At Novelis, we are committed to using new technologies as tools to better respond to our customers' operational challenges and thus better support them in their transformation. That's why we have an ambitious R&D laboratory, with substantial investments: 26% of revenues are invested in research.
To keep you up to date with the latest scientific news, we've created a LinkedIn page dedicated to our Lab, called Novelis Research, check it out!
Let's recap all Novelis Research articles from November. This month, our team was pleased to share with you the latest news about the various existing technologies in the field of language modeling, with a focus on LLM. Here are the posts we shared with you:
StreamingLLM : enable LLM to respond in real time
🤖 StreamingLLM: Breaking The Short Context Curse ✂️
Have you ever had a lengthy conversation with a chatbot (such as ChatGPT), only to realize that it has lost track of previous discussions or is no longer fluent? Or you've faced a situation where the input limit has been exhausted when using language model providers' APIs. The main challenge with large language models (LLMs) is the context length limitation, which prevents us from having prolonged interactions with them and utilizing their full potential.
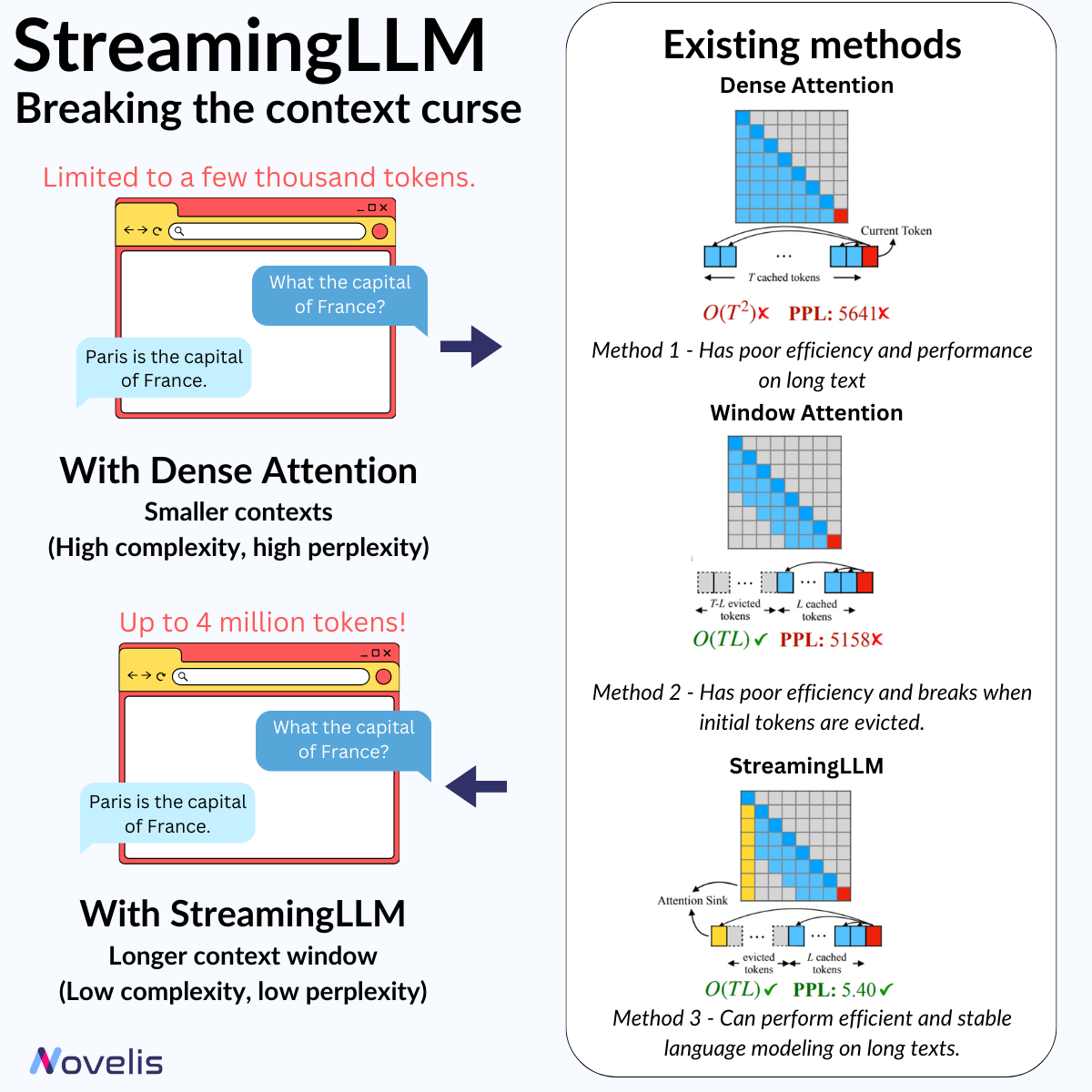
Researchers from the Massachusetts Institute of Technology, Meta AI, and Carnegie Mellon University have released a paper titled "Efficient Streaming Language Models With Attention Sinks". The paper introduces a new technique for increasing the input lengths of LLMs without any loss in efficiency or performance degradation, all without model retraining.
