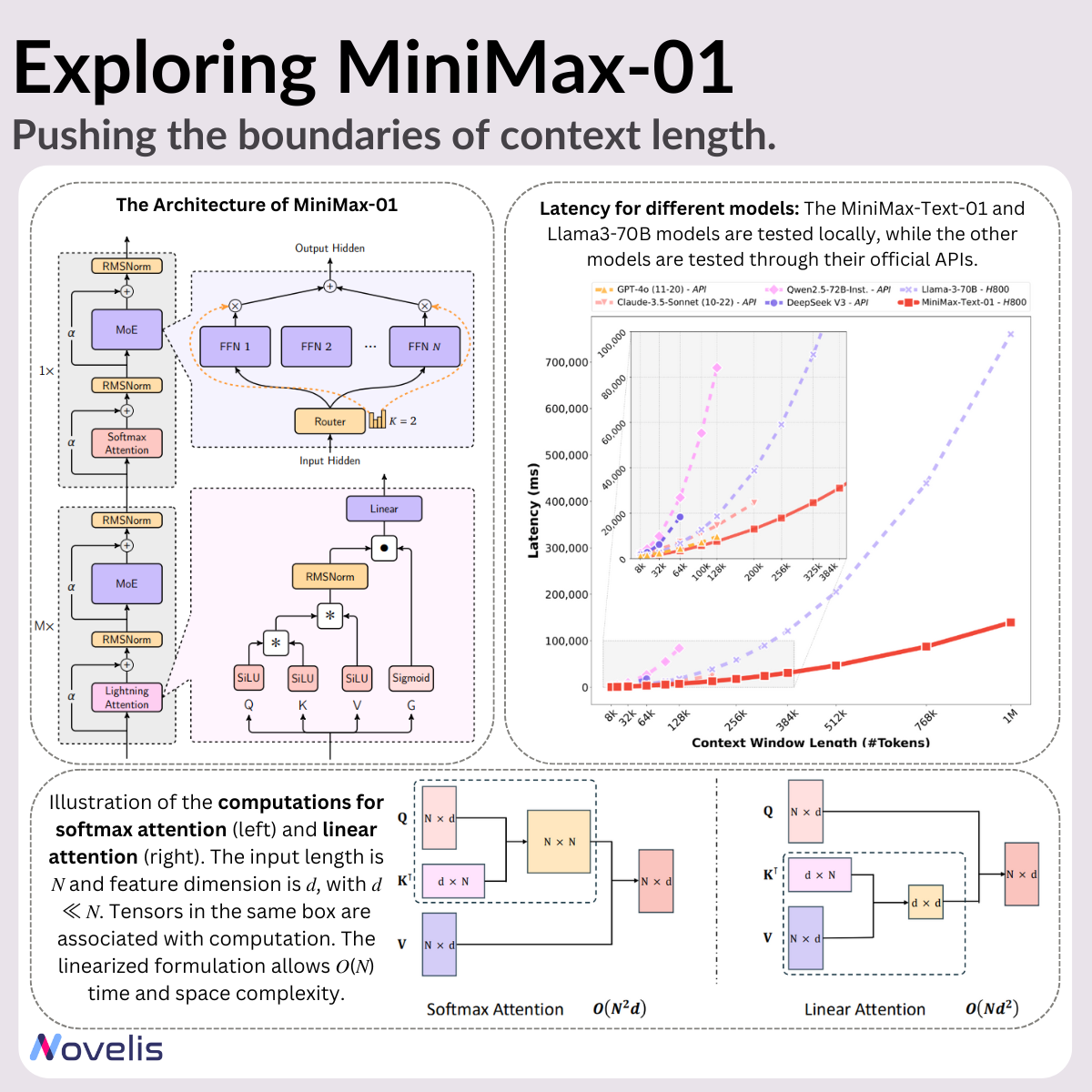
For LLMs (Large Language Models), the ability to handle large contexts is essential. MiniMax-01, a new series of models developed by MiniMax, presents significant improvements in both model scalability and computational efficiency, achieving context windows of up to 4 million tokens—20-32 times longer than most current LLMs.
Key innovations in MiniMax-01:
- Record-breaking context lengths:
- MiniMax-01 surpasses the performance of models like GPT-4 and Claude-3.5-Sonnet, allowing for context lengths of up to 4 million tokens. This enables the model to process entire documents, reports, or multi-chapter books in one single inference step, without the need to chunk documents.
- Lightning Attention and Mixture of Experts:
- Lightning Attention: A linear-complexity attention mechanism designed for efficient sequence processing.
- Mixture of Experts: A framework with 456 billion parameters distributed across 32 experts. Only 45.9 billion parameters are activated per token, to ensure minimal computational overhead while maintaining high performance.
- Efficient Training and Inference:
- MiniMax-01 utilizes a few parallelism strategies to optimize GPU usage and reduce communication overhead:
- Expert Parallel and Tensor Parallel Techniques to optimize training efficiency.
- Multi-level Padding and Sequence Parallelism to increase GPU utilization to 75%.
MiniMax-VL-01: Also a Vision-Language Model
In addition to MiniMax-Text-01, MiniMax has extended the same innovations into multimodal tasks with MiniMax-VL-01. Trained on 512 billion vision-language tokens, this model can efficiently process both text and visual data, making it also suitable for tasks like image captioning, image-based reasoning, and multimodal understanding.
Practical Applications:
The ability to handle 4 million tokens unlocks potential across various sectors:
- Legal and Financial Analysis: Process complete legal cases or financial reports in a single pass.
- Scientific Research: Analyze large research datasets or summarize years of studies.
- Creative Writing: Generate long-form narratives with complex story arcs.
- Multimodal Applications: Enhance tasks requiring both text and image integration.
MiniMax has made MiniMax-01 publicly available through Hugging Face.
🔗 Explore MiniMax-01 on Hugging Face