Découvrez notre article JaCoText : A Pretrained Model for Java Code-Text Generation publié dans le journal « World Academy of Science, Engineering and Technology« . Notre équipe de recherche a également présenté ses travaux lors de la Conférence internationale sur la génération et l’implémentation de codes : regarder le replay. Merci à l’équipe de recherche de Novelis pour ses connaissances et son expérience.
Pour citer cet article, merci d’utiliser : Espejel, J. , Alassan, M. , Dahhane, W. , Ettifouri, E. (2023). ‘JaCoText: A Pretrained Model for Java Code-Text Generation’. World Academy of Science, Engineering and Technology, Open Science Index 194, International Journal of Computer and Systems Engineering, 17(2), 100 – 105.
Abstract
En traitement du langage naturel (NL), plusieurs modèles pré-entraînés tels que BERT, BART et T5 ont atteint de bonnes performances dans la génération des langages de programmation (PL) comme le Java et le Python. Dans cet article, nous présentons Text2Java: un système composé de trois modèles pour générer du code Java à partir du langage naturel. Nos modèles tirent parti de certains critères pour améliorer les performances des modèles proposés par Raffel et al. (2020), Beltagy et al. (2019), et Lee et al. (2020). Nous explorons le pré-apprentissage supplémentaire avec les deux architectures : et . D’une part, lorsque nous utilisons l’architecture , nous commençons l’apprentissage à partir des checkpoints CoTexT déjà entraînés sur les datasets C4 et CodeSearchNet. D’une autre part, l’apprentissage utilisant est lancé directement à partir du checkpoint précédemment entraîné sur le dataset C4. Les expérimentations montrent que les modèles Text2Java atteignent les résultats de l’état de l’art, démontrant ainsi leur efficacité.
1 Introduction
Pour développer des logiciels informatiques, les programmeurs combinent entre le langage naturel (natural language, NL) et le langage de programmation (programming language, PL). Le langage naturel est utilisé dans la documentation des logiciels, comme les doc-strings pour décrire les méthodes et les classes. La documentation de certains projets dans une grande variété de langages de programmation est accessible à travers des sites web comme Stack Overflow, GitHub, GeeksforGeeks, et W3Schools.
Récemment, la communauté scientifique a développé plusieurs systèmes qui ont pour but de générer automatiquement du code source dans différents langages de programmation. Ces modèles sont inspirés des modèles de langage (Language Models, LMs) pré-entraînés, conçus à l’origine pour aborder différentes tâches telles que la synthèse de texte (Zhang et al., 2019), la réponse aux questions (Khashabi et al., 2018; Clark et al., 2019), et l’analyse des sentiments (Mohanty et al., 2021).
Selon les études les plus récentes de l’état de l’art, le succès des LMs dépend de certains critères, tels que l’utilisation de gros volumes de données pour le pré-apprentissage, les fonctions de coût utilisées lors de l’entraînement telles que la modélisation du langage masqué (MLM) utilisée dans BERT (Devlin et al., 2018), l’erreur de mélange (Liu et al., 2019a), la modélisation du langage causal (CLM) (Radford et Narasimhan, 2018), la substitution aléatoire de tokens (RTS) et le modèle de langage échangé (SLM) proposé par Liello et al. (2021). De plus, certains modèles tels que SciBERT (Beltagy et al., 2019) et BioBERT (Lee et al., 2020) ont montré les avantages du pré-apprentissage du modèle en utilisant des données liées à une tâche spécifique.
En s’inspirant des études précédentes, nous introduisons le modèle TexT2Java, un modèle pré-entraîné basé sur les Transformeurs (Vaswani et al., 2017), et inspiré par (Raffel et al., 2020) et CoTexT (Phan et al., 2021) . TexT2Java utilise certains critères pour améliorer les performances du modèle proposé par Raffel et al., 2020, Beltagy et al., 2019, et Lee et al., 2020. Par exemple, en se basant sur le succès de CodeGPT-adapté, nous commençons l’apprentissage à partir des checkpoints CoTexT-1CC et CoTexT-2CC, au lieu de faire un apprentissage à partir du zéro. Étant donné que le but de notre modèle est de générer du code java, nous avons effectué un pré-apprentissage supplémentaire en utilisant des données appartenant à un langage de programmation spécifique (java). La Figure 1 décrit le pré-apprentissage supplémentaire sur chaque checkpoint. De même, nous augmentons la longueur d’entrée et de sortie dans la phase de fine-tuning.