The StreamingLLM framework stores the initial four tokens (called "sinks") in a KV Cache as an "Attention Sink" on the already pre-trained models like LLaMA, Mistral, Falcon, etc. These crucial tokens effectively address the performance challenges associated with conventional "Window Attention" in LLMs, allowing them to extend their capabilities beyond their original input length and cache size limits. Using the StreamingLLM framework can help reduce both the perplexity (which measures how well a model predicts the next word based on context) and the computational complexity of the model.
🎯Why is this important? 🎯This technique expands current LLMs to model sequences of over 4 million tokens without retraining while minimizing latency and memory footprint compared to previous methods.
RLHF : adapt AI models with human input
🤖Unlocking the Power of Reinforcement Learning from Human Feedback for Natural Language Processing📖
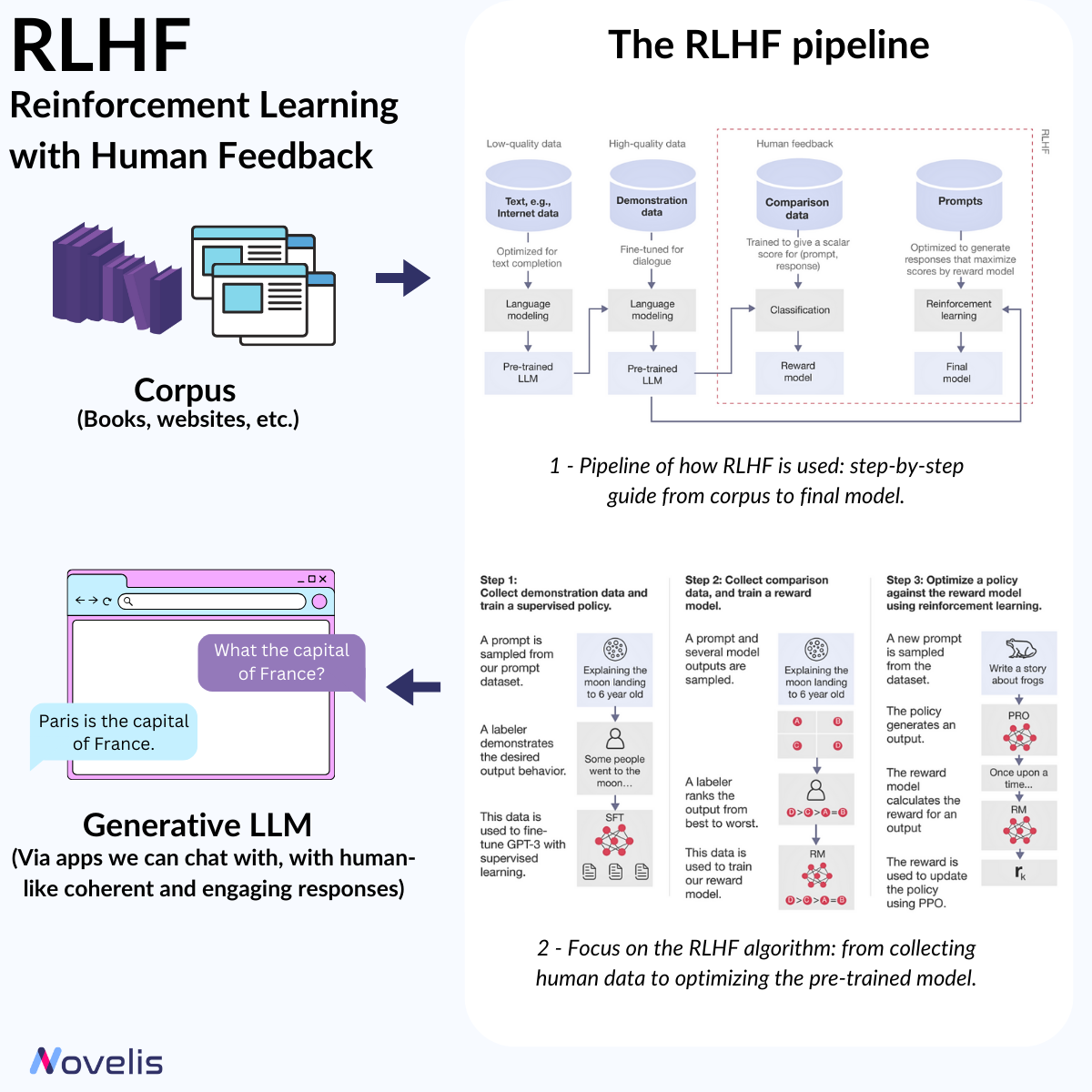
Reinforcement Learning from Human Feedback (RLHF) is a significant breakthrough in Natural Language Processing (NLP). It allows machine learning models to be refined using human intuition, leading to more contextually aware AI systems. RLHF is a machine learning method that adapt AI models (here, LLMs) using human input. The process involves creating a "reward model" based on human feedback, which is then used to optimize the