At Novelis, we are committed to using new technologies as tools to better respond to our customers' operational challenges and thus better support them in their transformation. That's why we have an ambitious R&D laboratory, with substantial investments: 26% of revenues are invested in research.
To keep you up to date with the latest scientific news, we've created a LinkedIn page dedicated to our Lab, called Novelis Research, check it out!
Let's review all our Novelis Research articles for October. This month was dedicated to linguistic modeling technologies, and LLMs in particular. In two informative articles, our team of experts shared with you the existing technologies. Here are the messages we shared with you:
🤖Language Modelling and Generative AI📖
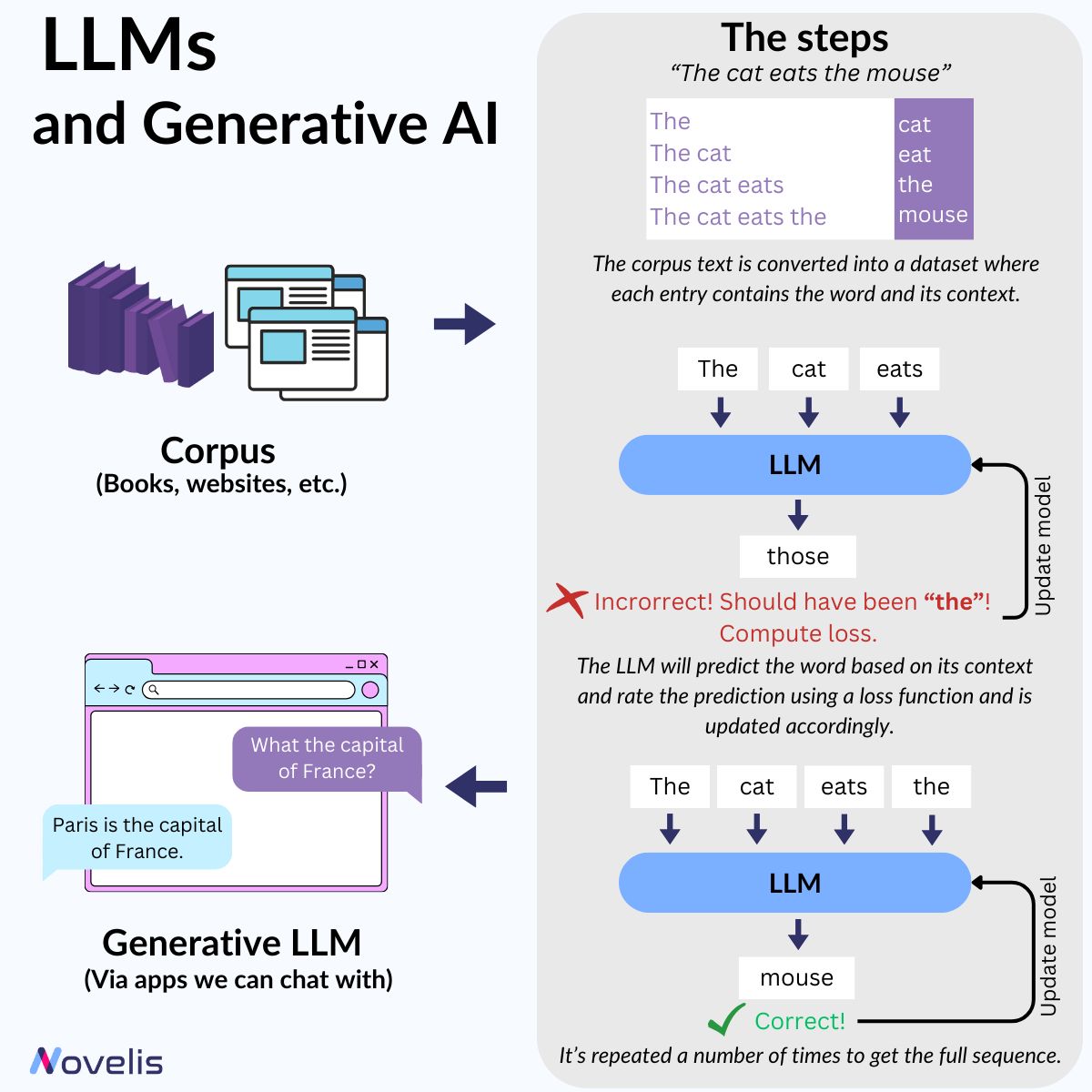
This month's focus is on language modeling, an innovative AI technology that has emerged in the field of artificial intelligence, transforming industries, communication, and information retrieval. Using machine learning methods, language modeling creates language models (LMs) to help computers understand human language, and it powers virtual assistants and applications like ChatGPT. Let's take a closer look at how it works.
For computers to understand written language, LMs transform it into numerical representations. Current LMs analyze large text datasets, and, using statistical and probabilistic techniques, they use
the likelihood of a word appearing in a sentence to create the words' vector representations. LMs are trained through pretraining tasks. Such a task could involve predicting a word based on its context
(i.e., its preceding or following words). In the sentences "X is a small feline" and "The X ate the mouse", the model would have to figure out that the X refers to the word "cat".
Once these representations are created, they can be used for different tasks and applications. One of these applications is language generation. The procedure for generating language using a language model is the following: 1) given the context, generate a probability distribution for the next token over all the tokens in the vocabulary; 2) pick the token with the highest probability; 3) add this token to the sequence, and repeat. A function that computes the performance loss of the model checks for correct responses and updates the model accordingly.
