In the fast-evolving field of multimodal AI, Video Large Language Models (VLLMs) are emerging as a powerful tool for understanding and reasoning over dynamic visual content.

These systems, built atop the fusion of vision encoders and large language models, are capable of performing complex tasks like video question answering, long video comprehension, and multi-modal reasoning.
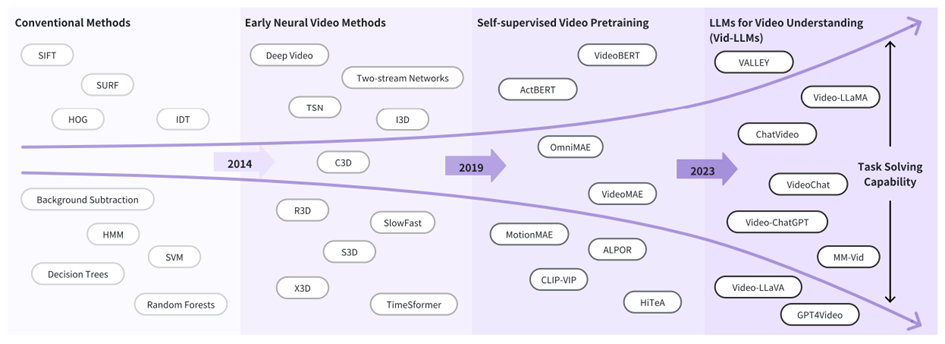
Yet, one fundamental bottleneck persists: token overload. Videos, even short ones, can easily generate tens of thousands of visual tokens. Each frame contributes its own set, and when encoded sequentially, the model is forced to process an enormous input, resulting in high memory costs, slow inference, and poor scalability. The redundancy across and within frames compounds the problem, as many tokens represent overlapping or repeated content.
This is the problem that LLaVA-Scissor was designed to solve.
Rethinking token compression: Beyond attention maps
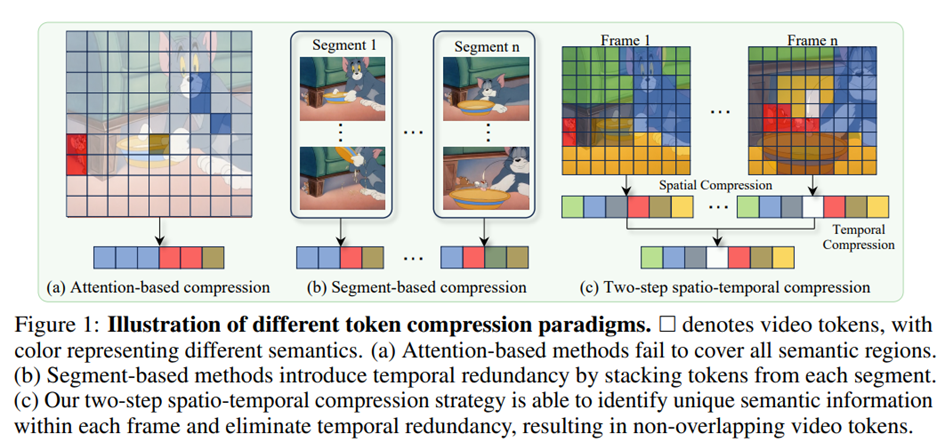
Traditional approaches to token compression in vision-language models often rely on attention scores to select which tokens to keep. While intuitive, these strategies tend to emphasize salient objects and overlook important background or contextual cues. Worse, they frequently select the same dominant features across multiple frames, leading to semantic repetition rather than reduction.
Other methods attempt to reduce tokens through architectural tricks, like trainable pooling modules, scene segmentation, or cross-frame interpolation, but these typically require additional training, suffer from limited generalization, and often struggle to align temporally inconsistent content.
LLaVA-Scissor breaks from this mold. It introduces a training-free, inference-time compression algorithm that identifies semantically unique token groups and efficiently reduces redundancy, without sacrificing understanding.
Semantic connected components: A graph-based approach
At the heart of LLaVA-Scissor lies a simple but elegant idea: treat tokens as a graph, and reduce them by identifying connected components based on semantic similarity.
Here’s how it works.
Each token is represented as a high-dimensional vector (from the visual encoder). LLaVA-Scissor computes pairwise similarities between all tokens in a frame (or across frames), and constructs a binary adjacency matrix based on a similarity threshold τ. Tokens that are sufficiently similar are considered connected.
This process transforms the token compression problem into a graph clustering problem. By using an efficient union-find algorithm, the model extracts connected components, clusters of semantically similar tokens. Each cluster is then compressed into a single representative token, computed as the average of all tokens in the component.
Crucially, no assumptions are made about spatial or temporal adjacency. This allows the system to identify semantic similarity between tokens even if they originate from different frames or spatial locations. The result is a set of representative tokens that preserves the diversity of semantic content without duplicating information.
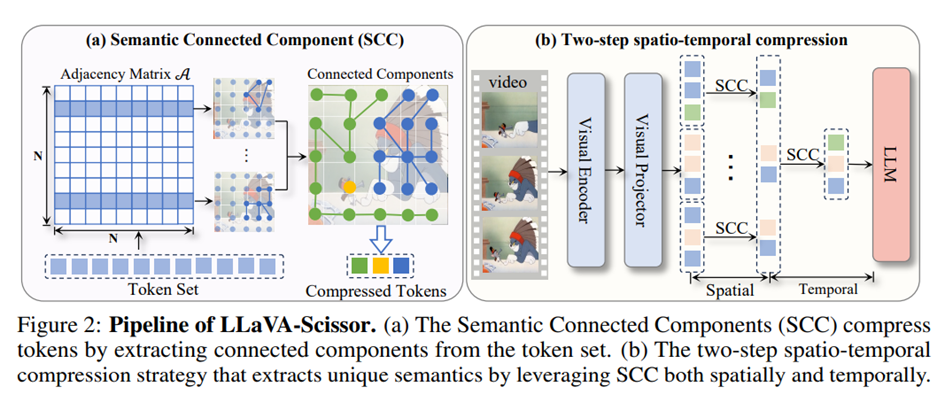
A two-stage strategy: Spatial and temporal compression
Video understanding requires more than just compressing tokens within a frame. Temporal redundancy, caused by repeating actions or static backgrounds across frames, is just as problematic.
