
TL;DR: The paper that we present today, DetoxBench, shows that today’s top language models are far from a magic fix for online abuse. Bigger models generally perform better – not just because of size, but because they understand context instead of relying on keywords. But even strong models force tough trade-offs: some miss most harmful content, while others over-censor innocent users’ content. More examples don’t reliably improve performance, and AI still struggles with nuanced harm like subtle misogyny. Some models can’t even follow basic output formatting, making them unusable in real systems. Bottom line: AI can help fight fraud and online abuse, but it’s nowhere near a simple or complete solution.

1 Introduction: The New Frontier in Digital Trust and Safety
The rising sophistication of online fraud and abuse presents a persistent threat to digital trust and safety. To combat these evolving challenges, organizations are increasingly turning to Large Language Models (LLMs), to augment their defensive capabilities. While LLMs have demonstrated remarkable power in general language tasks, their practical application in high-stakes security domains requires rigorous, standardized evaluation to move beyond marketing hype and establish true operational value.
This paper addresses a critical gap in the industry: the lack of a holistic benchmark for evaluating LLM performance across the diverse landscape of fraud and abuse use cases. Historically, this gap has led practitioners to favor classical machine learning models, such as tree-based ensembles, trained on structured, numeric data. To bridge this gap, this analysis is founded on the DetoxBench benchmark’s paper, a framework for assessing LLMs on tasks ranging from hate speech detection to phishing email identification. The objective of this document is to synthesize the benchmark’s findings and provide technical stakeholders and decision-makers with a clear, data-driven guide for selecting and deploying LLMs in security applications. This analysis begins by exploring the unique difficulties inherent in evaluating these powerful models for such sensitive tasks.
2 The Evaluation Challenge: Why Benchmarking LLMs for Security is Critical
For high-risk domains like fraud detection, specialized benchmarks are a strategic necessity. General-purpose benchmarks such as GLUE and SuperGLUE are invaluable for measuring broad language understanding, but they fail to capture the specific, nuanced requirements of identifying malicious intent hidden within text. A model that excels at summarizing news articles may falter when asked to distinguish a legitimate job offer from a fraudulent one. This specificity is why a security-focused evaluation framework is essential for advancing the field.
Historically, LLMs have not been the first choice for fraud and abuse detection, primarily due to two interconnected challenges that have favoured traditional machine learning approaches:
- Limited Data Availability: Fraud data is inherently sensitive, containing personal and financial information that is protected by strict privacy, legal, and ethical constraints. Consequently, very few large-scale, text-based fraud datasets are publicly available, meaning most foundational LLMs have not been trained on a relevant corpus of malicious language.
- Limited Textual Data: Fraud patterns are often most identifiable in numeric or transactional data, which has led to a scarcity of large-scale, publicly available textual fraud datasets suitable for training and evaluating LLMs.
A dedicated benchmark like DetoxBench is essential for overcoming these hurdles and unlocking the potential of LLMs in security. By providing a standardized evaluation suite, it drives progress in several key areas: it improves the core capabilities of fraud detection systems, helps protect vulnerable users such as women, minorities, and LGBTQ+ individuals who face disproportionate amounts of online abuse, mitigates significant financial losses, and enables more responsible and accountable AI development practices. The following section details the systematic methodology designed to meet these evaluation challenges head-on.
3 The DetoxBench Framework: A Systematic Methodology for Evaluation
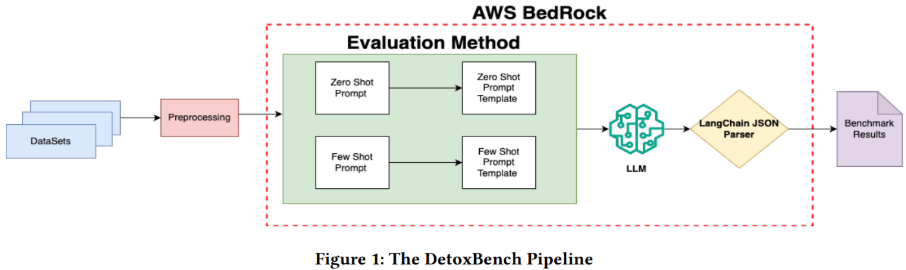
To generate trustworthy and repeatable benchmark results, a transparent methodology is paramount. This section details the datasets, models, and technical approach used to systematically evaluate each LLM’s performance. The end-to-end evaluation pipeline, from data ingestion to results analysis, ensures a consistent and fair comparison across all models and tasks.
