Andrej Karpathy’s talk, “Software Is Changing (Again),” outlines how Large Language Models (LLMs) are revolutionizing how we build, interact with, and think about software. From the shift in programming paradigms to new opportunities in partial autonomy apps, Karpathy’s talk maps a path for developers, businesses, and technologists navigating this rapidly evolving landscape.

In this article, we’ll break down the key ideas from Karpathy’s talk: how software has evolved into its third major phase, why LLMs are best understood as complex operating systems, the opportunities they unlock for application development, and what it means to build for agents in this new world.
The Evolution of Software: From Traditional coding to Prompts
Software can be categorized into three paradigms:
Software 1.0: Traditional code written by humans (e.g., C++, Python, Java), where logic is explicitly programmed.
Software 2.0: Neural networks, where logic emerges from training data rather than hand-coded rules. This shift allowed companies to replace explicit code with machine-learned components.
Software 3.0: LLM-driven systems where prompts in natural language (English, French, Arabic, etc.) act as the code. Programming now means shaping the behavior of powerful language models with carefully crafted text inputs.
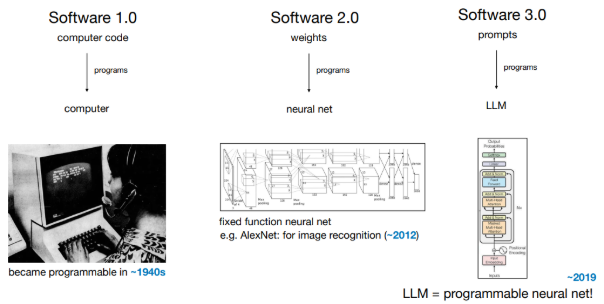
Developers must become fluent in all three paradigms, each offers unique strengths and trade-offs. For exemple, for a sentiment classification task, here how the three paradigm compare:

Large Language Models: The New Operating System
LLMs are best viewed as OS (operating systems) for intelligence:
Closed-source and open-source ecosystems resemble the early OS wars (Windows/macOS vs. Linux). Proprietary models like GPT and Gemini sit alongside open source ecosystems like LLaMA.
LLMs as CPUs: The model is the compute engine, while the context window is akin to memory, shaping problem-solving within strict resource limits.
1960s-style computing: LLM compute is expensive and centralized in the cloud, with users as thin clients. The future may eventually bring personal LLMs, but we’re not there yet.
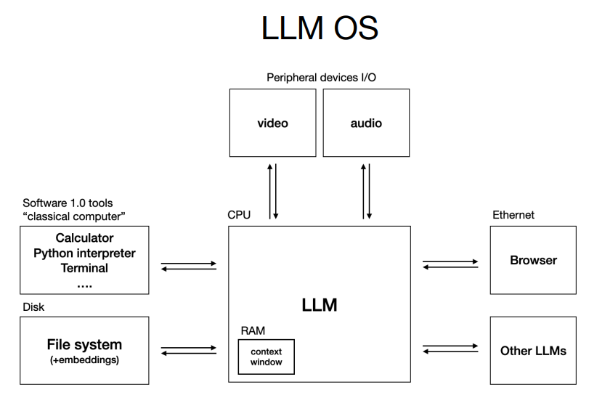
Interacting with an LLM today feels like using a terminal before the GUI era, powerful but raw. The “killer GUI” for LLMs has yet to be invented.