behavior of an AI agent through reinforcement learning algorithms. Simply put, RLHF helps machines learn and improve by using the insights of human evaluators. For instance, an AI model can be trained to generate compelling summaries or engage in meaningful conversations using RLHF. The technique collects human feedback, often in the form of rankings or preferences, to create a reward model. This model helps the AI agent distinguish between good and bad outcomes and subsequently undergoes fine-tuning to align its behavior with the preferences identified in the human feedback. The result is more accurate, nuanced, and contextually appropriate responses.
OpenAI's ChatGPT is a prime example of RLHF's implementation in natural language processing applications.
🎯 Why is this essential? 🎯 A clear understanding of RLHF is crucial to understanding the evolution of NLP and LLM and how they offer coherent, engaging, and easy-to-understand responses. RLHF helps AI models align with human values, providing answers that align with our preferences.
RAG : combine LLMs with external databases
🤖The Surprisingly Simple Efficiency of Retrieval Augmented Generation (RAG)📖
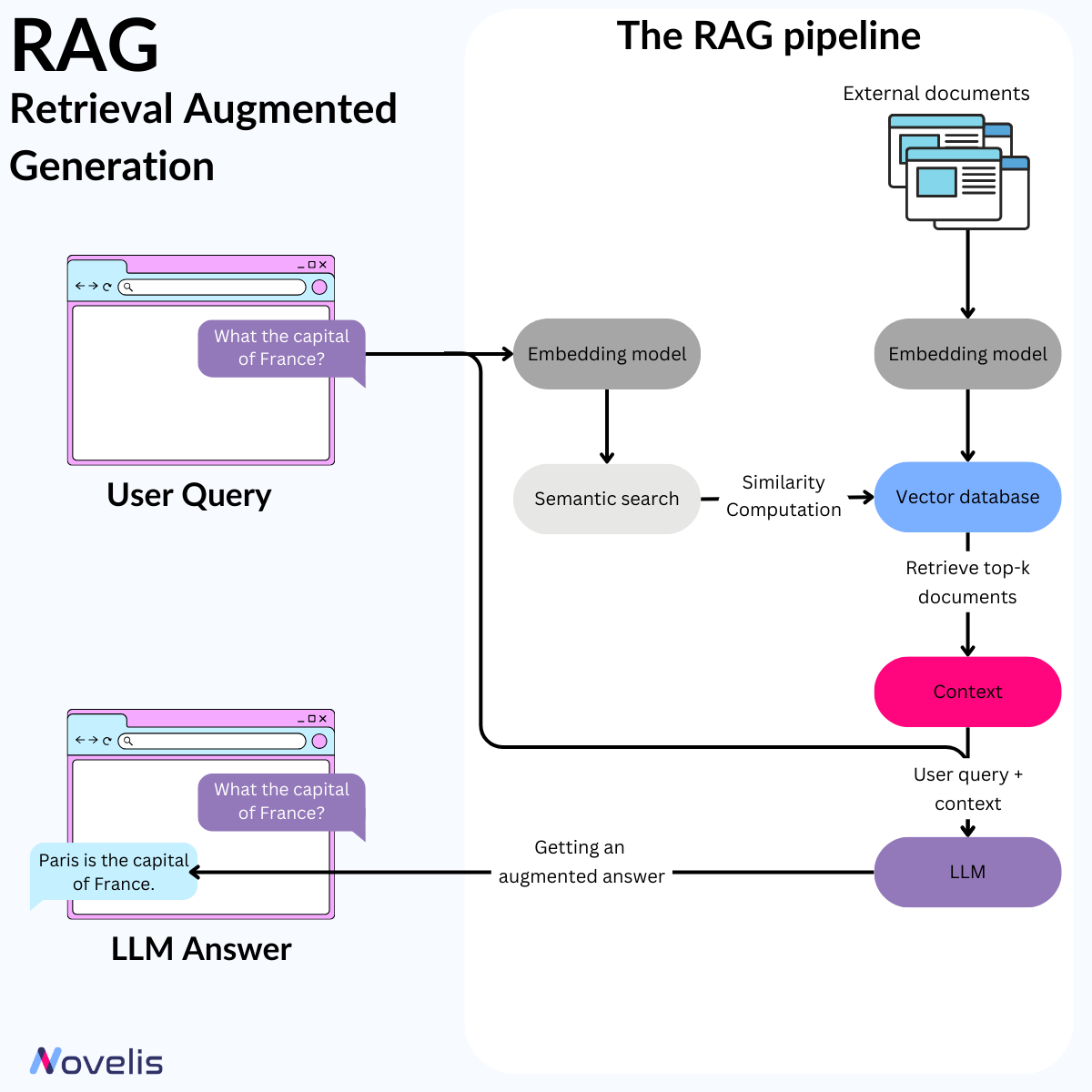