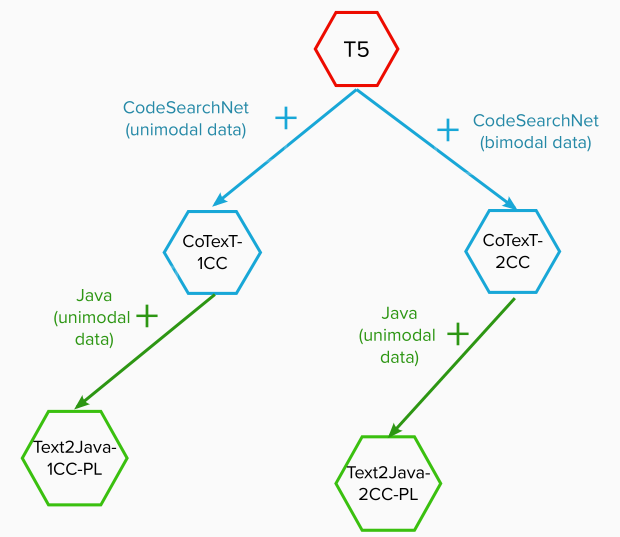
Contrairement aux modèles de génération de langage naturel tels que BERT (Devlin et al., 2018) et PEGASUS (Zhang et al., 2019), notre modèle de génération du code java doit apprendre les règles de grammaire (Rabinovich et al., 2017) et de syntaxe (Yin and Neubig, 2017). La Figure 2 montre un exemple d’une séquence donnée en entrée du réseau de neurones, le code de référence (gold standard) que le modèle est censé générer et la prédiction du réseau.

Nos contributions sont comme suit :
- Nous montrons que les modèles Text2Java apprennent mieux la syntaxe java lorsque nous faisons un apprentissage supplémentaire
- Nous présentons des expériences combinant les données unimodales et bimodales pendant l’apprentissage
- Nous montrons différents ensembles d’expériences pour comprendre le comportement des modèles T5 dans la tâche de génération du Java
- Nous surpassons les scores obtenus par les modèles PLBART, CodeGPT, CodeGPT-adapté et CoTexT
2 Text2Java
2.1 Fine-tuning
Nous affinons nos modèles en fonction de deux critères :
Longueur des séquences. Selon notre analyse des sorties générés par les méthodes de l’état de l’art, nous avons observé que certaines séquences de code produites par les modèles étaient incomplètes par rapport à nos cibles. Par conséquent, nous avons tokenisé l’ensemble d’apprentissage et de validation avec le modèle Sentence Piece (Kudo and Richardson, 2018). À partir de ce dataset, nous avons obtenu la plus grande longueur de séquence et nous l’avons utilisée comme valeur pour les entrées et les cibles.
Nombre de pas. Puisque nous avons augmenté la longueur des séquences dans notre modèle, nous avons augmenté aussi le nombre de pas dans le fine-tuning.
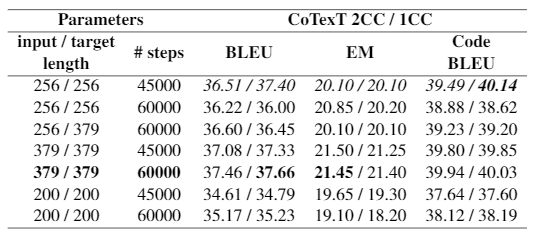
Tout d’abord, nous appliquons les deux critères en commençant le fine-tuning à partir des checkpoints de CoTexT 2CC et 1CC, respectivement. D’une part, CoTexT-1CC est pré-entraîné sur des données unimodales (uniquement du code), et CoTexT-2CC est pré-entraîné sur des données bimodales (qui contiennent du code et du langage naturel). Les résultats de ces expériences sont présentés dans le Tableau 2.
2.2 Pré-apprentissage supplémentaire
Raffel et al., 2020 a fait quelques observations importantes dans lesquelles nous étayons notre travail : 1) pour certaines tâches spécifiques, la façon d’améliorer les performances du modèle est de le pré-entraîner avec des corpus qui appartiennent à ce domaine spécifique, 2) un pré-apprentissage supplémentaire peut améliorer les performances des réseaux de neurones, 3) un faible nombre d’époques dans le modèle de pré-apprentissage donne des scores plus élevés dans les tâches de génération. De plus, CodeGPT entraîné à partir de zéro a atteint des scores inférieurs à ceux de CodeGPT-adapté qui est entraîné à partir du checkpoint de GPT-2.
