Pourquoi 2025 est l’année où les benchmarks IA sont morts et où les “vibes” ont pris le relais
20/02/2026
20 Fév , 2026 read
Il y a à peine douze mois, l’industrie se demandait encore si l’intelligence artificielle pouvait écrire de manière fiable une simple fonction. Aujourd’hui, la question n’est plus « peut-elle coder ? » mais « pourquoi suis-je encore en train de lire le code ? ».
Selon l’Artificial Intelligence Index Report 2025, nous avons franchi un seuil vertigineux : 25 % des startups des dernières cohortes disposent de bases de code générées à 95 % par l’IA. La vitesse des progrès a créé une crise fondamentale : nous construisons désormais des systèmes plus vite que nous ne sommes capables de créer des méthodes pertinentes pour les évaluer.
À mesure que nous entrons dans une ère marquée par les workflows agentiques et le « vibe coding », nous constatons que si les barrières techniques des géants s’estompent, l’écart entre la productivité perçue et la fiabilité réelle continue de se creuser.
La crise de saturation des benchmarks
Le signal le plus frappant du rapport AI Index 2025 est l’effondrement des méthodes de test traditionnelles. L’IA maîtrise les benchmarks plus vite que les chercheurs ne peuvent en publier.
En 2023, les systèmes peinaient sur le nouveau SWE-bench, ne résolvant que 4,4 % des problèmes logiciels réels. En 2024, ce chiffre a bondi à 71,7 %. Les performances techniques ont suivi une trajectoire quasi verticale : MMMU a progressé de 18,8 points et GPQA — un examen de niveau master conçu pour être « impossible à résoudre via Google » — a gagné 48,9 points en une seule année.
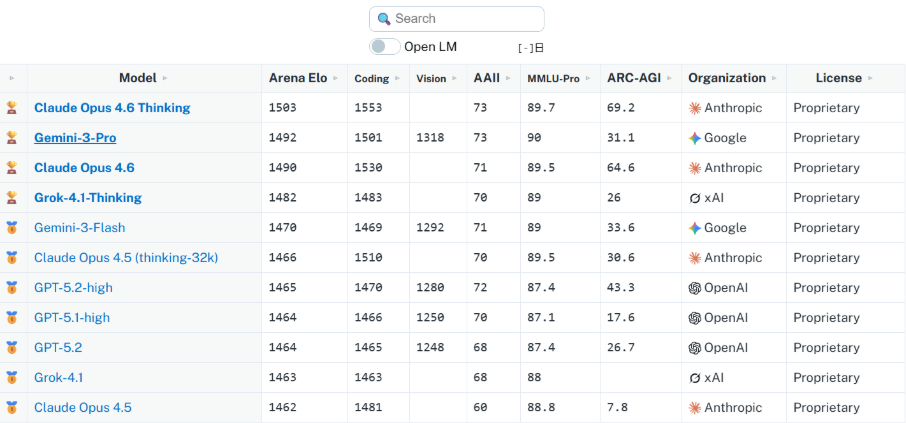
La réalité stratégique est que nous assistons à une « convergence humain-machine » aux frontières de l’intelligence.
Sur le benchmark MMMU, qui mesure le raisonnement de niveau expert, le meilleur modèle — o1 d’OpenAI — a obtenu 78,2 %, à seulement 4,4 points de la référence humaine (82,6 %). Cette saturation a poussé l’industrie vers de nouveaux tests comme « Humanity’s Last Exam » et « FrontierMath », où les systèmes restent en difficulté avec respectivement 8,8 % et 2 % de réussite.
Comme le souligne le rapport :
« Les progrès rapides des systèmes d’IA, illustrés par leurs performances supérieures constantes aux benchmarks, sont peut-être mieux montrés par la diminution de la pertinence du test historique de l’IA : le test de Turing… signalant que les modèles modernes peuvent désormais le réussir. »

La grande convergence : parité des modèles open-weight
Pendant près de deux ans, les modèles propriétaires à poids fermés disposaient d’un net avantage. En 2024, cet avantage a disparu.
Le rapport 2025 montre une réduction spectaculaire de l’écart entre les modèles propriétaires dominants et les alternatives open-weight. Sur le classement Chatbot Arena, l’écart entre le meilleur modèle propriétaire et le meilleur open-weight est passé de 8,04 % début 2024 à seulement 1,70 % en février 2025.
Cette parité a été portée par la sortie de Llama 3.1 405B de Meta et l’émergence de DeepSeek-V3.
Pour les analystes, le message est clair : l’avantage ne se situe plus dans les poids du modèle eux-mêmes, mais dans leur orchestration et leur intégration dans des logiques métiers spécifiques.
Efficacité multipliée par 142 : l’essor des modèles « mini »
Si la logique « plus grand = meilleur » reste valable pour le raisonnement avancé, 2024 a été l’année de l’optimisation algorithmique.
Nous assistons à une démocratisation radicale des capacités de pointe : des modèles plus petits atteignent désormais les performances des géants d’hier.
En 2022, le plus petit modèle capable d’obtenir 60 % sur MMLU était PaLM de Google avec 540 milliards de paramètres. En 2024, Phi-3-mini de Microsoft a atteint ce seuil avec seulement 3,8 milliards de paramètres — une réduction par 142.