Artificial intelligence is evolving rapidly, with large language models (LLMs) like GPT-4, Mistral, Llama, and Zephyr setting new standards. Although these models have improved interactions between humans and machines, they are still limited by existing knowledge. In September 2020, Meta AI introduced an AI framework called Retrieval Augmented Generation (RAG), which resolves some issues previously encountered by LMs and LLMs. RAG is designed to enhance the quality of responses generated by LLMs by incorporating external sources of knowledge and enriching the LLMs' internal databases with accurate and up-to-date information. RAG is an AI system that combines LLMs with external databases to provide accurate and up-to-date answers to queries.
✨RAG has undergone continual refinement and integration with diverse language models, including the state-of-the-art GPT-4 and Llama 2.
🎯Why is this essential? 🎯Reliance on potentially outdated data and a predisposition to generate inaccurate or misleading information are common issues faced by LLMs. However, RAG effectively addresses these problems by ensuring factual accuracy and consistency. It significantly mitigates the risks associated with data integrity breaches and dissemination of erroneous information. Moreover, RAG has displayed prowess across diverse benchmarks such as Natural Questions, WebQuestions, and CuratedTrec. This exemplifies its robustness and reliability. By integrating RAG, the need for frequent model retraining is reduced. This, in turn, reduces the computational and financial resources required to maintain LLMs.