Sur la base des points mis en évidence précédemment, nous avons initialisé les modèles Text2Java-B-1CC-PL et Text2Java-B-2CC-PL à partir des poids de CoTexT-1CC et CoTexT-2CC (Phan et al., 2021), respectivement. Nous utilisons notre jeu de données Java pour faire un apprentissage auto-supervisé avec les séquences de code seulement. De même, nous avons initialisé le modèle Text2Java-L-1CC-PL à partir des poids de déjà entraînés sur le jeu de données C4. Contrairement aux modèles Text2Java-B, dans le Text2Java-L-1CC-PL, nous avons d’abord entraîner notre modèle sur CodeSearchNet, puis sur notre jeu de données Java.
Architecture Text2Java utilise la même architecture que T5 (Raffel et al., 2020), basée sur les Transformeurs (Vaswani et al., 2017). D’une part, se compose de 12 couches dans l’encodeur et de 12 couches dans le décodeur, avec une dimension de modèle de 768 et 12 têtes (environ 220 millions de paramètres). D’autre part, a 24 couches dans l’encodeur et le décodeur chacun, avec une dimension de modèle de 1024 et 16 têtes (environ 770 millions de paramètres).
Entrée/Sortie L’entrée de l’encodeur est un code Java bruyant. L’entrée du décodeur est le code java d’origine avec un décalage de position.
3. Expérimentation
3.1 Dataset de génération de code
Pour la tâche de génération de code Java, nous avons utilisé CONCODE (Iyer et al., 2018), qui est un dataset contenant le contexte d’un environnement de programmation Java réel. L’objectif de CONCODE est de générer des fonctions membres Java qui ont des variables de membre de classe à partir de la documentation. Le Tableau 1 décrit le dataset CONCODE.

3.2 Dataset de pré-apprentissage supplémentaire
Pour le pré-apprentissage supplémentaire, nous avons utilisé notre jeu de données Java. À l’origine, il se compose de 812 008, 40 468, et 51 210 données d’apprentissage, de validation et de test, respectivement. Nous avons supprimé les données contenant des erreurs syntaxique dans les trois ensembles : 2 974 dans l’ensemble d’apprentissage, 235 dans l’ensemble de validation et 161 dans l’ensemble de test. Nous avons utilisé le reste des données pour l’apprentissage. Cela signifie qu’au total, nous avons utilisé 900 316 données pour pré-entraîner notre modèle.
3.3 Métriques d’évaluation
Pour évaluer nos résultats, nous utilisons les trois mesures décrites ci-dessous.
BLEU (Papineni et al., 2002) est une métrique basée sur une précision de n-gramme calculée entre le candidat et la/les références. La précision N-gramme applique une pénalisation si des mots apparaissent dans un candidat et dans aucune des références, si un mot apparaît plus de fois dans le candidat que dans le nombre maximal de références. Par ailleurs, la métrique échoue si le candidat n’a pas la longueur appropriée. Tout comme Ahmad et al., (2021) et Phan et al., (2021), nous utilisons le score BLEU au niveau du corpus dans la tâche de génération de code.
CodeBLEU (Ren et al., 2020) fonctionne via une correspondance n-gram, et il prend en compte à la fois la correspondance syntaxique et sémantique. La correspondance syntaxique est obtenue par la correspondance entre le candidat de code et les sous-arbres de référence de code de l’arbre de syntaxe abstraite (AST). La correspondance sémantique tient compte de la structure du flux de données.
Exact Match (EM) est le rapport du nombre de prédictions qui correspondent exactement à l’une des références de code.
3.4 Lignes de base
Nous comparons notre modèle avec des modèles de pointe basés sur les Transformeurs.
CodeGPT ou CodeGPT-adapté sont basés sur le modèle GPT-2 (Budzianowqki and Vulic,2019). La différence entre les deux modèles est que CodeGPT est entraîné à partir de zéro sur le dataset CodeSearchNet (Husain et al., 2019) et que CodeGPT-adapté est initialisé à partir du checkpoint de GPT-2.
PLBART (Ahmad et al., 2021) utilise la même architecture que (Lewis et al., 2020). De plus, PLBART utilise trois stratégies de bruit: le masquage de jeton, la suppression de jeton et le remplissage de jeton.