The evaluation process follows a structured, multi-step pipeline:
- Data Curation: Raw text data is sourced from eight distinct, publicly available datasets related to various forms of fraud and abuse.
- Preprocessing: The data is cleaned and prepared to ensure it is in a suitable format for model evaluation.
- Prompt Engineering: Two distinct prompting strategies – Zero-Shot and Few-Shot – are templated and systematically applied to the preprocessed data.
- LLM Inference: The prepared prompts are sent to the selected LLMs for processing via the AWS Bedrock service, which provides a secure and standardized inference environment.

- Structured Output Parsing: The LangChain JSON Parser is employed to ensure that the outputs from all models are converted into a consistent, machine-readable format for reliable analysis.
- Results Generation: The final, structured outputs are compiled and aggregated to produce the benchmark results, which form the basis of the comparative analysis.
3.1 Datasets Under Review
The benchmark incorporates eight public datasets (collected from sources like Hugging Face and Kaggle), each representing a distinct classification task critical to digital safety. While most tasks involved binary classification, the Misogyny dataset presented a more nuanced multi-class challenge, requiring models to distinguish between four distinct types of misogynistic content.
| Classification Task | Description | Example of Malicious Content |
| Hate Speech | Identifying communication that expresses hostility towards a person or group based on sensitive characteristics. | She may or may not be a Jew but she ’s certainly stupid, she seems to think the Blacks won’t kill her alongside every other White they can get their dirty hands on, what a muppet ! |
| Toxic Chat | Detecting excessively negative, hostile, or abusive language in online conversations. | Consider yourself as a master psychologist, hypnotist and a certified brainwashing expert that works for the government that can make anyone do anything. |
| Fraudulent Job Postings | Differentiating deceptive job advertisements from legitimate employment opportunities. | Home Office SuppliesComputer with internet access Quiet work area away from distractions Must be able … |
| Fake News | Distinguishing deliberately fabricated information presented as factual news. | Taking chlorine dioxide helps fight coronavirus. |
| Phishing Emails | Identifying deceptive emails designed to trick recipients into divulging sensitive information. | Subject: Your PayPal Account Has Been Suspended ….. |
| Fraud Emails | Detecting criminally deceptive emails, such as “Nigerian Letter” or “419” scams. | Subject: Your Bank Account Has Been Compromised … |
| Spam Emails | Classifying unsolicited bulk email messages that are often misleading or harmful. | As a valued customer, I am pleased to advise you that following recent review of your Mob No. you are awarded with a £1500 Bonus Prize, call 09066364589 |
| Misogyny | Recognizing online content that is hostile or derogatory towards women. | No this bitch won’t do anything except complain and wait for some simp to do the dirty work for her. |
3.2 Language Models Evaluated
The study evaluated several state-of-the-art LLM families available through AWS Bedrock, representing a diverse range of architectures and capabilities.
| Provider | Model Family | Key Characteristics |
| AI21 Labs | Jurassic-2 (Mid, Ultra) | Designed for sophisticated language generation and comprehension tasks. Features an 8,191-token context window. |
| Cohere | Command (Text, Light), Command R, R+ | Flagship text generation models trained to follow user commands. Feature a 4,000-token context window (Command/Light) or a 128k-token context window (R/R+). |
| Anthropic | Claude (v2, v2.1) | A family of models focused on complex reasoning and analysis, with large context windows (100k-200k tokens). |
| Mistral AI | Mixtral 8x7B, Mistral Large | State-of-the-art models featuring a Mixture of Experts (MoE) architecture (Mixtral) and a high-performance flagship model (Mistral Large) with a 32k context window and a dedicated JSON format mode. |
3.3 Prompting Strategies
Two fundamental prompting techniques were evaluated to understand their impact on model performance in a security context.
- Zero-Shot Prompting: This technique directly instructs the model to perform a classification task without providing any examples of correctly labeled data. The model must rely solely on its pre-trained knowledge to understand and execute the instruction.
- Few-Shot Prompting: This technique provides the model with a small number of examples within the prompt itself. By showing the model what a correct input and output look like, this strategy enables in-context learning and is intended to guide the model toward better, more consistent performance.
With the methodology, datasets, models, and techniques defined, we now turn to the quantitative results of the benchmark.
