Anonymisation des données sensibles par l’approche couplée du NLP et des modèles neuronaux
10/01/2023 , written by Sanoussi Alassan
10 Jan , 2023 read
L’exploitation des données est plus que jamais un enjeu majeur au sein de tout type d’organisation. Plusieurs cas d’usage sont traités, de l’exploration à l’extraction d’informations pertinentes et utilisables, afin de :
- Comprendre l’environnement d’une organisation
- Mieux connaître ses collaborateurs
- Améliorer ses services, produits et process (cas d’utilisation des données de la production dans un environnement de test et/ou développement)
Manipuler ces masses d’informations n’est pas sans conséquence. On y trouve des informations sensibles dont la divulgation peut porter préjudice à des personnes morales et/ou physiques. C’est pourquoi le Parlement européen a adopté en mai 2016, le Règlement Général sur la Protection des Données (RGPD) visant à encadrer le traitement des données de manière égalitaire sur tout le territoire de l’Union Européenne. Ses objectifs : renforcer les droits des personnes, responsabiliser les acteurs traitant des données et favoriser la coopération entre les autorités de protection des données. La pseudonymisation/anonymisation apparaît ainsi comme une technique indispensable en matière de protection des données personnelles et favorisant la conformité avec la réglementation.
Qu’est-ce que la Pseudonymisation et l’Anonymisation ?
L’ENISA [1] (agence de l’Union Européenne pour la cybersécurité) définit la pseudonymisation comme étant un processus de dés identification. C’est un traitement de données sensibles réalisé de manière à ce que l’on ne puisse plus identifier une personne physique de manière directe sans avoir recours à des informations supplémentaires. Alors que l’anonymisation est un processus par lequel les données à caractère personnel sont modifiées de façon irréversible de telle façon que la personne concernée ne puisse plus être identifiée, directement ou indirectement, que ce soit par le responsable du traitement seul ou en collaboration avec d’autres tiers [1].
Lorsque l’on considère le texte suivant : « Emmanuel MACRON est le huitième Président de la Vème République française. Fondateur du mouvement « En Marche ! », créé le 6 avril 2016, il l’a dirigé jusqu’à sa première victoire à l’élection présidentielle, le 7 mai 2017. ».
On distingue trois types d’informations :
- les entités nommées : Emmanuel MACRON, 6 avril 2016, 7 mai 2017, En Marche, huitième
- Les mentions : Président de la Vème République française, Fondateur
- Autres morphèmes identifiants : première victoire, l’élection présidentielle
Le tableau suivant résume le résultat attendu lorsque l’on applique ces deux techniques
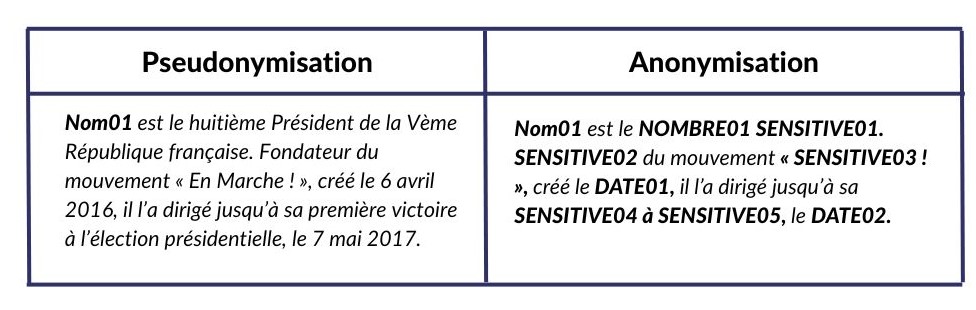
Une troisième catégorie d’approche de traitement de données sensibles se dégage avec les avancées des algorithmes neuronaux sur l’exploitation du langage naturel : la pseudonymisation avancée. Cette dernière est capable de traiter une grande majorité des informations sensibles « identifiants » dans un texte. Il reste cependant des cas à la marge qui peuvent être détectés si le contexte du sujet traités est connu. C’est l’exemple du texte suivant « LinkedIn est un réseau social. En France, en 2022, LinkedIn compte plus de 25 millions de membres et 12 millions de membres actifs mensuels estimés, ce qui en fait le 6ème réseau social. » où lorsque le terme 6ème réseau social, difficilement détectable peut permettre d’identifier LinkedIn lorsque l’on fait quelques recherches sur internet.