LLM Psychology: Superhuman, Yet Flawed
LLMs, he said, can be seen as stochastic simulations of people, capable of remarkable feats but prone to unique weaknesses:
Superpowers: They possess encyclopedic knowledge and near-infinite memory of their training data.
Cognitive deficits: LLMs hallucinate, lack persistent learning (anterograde amnesia), and sometimes make baffling errors (“jagged intelligence”).
Security limitations: Their openness to manipulation makes them vulnerable to prompt injections and data leaks.
The key to using LLMs effectively is building systems that leverage their strengths while mitigating their weaknesses, a human-in-the-loop approach.
The Opportunity: Building Partial Autonomy Apps
Direct interaction with LLMs will give way to dedicated applications that manage LLM behavior. For exemple, tools like Cursor (AI coding assistant) and Perplexity (LLM-powered search) orchestrate multiple models, manage context, and provide purpose-built GUIs. Apps should let users adjust the level of AI autonomy, from minor code suggestions to major repo changes. The most useful apps speed up the cycle of AI generation and human verification, using visual GUIs to audit AI output efficiently.
Karpathy warns against overly ambitious full autonomy. Instead, developers should focus on incremental, auditable steps.
Natural Language Programming & “Vibe Coding”
In the Software 3.0 world, everyone becomes a programmer:
Natural language as code: Since LLMs are programmed via prompts, anyone fluent in English can shape software behavior.
Vibe coding: Karpathy’s term for casually building useful apps without deep technical expertise, and a gateway to more serious software development.
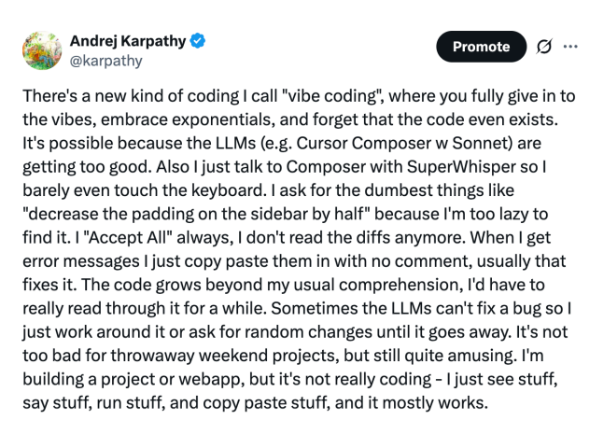
However, he highlights the gap: while LLMs make generating code easy, deploying real apps (auth, payments, deployment) is still manual, tedious, and ripe for automation.
Building for Agents: The Next Frontier
To truly harness AI agents, we need to adapt our digital infrastructure:
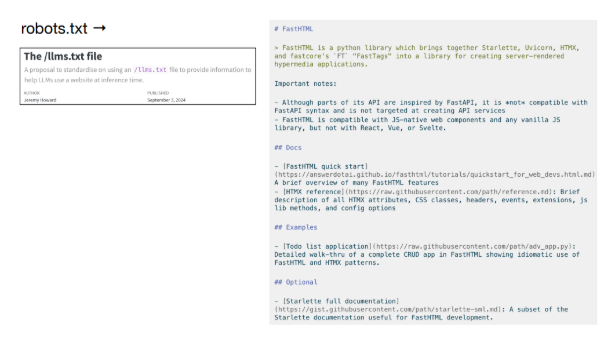
LLM-friendly web standards: Analogous to robots.txt, Karpathy proposes llms.txt files or markdown docs that speak directly to LLMs.
Structured data for agents: Move beyond human-centric docs (“click here”) to machine-readable instructions (curl commands, APIs).
Tools for LLM ingestion: Solutions like get-ingest and DeepWiki make large codebases consumable by LLMs, enabling smarter agent behavior.
The future will involve both improving agent capabilities and redesigning the digital world to make it more agent-friendly.
The Decade of Agents: What Comes Next
Karpathy concludes with a pragmatic vision: 2025 won’t be the year of agents, the 2020s will be the decade of agents.
Building partial autonomy systems with an “Iron Man suit” design, AI that augments humans while offering tunable autonomy, is the most promising path forward. Success will come not from chasing full autonomy today, but from carefully engineering human-AI cooperation at every step.
Conclusion
Software is changing, quickly and radically. With LLMs as the new programmable platform, the barriers to software creation are falling, but the complexity of verification, deployment, and safe autonomy is rising. Karpathy’s talk challenges us to build tools, infrastructure, and applications that respect this balance, putting human oversight at the heart of the AI revolution.