CoTexT (Phan et al., 2021) utilise la même architecture que . Il est entraîné à la fois sur des données unimodales et bimodales à l’aide de CodeSearchNet Corpus (Husain et al., 2019) et des référentiels GitHub.
4 Travail connexe
Il y a eu des approches intéressantes pour mapper le NL au code source, telles que les expressions régulières (Locascio et al., 2016), les requêtes de base de données (Xu et al., 2017 ; Zhong et al., 2017), et plus récemment les réseaux de neurones ont prouvé leur efficacité pour générer automatiquement du code source à partir de différents langages de programmation à usage général comme le Python (Yin and Neubig, 2017) et le Java (Phan et al., 2021). Simultanément, les bases de données ont bondi avec eux, par exemple, CONCODE (Iyer et al., 2018), CONALA (Yin et al., 2018), et CodeSearchNet (Husain et al., 2019).Yin and Neubig (2017) ont utilisé un encodeur BiLSTM et un décodeur RNN pour générer des arbres d’analyse syntaxiquement valides. Inspiré par le décodeur sensible à la grammaire, Lyer et al., 2018 ont utilisé l’encodeur Bi-LSTMs pour calculer les représentations contextuelles du NL, et un décodeur RNN basé sur LSTM avec un mécanisme d’attention en deux étapes suivi d’un mécanisme de copie pour mapper NL avec le code source.
Récemment, les modèles basés sur les réseaux de neurones Transformeurs (Vaswani et al., 2017) et initialement destinés à la génération de langage naturel ont été d’un grand intérêt pour la génération automatique de code. PLBART utilise la même architecture de modèle que (Lewis et al., 2020). Contrairement à , PLBART stabilise l’apprentissage en ajoutant une couche de normalisation en haut de l’encodeur et du décodeur suivant Liu et al.(2020). Semblable à PLBART, CoTexT (Phan et al., 2021) est un modèle d’encodeur-décodeur qui est basé sur l’architecture (Raffel et al., 2020).
De plus, les modèles basés uniquement sur l’encodeur tels que RoBERTa (code) (Lu et al., 2021) inspiré de RoBerTa (Liu et al., 2019b), et les modèles uniquement décodeurs tels que CodeGPT et CodeGPT-adapté ont obtenu des résultats compétitifs à la pointe de la technologie. Semblable à CodeGPT et CodeGPT-adapté, RoBERTa (code) est pré-entraîné sur le dataset CodeSearchNet. Contrairement à RoBERTa (code), CodeGPT est pré-entraîné sur CodeSearchNet à partir de zéro, et CodeGPT-adapté est pré-entraîné à partir des checkpoints de GPT-2 (Budzianowqki and Vulic,2019). CodeGPT et CodeGPT-adapté suivent la même architecture et le même objectif d’apprentissage que GPT-2.
5 Résultats et discussion
Le Tableau 2 montre les résultats que nous avons obtenus après le fine-tuning du modèle sur le dataset CONCODE grâce à la variation du nombre de pas et la longueur de l’entrée et de la sortie des checkpoints de CoTexT-2CC et CoTexT-1CC, respectivement. Les résultats montrent qu’utiliser 60 000 pas donne de meilleurs résultats que d’utiliser 45 000 pas dans le fine-tuning. De plus, en utilisant la plus grande longueur de séquence de code, nous surpassons les scores BLEU et EM obtenus par Phan et al., 2021 (surlignés en italique). Les résultats varient légèrement, avec des différences presque indétectables. Cependant, CoTexT-1CC a obtenu un score plus élevé sur BLEU et CodeBLEU, tandis que CoTexT-2CC a obtenu un score plus élevé sur la métrique EM.
Varier le nombre de pas et augmenter la longueur de l’entrée et de la cible dans le fine-tuning est le premier coup pour améliorer les résultats dans la tâche de génération de code Java. Le deuxième coup est le pré-apprentissage supplémentaire à partir des checkpoints de CoTexT suivant le principe du CodeGPT-Adapté. Après un pré-apprentissage supplémentaire, nous affinons le modèle en utilisant les meilleurs paramètres de valeur que nous avons mis en évidence dans le Tableau 2.
