Why 2025 is the Year AI Benchmarks Died and “Vibes” Took Over
20/02/2026
Feb 20 , 2026 read
Just twelve months ago, the industry was debating whether artificial intelligence could reliably write a single function. Today, the conversation has shifted from “can it code?” to “why am I still reading the code?” According to the Artificial Intelligence Index Report 2025, we have reached a dizzying threshold where 25% of startups in recent cohorts possess codebases that are 95% AI-generated. The velocity of advancement has created a fundamental crisis: we are now building systems faster than we can create meaningful ways to evaluate them. As we move into an era defined by agentic workflows and “vibe coding,” we are discovering that while the technical moats of the giants are evaporating, the gap between perceived productivity and actual reliability is widening.
The Benchmark Saturation Crisis
The most striking signal in the 2025 AI Index is the absolute collapse of traditional testing. AI is mastering benchmarks faster than researchers can publish them. In 2023, systems were struggling with the newly introduced SWE-bench, solving a meager 4.4% of real-world software issues. By 2024, that figure surged to 71.7%. Technical performance across the board has seen a vertical trajectory, with MMMU showing an 18.8-point jump and GPQA – a graduate-level “Google-proof” exam – seeing a staggering 48.9-point increase in a single year.
The strategic reality is that we are witnessing a “human-machine convergence” at the edge of intelligence. On the MMMU benchmark for expert-level reasoning, the best-performing model, OpenAI’s o1, scored 78.2% – now within a razor-thin 4.4-point margin of the human baseline (82.6%). This saturation has forced the industry toward “Humanity’s Last Exam” and “FrontierMath,” where systems still struggle at 8.8% and 2% respectively. As the report notes:
“The rapid progress of AI systems, evidenced by their consistent outperformance on benchmarks, is perhaps best illustrated by the diminishing relevance of the well-known and long-standing challenge for AI: the Turing test… signaling that modern AI models can pass the Turing test.”

The Great Convergence: Open-Weight Parity
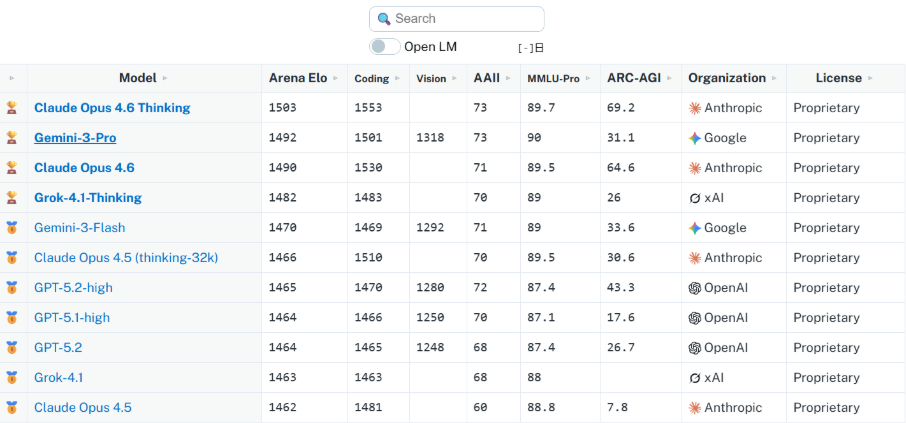
For the better part of two years, “closed-weight” proprietary models held a distinct performance moat. In 2024, that moat was filled. The 2025 Index reveals a monumental narrowing of the gap between the proprietary “God models” and open-weight alternatives. On the Chatbot Arena Leaderboard, the gap between the top closed-weight model and the leading open-weight model shrank from 8.04% in early 2024 to a mere 1.70% by February 2025.
This “SOTA parity” has been driven by the release of Meta’s Llama 3.1 405B and the emergence of DeepSeek-V3. For strategy analysts, the signal is clear: the advantage no longer lies in the weights themselves, but in the orchestration and integration of those weights into specific business logic.
142x Efficiency: The Rise of the “Mini” Models
While the “bigger is better” scaling laws still hold for frontier reasoning, 2024 was the year of the algorithmic squeeze. We are seeing a radical democratization of the frontier as smaller models achieve the performance of yesterday’s giants. In 2022, the smallest model capable of scoring 60% on MMLU was Google’s PaLM at 540 billion parameters. By 2024, Microsoft’s Phi-3-mini matched that threshold with only 3.8 billion parameters – a 142-fold reduction in size.
