Nov 27 , 2024 read
Despite the impressive capabilities of LLMs, they can sometimes confidently generate inaccurate information. This is known as “hallucination” and it is a key challenge in Generative AI. This issue is even more pronounced in relation to numerical and statistical facts. Indeed, statistical data introduces unique challenges :
- First, pretraining with user queries pertaining to statistical information involves a variety of logical, arithmetic, or comparison operations with varying degrees of complexity.
- Second, public statistical data exists in diverse formats and schemas, frequently necessitating significant contextual background for accurate interpretation. This creates particular difficulties for RAG-based systems.
DataGemma: An Innovative Solution
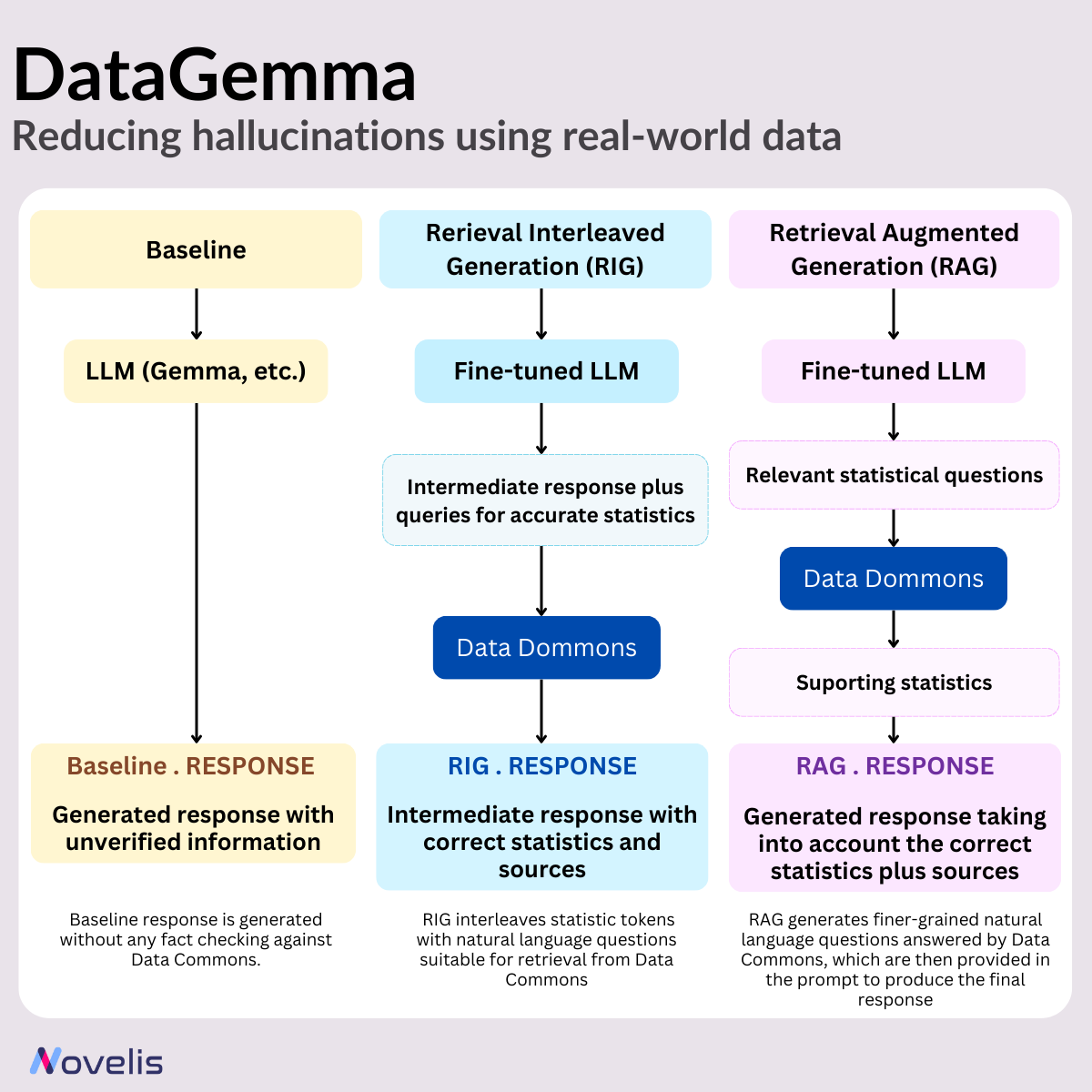
Researchers at Google present DataGemma, the interfacing LLMs that harness the knowledge of Data Commons — a vast unified repository of public statistical data — to tackle the challenges mentioned earlier. Furthermore, two different approaches are employed : Retrieval Interleaved Generation (RIG) and Retrieval Augmented Generation (RAG). The team utilizes Google’s open-source Gemma and Gemma-2 models to develop fine-tuned versions tailored for both RIG and RAG.
Key Features of DataGemma
1. Data Commons is one of the largest unified repositories of public statistical data. It contains more than 240 billion data points across hundreds of thousands of statistical variables. The data is sourced from trusted organizations like the World Health Organization (WHO), the United Nations (UN), Centers for Disease Control and Prevention (CDC) and Census Bureaus.
2. RIG (Retrieval-Interleaved Generation) improves the capabilities of Gemma 2 by actively querying reliable sources and using information in Data Commons for fact-checking. When we ask DataGemma to generate a response, the model first identifies instances of statistical data and then retrieves the answer from Data Commons. Although the RIG methodology itself is well-established, the novelty lies in its use within the DataGemma framework.
3. RAG (Retrieval-Augmented Generation) allows language models to access relevant external information in addition to the training data, providing them with richer context and enabling more detailed, accurate responses. DataGemma implements this by utilizing Gemini 1.5 Pro’s extended context window. Before generating a response, DataGemma retrieves relevant information from Data Commons, reducing the likelihood of hallucinations and improving response accuracy.
Promising results
The initial results from using RIG and RAG are promising, though still in the early stages. The reseachers report significant improvements in the language models’ ability to manage numerical data, indicating that users are likely to encounter fewer hallucinations when applying the models for research, decision-making, or general inquiries.