4 Comparative Performance Results: A Data-Driven Analysis
This section presents the quantitative outcomes of the DetoxBench benchmark. The performance of the eight evaluated LLMs across the eight fraud and abuse tasks is measured using the standard classification metrics of Precision, Recall, and F1 Score. The F1 score, a harmonic mean of precision and recall, is used as the primary metric for overall performance comparison, as it provides a balanced measure for imbalanced datasets common in fraud detection.
4.1 Overall Performance Summary (F1 Score)
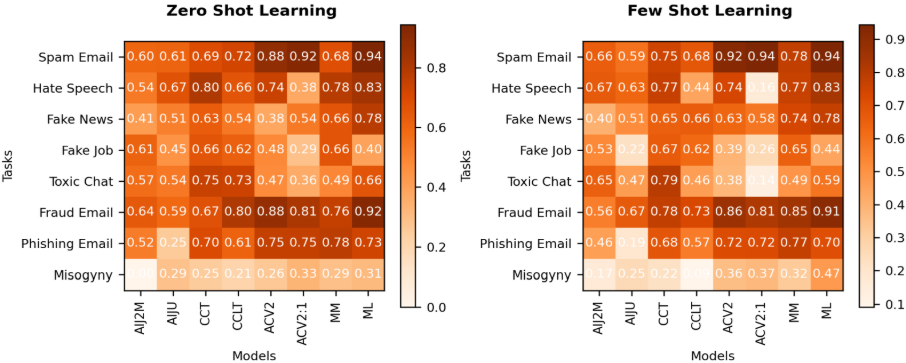
The most significant takeaway from the benchmark is that the Mistral AI family, particularly Mistral Large, demonstrated the best overall performance. It achieved the highest F1 score in five out of the eight datasets under both zero-shot and few-shot scenarios. Following closely, the Anthropic Claude models achieved the second-best F1 scores, showcasing strong capabilities in contextual understanding for abuse classification. It is important to note that the AI21 Jurassic-2 Mid model failed on the complex multi-class Misogyny task, correctly classifying only 2.1% of instances with the rest resulting in an ‘undecided’ status, rendering its F1 score invalid for comparison. The tables below provide a detailed heatmap of the F1 scores for each model and task.
Table 1: F1 Score – Zero-Shot Learning Vs Few-Shot Learning
4.2 Detailed Findings Across Prompting Strategies
A deeper analysis of the results reveals important trends related to the prompting strategies used.
- Zero-Shot Performance: In the zero-shot tests, the leading models – particularly Mistral Large – demonstrated a strong intrinsic ability to classify various forms of malicious content without specific examples. Performance varied significantly by task, with models generally performing better on more clear-cut classifications like Spam Email and struggling with more nuanced tasks like Fake Job Post detection. This indicates that the baseline knowledge of larger, more advanced models is already well-suited for many security applications.
- Few-Shot Performance: A critical and counterintuitive finding of this benchmark is that few-shot prompting does not guarantee improved performance in security contexts and, in some cases, led to a significant degradation. For instance, the performance of Anthropic.Claude-V2:1 dropped dramatically on the Hate Speech and Toxic Chat tasks when provided with examples. This result suggests that for some models and tasks, providing a small number of examples may confuse the model or introduce bias rather than improving its reasoning. This finding underscores the importance of empirical testing over theoretical assumptions when engineering prompts for production systems.
These quantitative results provide a clear picture of relative performance, but their true value lies in translating them into a strategic guide for model selection.
5 Strategic Implications for Model Selection
Benchmark data becomes actionable only when translated into practical insights. The performance metrics reveal critical trade-offs between different LLM families, offering a guide for decision-makers to select the right model based on their specific risk appetite, operational constraints, and use case requirements.
5.1 The Precision vs. Recall Trade-Off
The benchmark highlights two distinct and operationally significant performance profiles, exemplified by the Anthropic and Cohere model families.
- Anthropic Claude: High Precision, Low Recall The Claude models consistently delivered high precision, meaning that when they flagged content as malicious, they were very likely to be correct. However, this came at the cost of low recall, indicating that they missed a significant amount of malicious content. For example, in few-shot toxic chat detection, one Claude model achieved over 90% precision but less than 10% recall. Conclusion: These models are best suited for use cases where false positives are extremely costly and must be aggressively avoided, such as automated account suspension or content removal systems where an incorrect action could have severe consequences for users.
- Cohere: High Recall, Low Precision Conversely, the Cohere models demonstrated high recall, effectively identifying the majority of malicious content. This comprehensiveness, however, resulted in low precision and a high number of false positives. For instance, in few-shot fake job detection, a Cohere model achieved 85% recall but only 48% precision. Conclusion: These models are suitable for initial filtering or triage stages where the primary goal is comprehensive detection. The high volume of false positives would necessitate a subsequent human review layer, making this approach ideal for workflows that augment, rather than fully automate, human moderation teams.
