Oct 6 , 2025 read
In the ever-evolving world of artificial intelligence, the quest for models that seamlessly understand, generate, and manipulate visual and textual information has reached an milestone with Ovis-U1.
This model represents a remarkable leap in unified multimodal AI, striking a balance between compact efficiency and impressive performance. With only 3.6 billion parameters (2.4B devoted to understanding and 1.2B to generation), Ovis-U1 matches or surpasses the capabilities of much larger, task-specific models.

Its design demonstrates the power of carefully orchestrated unified training, bridging the gap between efficiency and high-level capability in a way that makes previous modular approaches seem almost quaint.
A Truly Unified Approach OpenCompass
At its core, Ovis-U1’s architecture is a tightly integrated 3-billion parameter engine that brings together three critical capabilities: multimodal understanding, text-to-image generation, and image editing. Unlike models designed for a single task, Ovis-U1 thrives on the interplay between these functions. Its understanding of visual content informs image generation, while the generative process in turn sharpens the model’s comprehension of complex visual-textual relationships. Inspired by GPT-4o’s ambition for unified intelligence, Ovis-U1 achieves comparable generation quality, all while maintaining a smaller, more computationally efficient architecture. This synergy between tasks is what sets Ovis-U1 apart, transforming it from a collection of specialized tools into a cohesive multimodal problem-solver.
Pushing the Limits of Multimodal Understanding
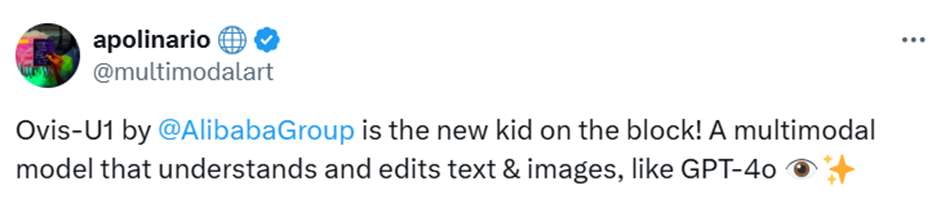
When evaluated on the OpenCompass Multi-modal Academic Benchmark, Ovis-U1 achieved an impressive 69.6, placing it at the top among models in the 3B-parameter range.

Even in comparison with larger models like GPT-4o, which scores 75.4, Ovis-U1 demonstrates remarkable comprehension for its size. Ablation studies highlight a crucial insight: integrating generation and editing tasks into the training process enhances understanding performance by 1.14 points, underscoring the powerful synergy of cross-task learning. In practice, this means the model doesn’t just see or describe an image: it interprets, contextualizes, and reasons about visual information with an agility previously reserved for far larger networks.
Capturing Imagination: Text-to-Image Generation

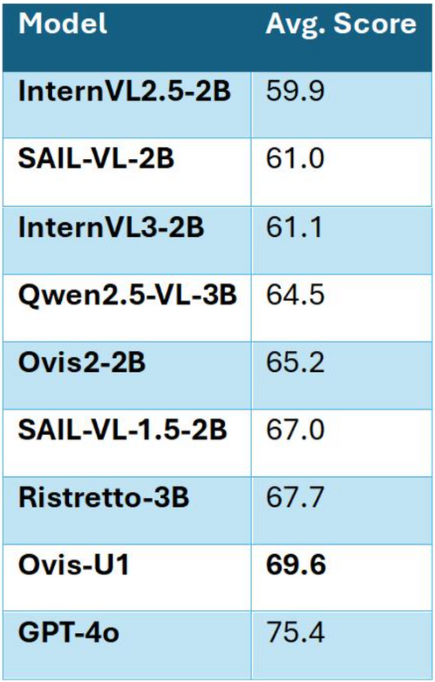
Ovis-U1’s prowess extends beyond understanding into the creative realm of text-to-image generation, where it achieves 83.72 on DPG-Bench and 0.89 on GenEval, surpassing even GPT-4o in certain nuanced tasks. Whether generating scenes with multiple objects, counting elements, or accurately placing objects in space, Ovis-U1 demonstrates a remarkable grasp of spatial and relational detail. This level of fidelity is enabled by its 1B-parameter visual decoder, based on the Multimodal Diffusion Transformer (MMDiT) with Rotary Positional Embedding (RoPE). A progressive training strategy further refines text embeddings, ensuring that every generated image faithfully captures the intent behind its prompt.