Le Tableau 3 montre les résultats de fine-tuning après le pré-apprentissage supplémentaire à l’aide de notre jeu de données Java. Les modèles commencent par Java-B sont entraînés à partir de l’architecture , et le modèle Text2Java-L-1CC-PL est entraînés à partir de . Comme nous l’avons mentionné précédemment, l’apprentissage supplémentaire utilisant notre jeu de données Java a commencé à partir des checkpoints de CoTexT. Cependant, l’apprentissage du modèle Text2Java-L-1CC-PL a commencé à partir du checkpoint de déjà entraîné sur le jeu de données C4 (Raffel et al., 2020). Nous avons entraîné sur le dataset CodeSearchNet, puis sur notre dataset Java pendant 200 000 pas chacun et en utilisant des données unimodales (uniquement du code). Enfin, nous affinons le modèle sur le jeu de données CONCODE pendant 45 000 pas.
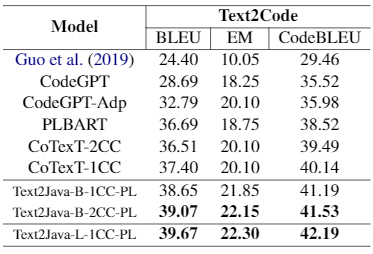
D’après les résultats, nous montrons que trois de nos modèles parviennent à dépasser les résultats de l’état de l’art. Sans surprise, Text2Java-L-1CC-PL obtient les scores les plus élevés dans les trois métriques. Malgré le même protocole d’apprentissage, nous nous attendions à ce que Text2Java-L-1CC-PL obtienne de meilleurs résultats que les deux autres modèles, car a une architecture plus complexe. De plus, les scores obtenus par Java-1CC-PL et Java-2CC-PL n’ont pas de différence abyssale.
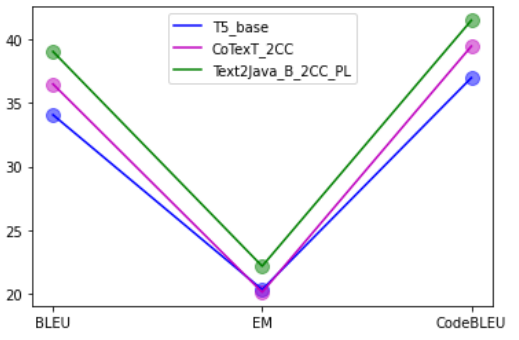
Enfin, la Figure 3 montre les améliorations de notre modèle Text2Java-B-2CC-PL avec un apprentissage supplémentaire utilisant notre jeu de données java. Les trois modèles que nous comparons dans le tableau sont affinés par pas de 60 000 et sont basés sur l’architecture .
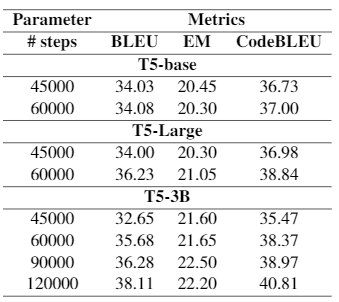
Expérience supplémentaire. Nous étudions les performances du modèle T5 sur la tâche de génération du code java. Nous affinons le dataset CONCODE directement sur trois types de modèles T5 : , et . Nous affinons les modèles T5 en utilisant les meilleurs paramètres que nous avons présentés dans le Tableau 2.
Le Tableau 4 montre les scores de chaque type de modèle T5 directement après le fine-tuning à l’aide du dataset CONCODE. Dans tous les cas, le score s’améliore à mesure que le nombre de pas augmente. Sans surprise, le modèle T5 le plus sophistiqué obtient les meilleurs résultats : , suivi de , et enfin de . De plus, met plus de temps à converger.
6 Conclusion
Nous avons présenté Text2Java, un ensemble de modèles pré-entraînés adéquats pour générer du code java à partir du langage naturel. Text2Java est basé sur les modèles T5 (Raffel et al., 2020).
Nous explorons les performances de deux architectures : et pour générer du code Java. Nous testons quelques points forts proposés par Raffel et al.(2020) pour améliorer les performances du framework T5 dans les tâches de génération de langage, sur la génération de code java. Certains de ces conseils pour pré-entraîner le modèle à l’aide de corpus concernent la tâche spécifique que le modèle va exécuter, et un pré-apprentissage supplémentaire peut améliorer les performances du modèle. En outre, cela suggère d’utiliser un faible nombre d’époques dans le pré-apprentissage, car cela compte dans la performance finale. Nos modèles obtiennent des résultats de pointe sur la tâche de génération de code Java. Dans le futur, des travaux pourraient être intéressants pour explorer les performances d’autres modèles de réseaux de neurones, et améliorer la syntaxe du Nos modèles obtiennent des résultats de pointe sur la tâche de génération de code Java. Dans le futur, des travaux pourraient être intéressants pour explorer les performances d’autres modèles de réseaux de neurones, et améliorer la syntaxe du langage de programmation grâce à l’algorithme de décodage.