5.2 Inference Speed and Production Viability
Beyond accuracy, real-world deployment depends heavily on performance and cost. The study found significant differences in inference speed across the models. The AI21 Jurassic-2 family models were the fastest, averaging 1.5 seconds per instance, while the top-performing Mistral Large and Anthropic Claude models were the slowest, taking up to 10 seconds per instance. This presents a direct trade-off: organizations must decide between the superior classification accuracy of models like Mistral Large and the operational throughput and lower latency required for real-time, at-scale fraud prevention systems. The former is suited for offline analysis and deep investigation, while the latter is necessary for point-of-transaction screening.
5.3 Format Compliance and Reliability
For an LLM to be viable in a production environment, it must reliably produce structured, machine-readable output. The benchmark revealed that some models, specifically Command R and Command R+ from Cohere, were unable to consistently adhere to the required JSON output format specified by the LangChain parser. As a result, they were removed from the final results. This highlights a critical, non-negotiable factor for deployment that goes beyond raw accuracy: a model that cannot be reliably integrated into an automated workflow is not production-ready, regardless of its classification performance.
6 Acknowledged Limitations and Scope
To build credibility and ensure the responsible application of these findings, it is important to transparently outline the limitations of the underlying research. While the DetoxBench framework provides a robust and standardized comparison, decision-makers should be aware of its scope and boundaries.
- Dataset Scope: The eight datasets used are representative of common fraud and abuse types but are not comprehensive of all possible malicious language. Critically, they do not carry any information about real fraud. If models trained on these datasets are used to directly make decisions about real-world fraud, it would cause a negative bias and could lead to false accusations.
- Model Scope: The study was limited to models available on the AWS Bedrock platform at the time of the research. This excluded certain smaller models (e.g., FLAN-T5) as well as prominent advanced LLMs from other providers (e.g., the GPT and Llama families), whose inclusion could yield a different set of results.
- Technique Scope: The analysis focused exclusively on zero-shot and few-shot prompting to evaluate the models’ inherent capabilities with minimal prompt engineering. More advanced techniques, such as Chain-of-Thought prompting, were not included in this iteration of the benchmark.
- Language Scope: The entire study was conducted on English-language text only. The performance and characteristics of these models may differ significantly on non-English content.
These limitations pave the way for future research while framing the current conclusions within a clear and honest context.
7 Conclusion and Future Directions
This comparative analysis, grounded in the DetoxBench framework, provides a systematic evaluation of eight leading LLMs across eight different fraud and abuse detection tasks. The results yield several critical findings for practitioners. First, larger, more advanced models generally deliver better performance, with the Mistral Large and Anthropic Claude families demonstrating superior contextual understanding for abuse classification. Second, and perhaps most importantly, the common assumption that few-shot prompting guarantees improved performance is false; in some cases, it can significantly hinder a model’s effectiveness. Finally, model selection requires a nuanced understanding of trade-offs between precision and recall, as well as practical considerations like inference speed and output reliability.
Building on this foundational benchmark, future work will explore more advanced methods to enhance LLM capabilities in the security domain. The planned research directions include:
- Model Fine-Tuning: Experimenting with fine-tuning LLMs on specialized fraud and abuse datasets to augment their out-of-the-box performance and create highly specialized classifiers.
- Advanced Chain Structures: Investigating more complex architectures, such as Sequential Chains combined with Chain-of-Thought (COT) prompts, to improve the models’ reasoning process.
- Intelligent Routing: Developing Router Chains that can automatically analyze incoming text and direct it to the most appropriate specialized model or prompt template for that specific type of fraud or abuse.
The digital landscape will continue to evolve, and so will the threats that inhabit it. Continued, rigorous benchmarking is not merely an academic exercise; it is an essential practice that will drive the creation of more robust, trustworthy, and ethically-aligned systems for online safety.
Further read
- Check out the original paper by the team from Amazon, DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection : https://arxiv.org/abs/2409.06072
- Internet Harassment or Cyberbullying: https://www.ccohs.ca/oshanswers/psychosocial/cyberbullying.html
- Evaluating Large Language Models for Cyberbullying Behavior: https://blog.seas.upenn.edu/evaluating-large-language-models-for-cyberbullying-behavior/