Ce gain d’efficacité est stratégique. Il permet aux développeurs de se passer de clusters cloud lourds au profit d’une IA embarquée sur appareil. Résultat : latence réduite, meilleure confidentialité et fragmentation du paysage technologique, avec une IA qui s’éloigne des infrastructures centralisées pour devenir omniprésente et locale.
Du « vibe coding » à l’ingénierie agentique
Cette parité technique a donné naissance au « vibe coding ».
Défini par Andrej Karpathy début 2025, il consiste à suivre les « vibes » d’un chatbot et ignorer totalement le code sous-jacent. Comme il l’a résumé :
« Je clique toujours sur “tout accepter”, je ne lis plus les différences… Le code dépasse ma compréhension habituelle… Je vois des choses, je dis des choses, j’exécute des choses et je copie-colle, et la plupart du temps ça marche. »
Mais nous entrons maintenant dans le « retour de bâton du vibe coding ».
Le rapport 2025 met en avant une étude METR préoccupante : les développeurs expérimentés étaient en réalité 19 % plus lents avec l’IA, tout en pensant être 20 % plus rapides. Cette dissonance est risquée : le code co-écrit par l’IA contient 1,7 fois plus de problèmes majeurs, dont une hausse de 2,74 fois des failles de sécurité.
Une analyse de GitClear montre aussi que le refactoring — essentiel à la qualité logicielle — est passé de 25 % du code en 2021 à moins de 10 % en 2024, tandis que la duplication et l’instabilité du code ont presque doublé.
En réaction, un nouveau mouvement émerge : l’« ingénierie agentique ».
Porté par des modèles comme GLM-5 de Zhipu AI, classé 4e mondial et atteignant 77,8 sur SWE-bench-Verified, il marque un retour à une logique systémique plutôt qu’à la simple prédiction de texte, afin de réintroduire de la fiabilité dans un écosystème dominé par la rapidité.
Le basculement géopolitique : la Chine comble l’écart
Signal stratégique majeur : la Chine a atteint la parité avec les modèles américains malgré les restrictions sur les semi-conducteurs.
En 2023, les modèles américains dominaient de 31,6 points sur les tâches de code et 17,5 points sur MMLU. Fin 2024, ces écarts sont presque nuls : 3,7 et 0,3 points.
Des modèles comme DeepSeek-V3 et DeepSeek-R1 ont attiré l’attention mondiale en atteignant des performances de pointe avec une fraction des ressources matérielles occidentales.
Cela suggère que l’efficacité algorithmique — plus que la puissance brute de calcul — devient le principal terrain de compétition géopolitique.
Le coût du raisonnement : le calcul au moment de l’exécution
Nous entrons dans un nouveau paradigme : la performance définie par le calcul au moment du test (« test-time compute »).
Des modèles comme o1 et o3 d’OpenAI utilisent un raisonnement itératif pour résoudre des problèmes qui bloquaient auparavant les LLM. Résultat : o1 a obtenu 74,4 % aux épreuves de qualification des Olympiades internationales de mathématiques, contre 9,3 % pour GPT-4o.
Mais le compromis est important : ce « temps de réflexion » rend o1 30 fois plus lent et 6 fois plus coûteux que ses prédécesseurs.
Le rapport 2025 avertit aussi que ce raisonnement complexe reste peu fiable pour des tâches nouvelles ou plus vastes que les données d’entraînement. Cette incertitude reste le principal frein à l’usage de l’IA dans des contextes à haut risque où la justesse doit être garantie.
Conclusion
En 2025, nous sommes passés de l’ère du « peut-elle le faire ? » à celle du « est-ce fiable ? ».
Nous avançons vers un futur de « logiciel pour un seul utilisateur », illustré par des expériences comme « LunchBox Buddy » de Kevin Roose, où des non-développeurs créent leurs propres outils à la volée. Mais il faut rester lucide. Comme le note le chercheur Gary Marcus, beaucoup de ces productions relèvent davantage de la reproduction que de l’originalité.
Nous construisons un futur fondé sur des « vibes » et un renouvellement massif du code.
Alors que l’IA s’apprête à réussir « l’ultime examen de l’humanité » d’ici 2026, le véritable test ne sera pas pour les machines, mais pour nous.
Si nous ne pouvons plus distinguer le code humain du code machine, et si nous ne comprenons plus les systèmes que nous utilisons, avons-nous réellement gagné en productivité — ou simplement externalisé notre expertise vers une boîte noire ?
Pour aller plus loin
- IBM’s Mixture of Experts Podcast , Episode 93.5 | Bonus episode, Anthropic vs OpenAI: Claude Opus 4.6 & GPT-5.3-Codex: https://www.ibm.com/think/podcasts/mixture-of-experts/anthropic-vs-openai-claude-opus-4-6-gpt-5-3-codex
- Constitutional Spec-Driven Development: Enforcing Security by Construction in AI-Assisted Code Generation: https://www.arxiv.org/pdf/2602.02584
- The vibe coding hangover is upon us: https://www.fastcompany.com/91398622/the-vibe-coding-hangover-is-upon-us