Redefining Image Editing
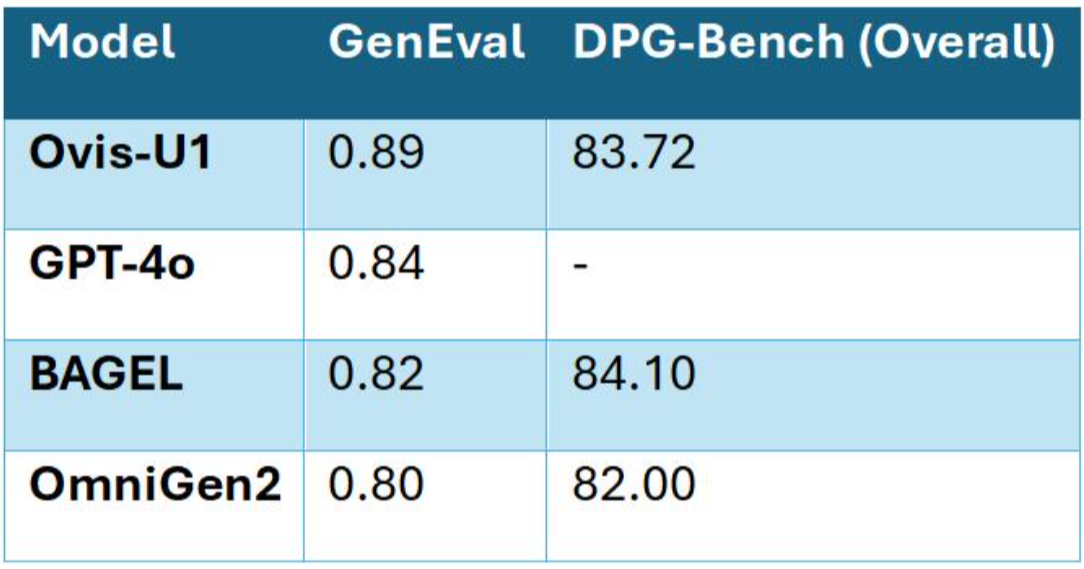
The model’s capabilities shine equally brightly in the realm of image editing, where Ovis-U1 scores strongly on both ImgEdit-Bench (4.00) and GEdit-Bench-EN (6.42).

Its bidirectional token refiner plays a pivotal role here, enhancing the dialogue between textual and visual embeddings. Tasks such as replacing objects, removing elements, and nuanced style adjustments are executed with precision, allowing a single model to perform operations that previously required multiple specialized systems. In practice, Ovis-U1 doesn’t just generate images: it collaborates with the user’s intent, seamlessly translating descriptions into tangible visual modifications.
Training on Diversity
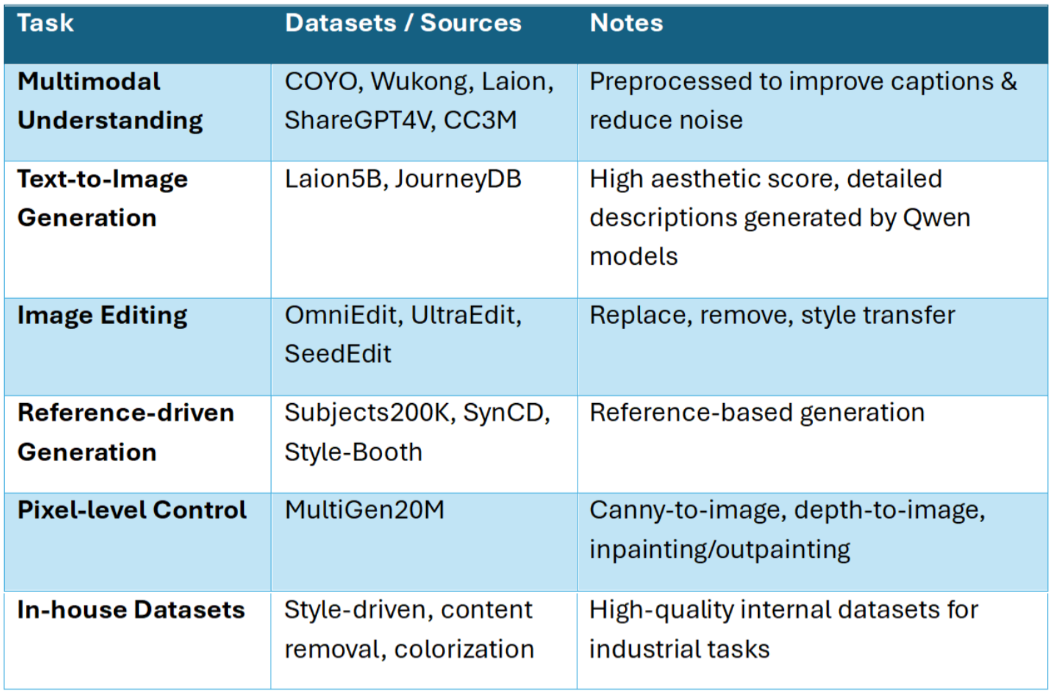
Ovis-U1’s strength owes much to the breadth and richness of its training data. Public datasets like COYO, Wukong, Laion, and ShareGPT4V are preprocessed for clarity, while large-scale text-to-image datasets like Laion5B and JourneyDB provide high-quality aesthetic guidance. The model also leverages specialized datasets for editing, reference-driven generation, and pixel-level control, as well as in-house datasets for style transfer, content removal, and image enhancement. Across six stages of unified training, these diverse sources converge, teaching the model to understand, generate, and edit in harmony.