CoT : design the best prompts to produce the best results
🤖 Chain-of-Thought: Can large language models reason? 📖
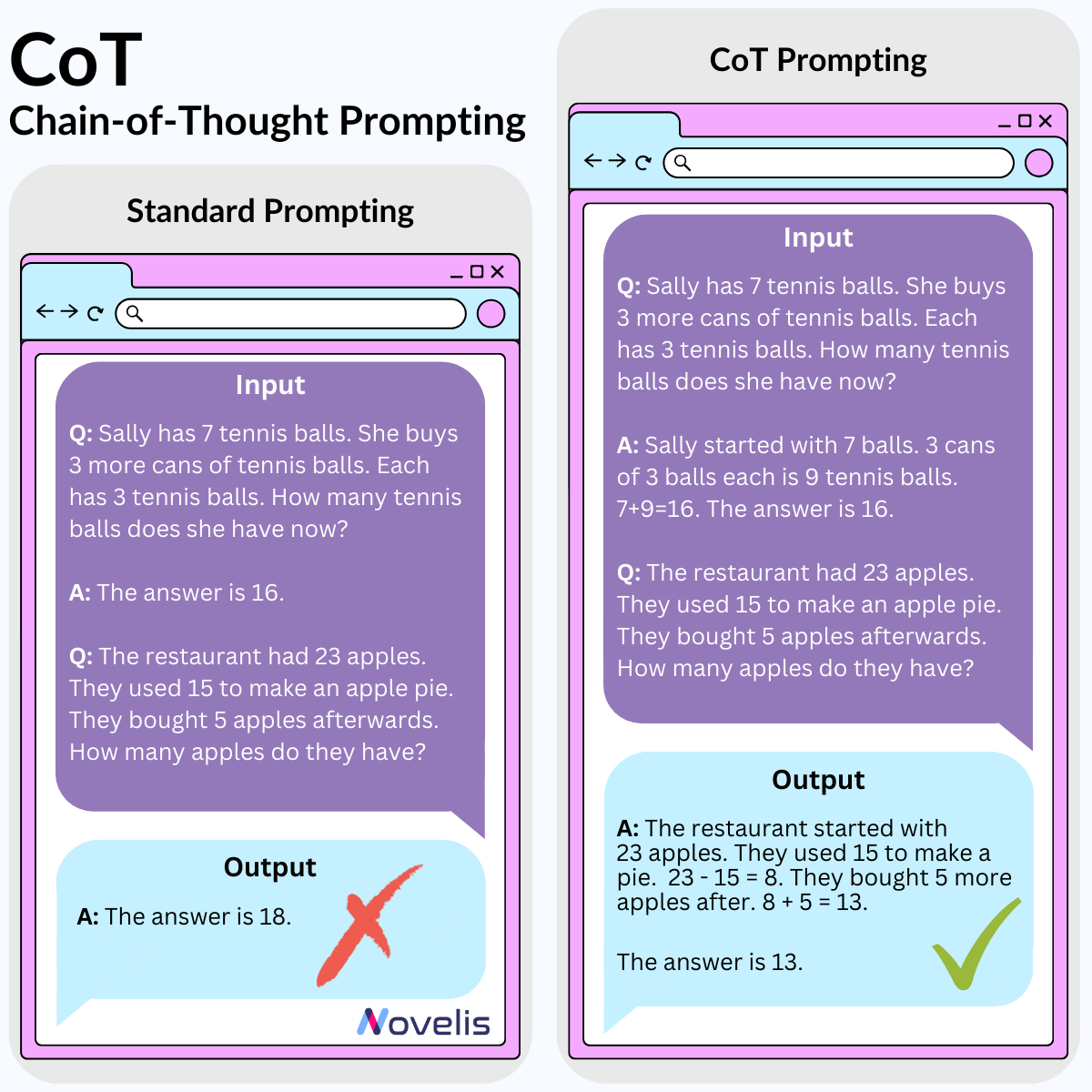
This month, we’ve been diving into the fascinating world of language modeling and generative AI. Today, we’ll be discussing on how to better use these LLMs. Ever heard of prompt engineering? This is the field of research dedicated to the design of better prompts in order for the large language model (LLM) you’re using to return the very best results. We’ll be introducing one such prompt engineering technique: Chain-of-Thought (CoT).
CoT prompting is a simple method that very closely resembles the way in which humans go about solving complex problems. If a problem seems a little long or a little too complex, we often tend to break that problem down into smaller sub-problems that we can more easily reason about. Well turns out this method works pretty well when replicated within (really) large language models (like GPT, BARD, PaLM, etc.). Give the model a couple examples of similar problems, explain how you’d handle them in plain language and that’s all! This works great for arithmetic problems, commonsense, and symbolic reasoning (aka good ol’ fashioned AI like rule-based problem solving).
🎯 Why is this essential? 🎯 Applying CoT prompting has the potential to produce better results when handling arithmetic, commonsense, or rule-based problems when using your LLM of choice. It also helps to figure out where your LLM might be going wrong when trying to solve a problem (though the why of this question remains unknown). Try it out yourself!
Now does this prove that our LLMs can really reason? That remains the million-dollar question.
Stay tuned for more exciting news in the coming month!