🎯Why is this essential? 🎯 All generative AI models, like ChatGPT, use these methods as the core foundation for their language generation abilities.
✨ New models LLM models are being released every other day. Some of the most well-known models are the proprietary GPT (3.5 and 4) models, while others, such as LLaMa and Falcon, are open-source. Recently, Mistral released a new model made in France, showing promising results.
Optimization of large models : improve model efficiency, accuracy and speed
🤖Unlocking LLM Potential: Optimizing Techniques for Seamless Corporate Deployment✂️
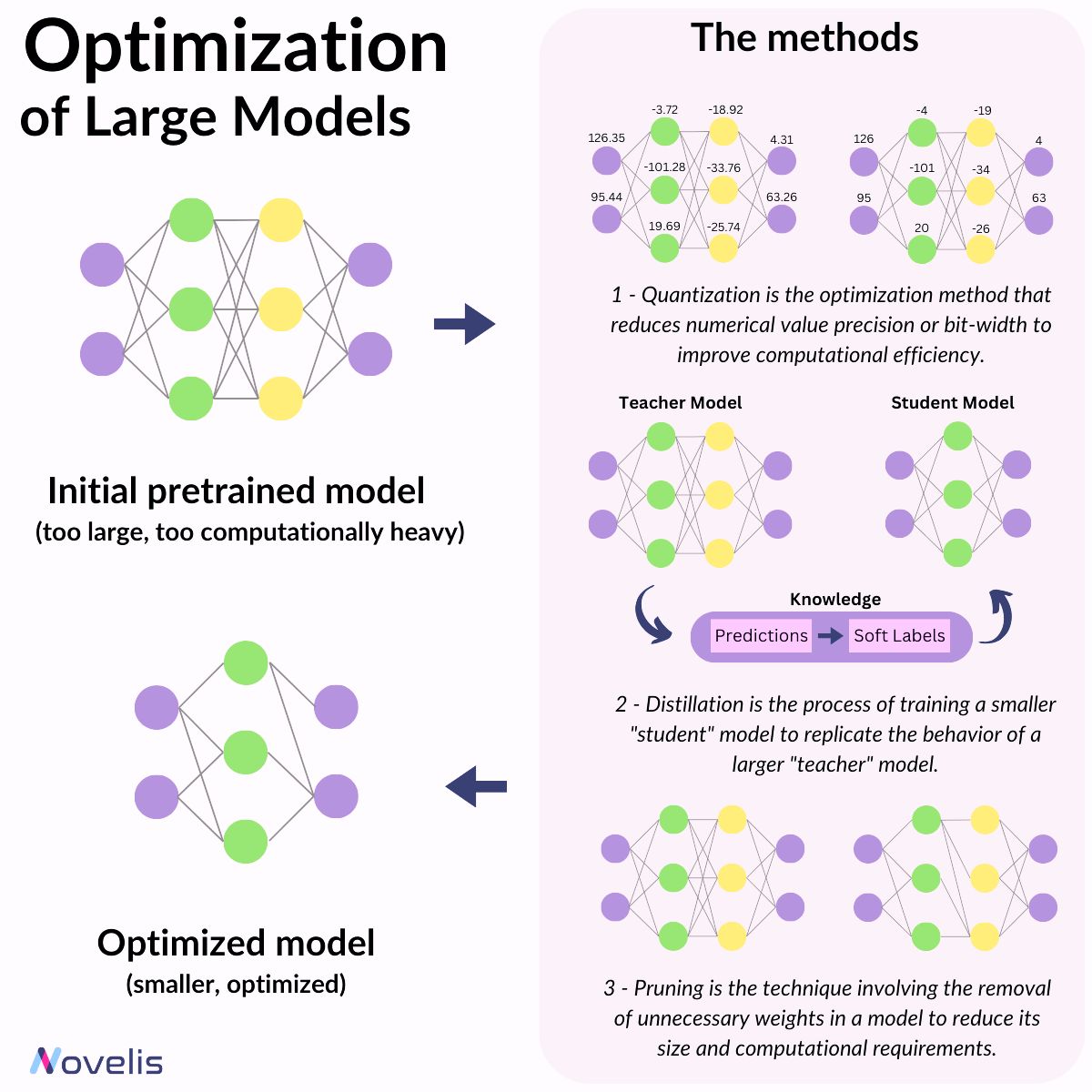
Large Language Models (LLMs) have millions or billions of parameters. Consequently, deploying them for use in corporate tasks is a challenging task, given the limitation of resources within companies.
Therefore, researchers have been striving to achieve comparable or competitive performance from smaller models compared to their larger counterparts. Let’s take a look at these methods and how they can be used for optimizing the deployment of LLM in a corporate setting.
The initial method is called distillation. In distillation, we have two models: the student and the teacher. The student model is trained to replicate the statistical behavior of the teacher model, either focusing on the final predictions or the hidden layers of the model. The second approach, called quantization, involves reducing the precision or bit-width of numerical values, optimizing computational efficiency and memory usage. Lastly, pruning entails the removal of unnecessary or less critical connections, weights, or neurons to reduce the model's size and computational requirements. The most well-known pruning technique is LoRA, a method crucial for achieving efficient and compact large language models.
🎯Why is this essential?🎯 Leveraging smaller models to achieve comparable or superior performance compared to their larger counterparts offers a promising solution for companies striving to develop cutting-edge technology with limited resources.
Stay tuned for more exciting news in the coming month!