This efficiency shift is strategically vital. It allows developers to bypass CUDA-heavy cloud clusters in favor of “on-device” AI. This reduces latency, improves privacy, and effectively fragments the instruction set architecture (ISA) landscape, moving AI away from centralized power and toward ubiquitous, localized execution.
From “Vibe Coding” to Agentic Engineering
This technical parity has birthed the “Vibe Coding” movement. As defined by Andrej Karpathy in early 2025, this practice involves giving in to the “vibes” of a chatbot and ignoring the underlying code entirely. As Karpathy famously tweeted:
“I ‘Accept All’ always, I don’t read the diffs anymore… The code grows beyond my usual comprehension… I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.”
However, we are now entering the “Vibe Coding Hangover.” The 2025 Index highlights a troubling METR study: experienced developers were actually 19% slower when using AI tools, despite believing they were 20% faster. This cognitive dissonance is dangerous; while users feel more productive, code co-authored by AI contains 1.7x more “major” issues, including a 2.74x spike in security vulnerabilities. A longitudinal analysis by GitClear found that code refactoring – the backbone of healthy software – has dropped from 25% in 2021 to under 10% in 2024, as duplication and “code churn” nearly doubled.
The counter-movement is “Agentic Engineering,” championed by models like Zhipu AI’s GLM-5. Ranking #4 globally and achieving a SOTA score of 77.8 on SWE-bench-Verified, GLM-5 represents a shift toward systemic logic over simple text prediction, attempting to bring reliability back to a world currently intoxicated by vibes.
The Geopolitical Flip: China Closes the Gap
Perhaps the most significant strategic signal in the report is that China has achieved parity with U.S. models despite aggressive semiconductor export controls. In 2023, American models led by 31.6 points on coding tasks and 17.5 points on MMLU. By the end of 2024, those gaps have functionally evaporated, narrowing to just 3.7 and 0.3 points, respectively.
Models like DeepSeek-V3 and DeepSeek-R1 have garnered global attention for achieving these state-of-the-art results using only a fraction of the hardware resources typically required by Western counterparts. This suggests that algorithmic efficiency, rather than raw compute volume, is now the primary theater of geopolitical competition.
The Cost of Reasoning: Test-Time Compute
We are entering a new paradigm of performance defined by “test-time compute.” Models like OpenAI’s o1 and o3 use iterative reasoning to solve problems that previously stumped LLMs. The results are undeniable: o1 scored 74.4% on International Mathematical Olympiad qualifying exams, compared to GPT-4o’s 9.3%.
However, there is a massive tradeoff. This “thinking” makes o1 30 times slower and 6 times more expensive than its predecessors. Furthermore, the 2025 Index warns that complex reasoning remains a problem for tasks that are larger or more complex than the original training set. This lack of reliability in novel scenarios remains the primary barrier to using AI in high-risk applications where “provably correct” logic is a requirement, not a suggestion.
Conclusion
In 2025, we have transitioned from the era of “can it do this?” to the era of “is it reliable?” We are moving toward the “software for one” future, illustrated by experiments like Kevin Roose’s “LunchBox Buddy,” where non-coders build bespoke tools on the fly. Yet, as analysts, we must remain skeptical. As cognitive scientist Gary Marcus notes, much of this feels like “reproduction rather than originality.”
We are building a future on a foundation of “vibes” and massive “code churn.” As AI prepares to pass “Humanity’s Last Exam” by 2026, the real test won’t be for the machines – it will be for us. If we can no longer distinguish human code from machine code, and we no longer understand the systems we use, have we actually gained productivity, or have we simply outsourced our expertise to a black box?
Further readings
- IBM’s Mixture of Experts Podcast , Episode 93.5 | Bonus episode, Anthropic vs OpenAI: Claude Opus 4.6 & GPT-5.3-Codex: https://www.ibm.com/think/podcasts/mixture-of-experts/anthropic-vs-openai-claude-opus-4-6-gpt-5-3-codex
- Constitutional Spec-Driven Development: Enforcing Security by Construction in AI-Assisted Code Generation: https://www.arxiv.org/pdf/2602.02584
- The vibe coding hangover is upon us: https://www.fastcompany.com/91398622/the-vibe-coding-hangover-is-upon-us