Références
Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang. 2021. Unified pre-training for program understanding and generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2655–2668, Online. Association for Computational Linguistics
Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. SciB-ERT: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3615–3620, Hong Kong, China. Association for Computational Linguistics
Paweł Budzianowski and Ivan Vulic. 2019. Hello, it’s gpt-2 – how can i help you? towards the use of pretrained language models for task-oriented dialogue systems. In EMNLP.
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936, Minneapolis, Min- nesota. Association for Computational Linguistics.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. Cite arxiv:1810.04805Comment: 13 pages.
Daya Guo, Duyu Tang, Nan Duan, Ming Zhou, and Jian Yin. 2019. Coupling retrieval and meta-learning for context-dependent semantic parsing. In Proceedings of the 57th Conference of the Association for Compu- tational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 855–866. Association for Computational Linguistics
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. Code- searchnet challenge: Evaluating the state of semantic code search. CoRR, abs/1909.09436.
Srini Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2018. Mapping language to code in programmatic context. In EMNLP.
Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. 2018. Looking beyond the surface:a challenge set for reading comprehension over multiple sentences. In NAACL.
Taku Kudo and John Richardson. 2018. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018: System Demonstrations, Brussels, Belgium, October 31 – November 4, 2018, pages 66–71. Association for Computational Linguistics.
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36:1234 – 1240.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy,
Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Luca Di Liello, Matteo Gabburo, and Alessandro Moschitti. 2021. Efficient pre-training objectives for transformers. ArXiv, abs/2104.09694.
Peter J. Liu, Yu-An Chung, and Jie Ren. 2019a. Summae: Zero-shot abstractive text summarization using length-agnostic auto-encoders. ArXiv abs/1910.00998.
Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 2020. Multilingual denoising pre- training for neural machine translation. Transac- tions of the Association for Computational Linguistics, 8:726–742.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019b. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
Nicholas Locascio, Karthik Narasimhan, Eduardo DeLeon, Nate Kushman, and Regina Barzilay. 2016. Neural generation of regular expressions from natural language with minimal domain knowledge. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1918 1923, Austin, Texas. Association for Computational Linguistics.
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. Codexglue: A machine learning benchmark dataset for code understanding and generation. CoRR, abs/2102.04664.
Ipsita Mohanty, Ankit Goyal, and Alex Dotterweich. 2021. Emotions are subtle: Learning sentiment based text representations using contrastive learning.
Kishore Papineni, Salim Roukos, Todd Ward, and WeiJing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
Long Phan, Hieu Tran, Daniel Le, Hieu Nguyen, James Annibal, Alec Peltekian, and Yanfang Ye. 2021. CoTexT: Multi-task learning with code-text transformer. In Proceedings of the 1st Workshop on Natural Language Processing for Programming (NLP4Prog 2021), pages 40–47, Online. Association for Computational Linguistics.
Maxim Rabinovich, Mitchell Stern, and Dan Klein. 2017. Abstract syntax networks for code generation and semantic parsing. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1139–1149, Vancouver, Canada. Association for Computational Linguistics.
Alec Radford and Karthik Narasimhan. 2018. Improving language understanding by generative pretraining.
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, YanqiZhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, M. Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of code synthesis. ArXiv, abs/2009.10297.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is allyou need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
Xiaojun Xu, Chang Liu, and Dawn Song. 2017. Sqlnet: Generating structured queries from natural language without reinforcement learning.
Pengcheng Yin, Bowen Deng, Edgar Chen, Bogdan Vasilescu, and Graham Neubig. 2018. Learning to mine aligned code and natural language pairs from stack overflow. MSR ’18, page 476–486, New York, NY, USA. Association for Computing Machinery.
Pengcheng Yin and Graham Neubig. 2017. A syntactic neural model for general-purpose code generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 – August 4, Volume 1: Long Papers, pages 440–450. Association for Computational Linguistics.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter J. Liu. 2019. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2sql: Generating structured queries from natural language using reinforcement learning. ArXiv, abs/1709.00103.
Les auteurs : Jessica Lòpez Espejel, Mahaman Sanoussi Yahaya Alassan, Walid Dahhane, El Hassane Ettifouri