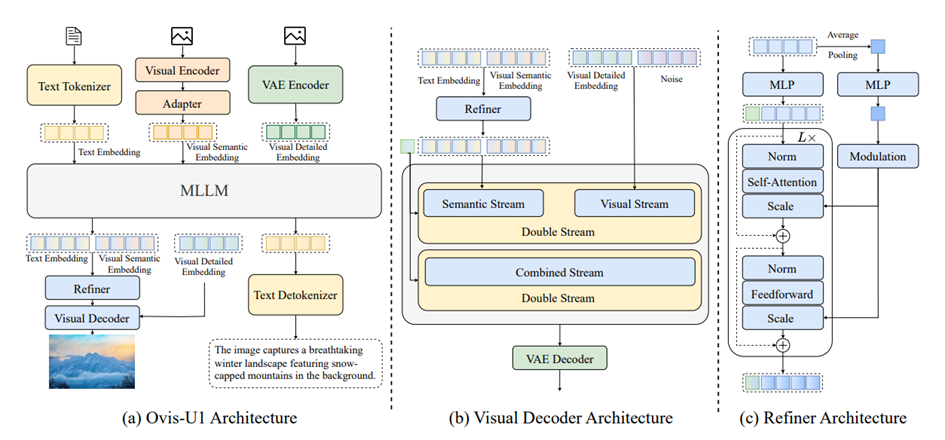
Architectural Innovations
Ovis-U1’s internal design reflects a careful balance of compactness and capability. Its visual decoder, bidirectional token refiner, and Qwen3-1.7B LLM backbone work in concert with a visual encoder adapted for arbitrary resolutions. The architecture allows for effective knowledge integration across modalities, ensuring that visual understanding and generative abilities reinforce one another. By treating visual and textual processing as intertwined rather than separate, Ovis-U1 achieves a level of cohesion rarely seen in models of its size.
A Six-Stage Training Symphony
The model’s performance is no accident.
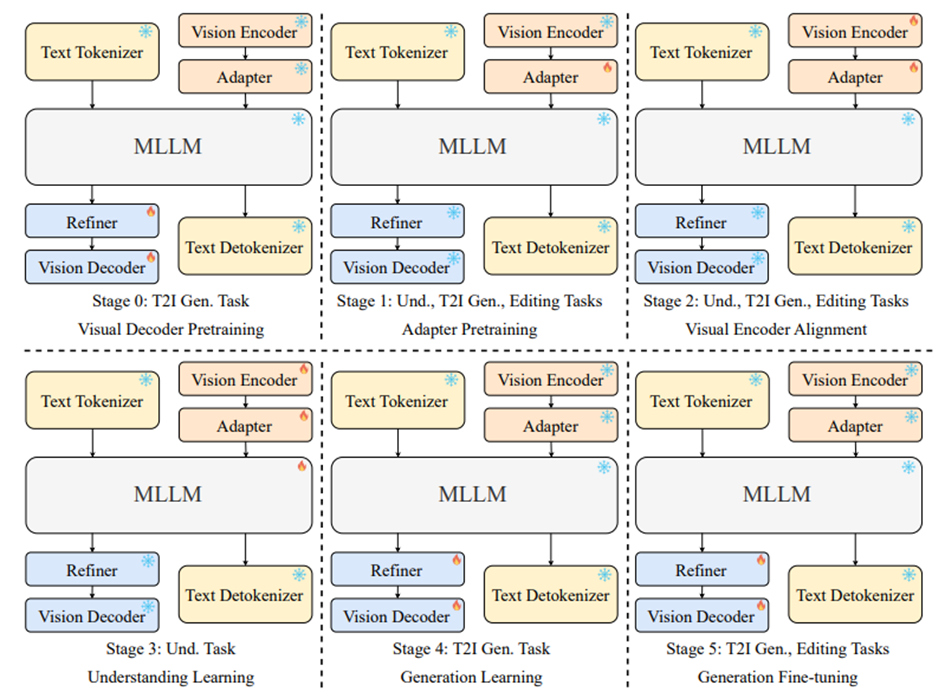
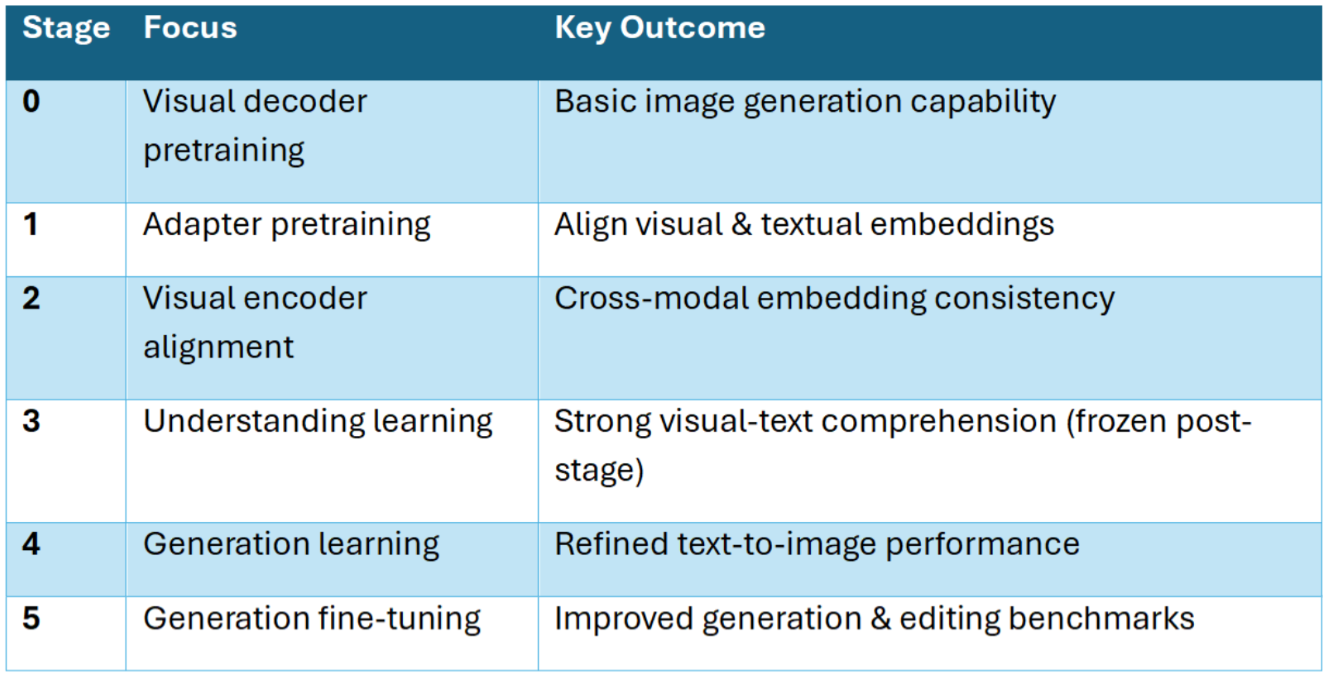
Its six-stage training pipeline methodically aligns understanding, generation, and editing: from initial visual decoder pretraining to adapter alignment, cross-modal embedding refinement, and staged learning in both comprehension and generation. The final stage, fine-tuning with image editing data, elevates both generation and editing capabilities. This structured progression is key to achieving seamless cross-task performance, allowing Ovis-U1 to operate like a single, unified brain rather than a patchwork of specialized systems.
Real-World Industrial Impact
In practical terms, Ovis-U1’s unified capabilities translate into tangible benefits for industry. By consolidating multiple specialized models into one, it simplifies workflows, enabling complex tasks (design iteration, multi-view synthesis, style transfer, and image editing) through natural language prompts. Its versatility extends to object detection, instance segmentation, depth estimation, and more, making it a valuable asset across manufacturing, design, marketing, robotics, and spatial computing. The model’s compact size also ensures computational efficiency, enhancing deployability without compromising performance.
Looking Ahead
The future for Ovis-U1 is bright. Scaling up the model promises higher-fidelity outputs, while the curation of richer, more diverse image-text datasets could further enhance its generalization. Architectural optimizations and reinforcement learning techniques may refine its understanding of human intent, yielding outputs that are not only accurate but also safer and more aligned with user expectations.
Conclusion
Ovis-U1 demonstrates that smaller, unified multimodal models can compete with, or even surpass, larger, task-specific systems. By blending innovative architecture, bidirectional refinement, diverse datasets, and careful staged training, it achieves state-of-the-art performance across understanding, generation, and editing. More than a technical achievement, Ovis-U1 offers a practical, scalable, and versatile solution poised to transform both industrial workflows and creative applications, marking a new chapter in the evolution of AI.