Qu’entend-on par « données sensibles » ?
Les données sensibles sont des informations permettant d’identifier une personne physique ou morale. C’est le cas des informations suivantes lorsqu’elles sont associées à une personne physique : nom complet (nom et prénom), lieux, organisation, date de naissance, adresses (email, logement), des numéros identifiants (carte bancaire, sécurité sociale, téléphone) …. ou des informations liées à une personne morale comme, le nom de l’entreprise, son adresse, ses identifiants SIREN et SIRET, ….
Comment pseudonymiser les données ?
La CNIL [2] décrit deux types de techniques de pseudonymisation : celles qui reposent sur la création de pseudonymes relativement basiques (compteur, générateur de nombre aléatoire) et celles qui s’appuient sur les techniques cryptographiques (chiffrement à clé secrète, fonction de hachage).
Toutes ces méthodes expliquent comment les données sensibles doivent être traitées dans le cadre de la pseudonymisation. Elle n’explique pas comment les identifier. Le processus d’identification peut être simple lorsque les données sont tabulaires. Il suffit alors de supprimer ou de chiffrer le contenu des colonnes concernées.
Chez Novelis, nous travaillons sur la pseudonymisation avancée des données sensibles contenues dans des textes libres. L’identification dans ce contexte est complexe et est souvent réalisée manuellement par des humains, ce qui impose un coût en temps et en ressources humaines qualifiées. L’intelligence Artificielle (IA) et les techniques du traitement automatique du langage (NLP) sont pourtant suffisamment robustes pour automatiser cette tâche . On distinguera ainsi généralement deux types d’approches d’extraction de données sensibles : les approches neuronales et les approches basées sur des règles. Bien qu’elles fournissent d’excellents résultats, surtout avec l’apparition des Transformers (modèle d’apprentissage profond), les approches neuronales nécessitent des jeux de données importants pour être pertinentes, ce qui n’est pas toujours le cas dans le monde industriel. Elles nécessitent par ailleurs une tâche d’annotation par des experts afin de fournir aux modèles un jeu de données de qualité pour l’entraînement. Quant aux modèles basés sur des règles, ils souffrent de problèmes de généralisation. Un modèle basé sur des règles aura en effet tendance à avoir une bonne précision sur l’échantillon servant de base d’apprentissage mais sera plus difficilement applicable à un nouveau jeu de données non étudié dans les hypothèses de départ
L’approche proposée par l’équipe R&D du laboratoire Novelis
Nous proposons une approche hybride exploitant les points fort des techniques NLP et des modèles neuronaux. Tout d’abord nous avons construit un corpus contenant des adresses, pour entraîner un modèle neuronal capable de détecter une adresse dans un texte. Un benchmarking des modèles a été effectué afin de choisir le modèle adéquat. Le modèle est ensuite amélioré grâce à une stratégie de « fine-tuning ». Combiné à des librairies python NLP, le modèle offre une solution robuste d’extraction des adresses et des entités nommées telles que les noms des personnes, les lieux et les organisations. Des motifs (expressions régulières) ont été désignés, par les experts Novelis, pour l’extraction des autres données sensibles identifiés. Enfin, des heuristiques ont été utilisées pour désambiguïser et corriger les informations extraites.
Par cette approche, nous avons construit un système fiable et robuste permettant de traiter les informations sensibles contenues dans tout type de documents (pdf, word, email, …). Le but étant de supprimer les tâches à faible valeur ajouté des responsables du traitement des données par de l’assistance automatisée.
Références :
- [1] : https://www.enisa.europa.eu/news/enisa-news/enisa-proposes-best-practices-and-techniques-for-pseudonymisation
- [2] : https://www.cnil.fr/fr/recherche-scientifique-hors-sante/enjeux-avantages-anonymisation-pseudonymisation