LLaVA-Scissor tackles this with a two-step compression pipeline:
- Spatial Compression: Within each frame, SCC is applied to identify and merge semantically similar regions. This yields a smaller set of spatially representative tokens for each frame.
- Temporal Compression: These representative tokens are then concatenated across all frames. SCC is applied again, this time across the entire video sequence, to remove temporal redundancy.
This hierarchical compression ensures that redundant visual concepts are eliminated across both space and time, resulting in a final token set that is compact, expressive, and non-redundant.
A final merging step optionally re-aligns the original token set with the compressed set, improving fidelity. Here, each original token is assigned to its most similar representative, and averaged in. This “merge-back” improves performance, especially at low token budgets.
Experimental results: Less tokens, more performance
LLaVA-Scissor was evaluated across several major benchmarks, including:
- Video QA: ActivityNet-QA, Video-ChatGPT, Next-QA
- Long Video Understanding: EgoSchema, MLVU, VideoMME, VideoMMMU
- Multi-choice Reasoning: MVBench
To ensure a strong baseline, LLaVA-Scissor leverages an enhanced version of the LLaVA-OneVision architecture. The original LLaVA-OneVision combined CLIP as the visual encoder with Qwen 2 as the language model.
For LLaVA-Scissor, the authors upgraded this base by replacing CLIP with SIGLIP and using Qwen 2.5 as the LLM, and retrain an enhanced version of the LLaVA-OneVision model using open-sourced Oryx data. They’ve also tested on a smaller variant, LLaVA-OneVision-0.5B, which similarly used SIGLIP and Qwen-2.5-0.5B, to check for robustness even at reduced scales.
The results are very interesting. On video QA tasks, LLaVA-Scissor matched or exceeded other methods at 50% token retention. But its true strength emerged as the retention ratio dropped. At 10% retention, it scored an average 80.03%, outperforming FastV (78.76%), PLLaVA (77.87%), and VisionZip (65.09%). Even at just 5%, performance remained robust.
On long video benchmarks, where compressing across time is critical, LLaVA-Scissor continued to lead. At a 5% retention ratio, it outperformed all baselines, achieving 92.6% average accuracy compared to FastV’s 91.5% and PLLaVA’s 90.4% at 10%.
On MVBench, which includes 20 diverse multi-modal tasks, LLaVA-Scissor reached the highest average scores at both 35% and 10% retention, proving its versatility.
Efficient and scalable: FLOPs reduction and deployment potential
Perhaps the most compelling aspect of LLaVA-Scissor is its efficiency.
Unlike methods that compress tokens during the LLM stage (like FastV), LLaVA-Scissor performs compression before the tokens reach the language model. This drastically reduces FLOPs.

At 10% retention, LLaVA-Scissor reduced LLM-stage FLOPs to just 9.66% of the full model, while maintaining over 96% of performance. At 5%, it still delivered strong results with only 5.56% of FLOPs.
This makes LLaVA-Scissor an ideal candidate for:
- Real-time video applications
- On-device inference
- Mobile or edge AI scenarios
Its training-free nature also makes it plug-and-play: it can be integrated into any transformer-based vision-language pipeline without retraining or task-specific tuning.
What makes it work: Insights from ablation studies
Ablation studies confirm that each component contributes to LLaVA-Scissor’s success:
- Without temporal compression, performance drops by over 1 point on MVBench.
- Without merging, token coverage becomes too sparse.
- Sampling strategies like L2Norm or uniform selection perform worse than SCC, which preserves semantic coverage more faithfully.
Furthermore, the method remains robust even on smaller base models, such as LLaVA-OneVision-0.5B, where redundancy is harder to recover. This robustness underscores its generality and applicability across different compute regimes.
Final thoughts
LLaVA-Scissor isn’t a radical departure from the token compression literature, but it is refreshingly simple, elegant, and surprisingly effective.
Instead of tuning attention weights or introducing new training regimes, it reframes token compression as a semantic clustering problem. With a lightweight graph algorithm and no retraining required, it provides a practical solution to the token explosion problem that’s becoming increasingly pressing in video LLMs.
In a landscape where multimodal inputs are growing faster than compute budgets, we think methods like this (namely, fast, training-free, and effective) deserve serious attention.
Further Reading & Resources
Code Repository: GitHub – HumanMLLM/LLaVA-Scissor
- Explore the full implementation, including preprocessing scripts and evaluation pipelines: https://github.com/HumanMLLM/LLaVA-Scissor
Baseline Model: LLaVA-Scissor-baseline-7B on Hugging Face
- Try out the reference model directly via Hugging Face: https://huggingface.co/BBBBCHAN/LLaVA-Scissor-baseline-7B
Research Paper: LLaVA-Scissor: Training-Free Token Compression for Video LLMs (arXiv)
- Dive deeper into the technical details, methodology, and experimental results: https://arxiv.org/abs/2506.21862
Research Paper: Video Understanding with Large Language Models: A Survey
- A comprehensive guide to Video LLMs: https://arxiv.org/abs/2312.17432
