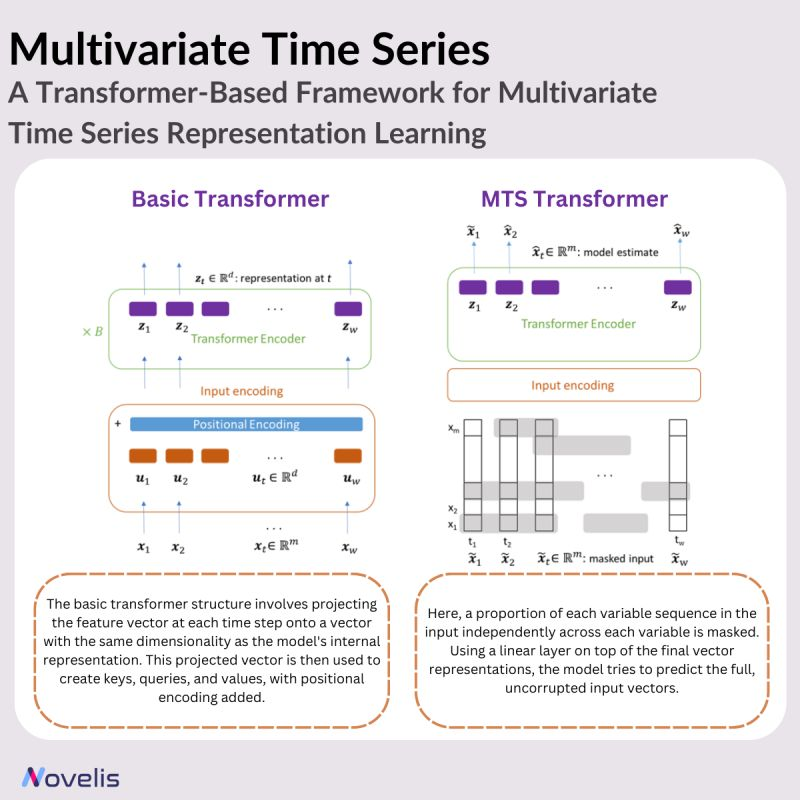
Les données de séries temporelles multivariées (MTS) sont courantes dans divers domaines, notamment la science, la médecine, la finance, l’ingénierie et les applications industrielles. Elles suivent simultanément plusieurs variables au fil du temps. Malgré l’abondance de données MTS, les données étiquetées pour entraîner des modèles restent rares. Cet article présente un cadre basé sur les transformers pour l’apprentissage non supervisé de représentations des séries temporelles multivariées, en fournissant un aperçu d’un article de recherche intitulé « A Transformer-Based Framework for Multivariate Time Series Representation Learning, » rédigé par une équipe d’IBM et de l’Université Brown. Les modèles préentraînés issus de ce cadre peuvent être appliqués à diverses tâches en aval, telles que la régression, la classification, la prévision et l’imputation de valeurs manquantes.
Méthode
L’idée principale de cette approche consiste à utiliser un encodeur transformer. Le modèle transformer est adapté du transformer traditionnel pour traiter des séquences de vecteurs de caractéristiques qui représentent des séries temporelles multivariées, au lieu de séquences d’indices de mots discrets. Des encodages positionnels sont intégrés pour que le modèle comprenne la nature séquentielle des données de séries temporelles. Dans un cadre de préentraînement non supervisé, le modèle est entraîné à prédire des valeurs masquées dans le cadre d’une tâche de débruitage autorégressif, où certaines entrées sont masquées.
Concrètement, une proportion de chaque séquence de variable dans l’entrée est masquée de manière indépendante pour chaque variable. En ajoutant une couche linéaire au-dessus des représentations vectorielles finales, le modèle tente de prédire les vecteurs d’entrée complets et non corrompus. Cette approche de préentraînement non supervisée exploite les mêmes échantillons de données étiquetés et, dans certains cas, démontre des améliorations de performance même par rapport aux méthodes entièrement supervisées. Comme pour toute architecture de transformer, le modèle préentraîné peut être utilisé pour des tâches de régression et de classification en ajoutant des couches de sortie.
Résultats
L’article présente une approche intéressante d’utilisation des modèles basés sur les transformers pour l’apprentissage efficace de représentations dans les données de séries temporelles multivariées. Lors de l’évaluation sur divers ensembles de données de référence, il montre des améliorations par rapport aux méthodes existantes et les surpasse dans la régression et la classification des séries temporelles multivariées. Le cadre démontre une performance supérieure même avec un nombre limité d’échantillons d’entraînement, tout en maintenant une efficacité computationnelle.
